Introduction
Hash table looks like a regular array that is indexed with any data type (for example, string) rather than with an integer number.
Structure
The range of permissible values in PostgreSQL data types is typically quite large. For instance, when considering a column of type "text," there is a vast potential for different strings that can be envisioned. However, in practice, the number of distinct values actually stored in such a text column within a table is often relatively small.
The concept of hashing involves associating a numerical value within a specified range (from 0 to N−1, where N represents the total number of possible values) with any data type. This association is accomplished using a hash function. The resulting number can be utilized as an index in a regular array, where references to table rows (referred to as TIDs) are stored. Each element of this array is referred to as a hash table bucket, and in cases where the same indexed value appears in different rows, a single bucket can store multiple TIDs.
The more uniformly a hash function distributes source values by buckets, the better it is. But even a good hash function will sometimes produce equal results for different source values - this is called a collision. So, one bucket can store TIDs corresponding to different keys, and therefore, TIDs obtained from the index need to be rechecked.
Index structure
Let's return to hash index. For a value of some data type (an index key), our task is to quickly find the matching TID.
When inserting into the index, let's compute the hash function for the key. Hash functions in PostgreSQL always return the "integer" type, which is in range of 232 ≈ 4 billion values. The number of buckets initially equals two and dynamically increases to adjust to the data size. The bucket number can be computed from the hash code using the bit arithmetic. And this is the bucket where we will put our TID.
But this is insufficient since TIDs matching different keys can be put into the same bucket. What shall we do? It is possible to store the source value of the key in a bucket, in addition to the TID, but this would considerably increase the index size. To save space, instead of a key, the bucket stores the hash code of the key.
When searching through the index, we compute the hash function for the key and get the bucket number. Now it remains to go through the contents of the bucket and return only matching TIDs with appropriate hash codes. This is done efficiently since stored "hash code - TID" pairs are ordered.
However, two different keys may happen not only to get into one bucket, but also to have the same four-byte hash codes - no one has done away with the collision. Therefore, the access method asks the general indexing engine to verify each TID by rechecking the condition in the table row (the engine can do this along with the visibility check).
Mapping data structures to pages
From the standpoint of the buffer cache manager, an index is treated similarly to table pages. Regardless of query planning and execution, all information and index rows need to be compactly stored in pages. These index pages are kept in the buffer cache and are evicted from it using the same process as table pages.
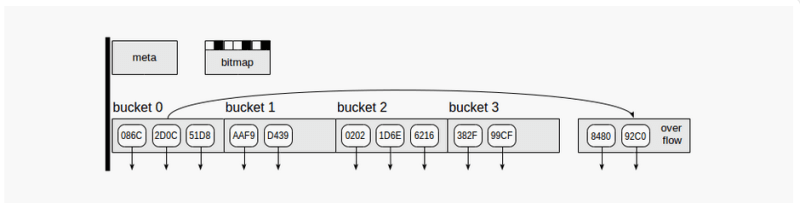
Hash index uses four kinds of pages (gray rectangles):
- Meta page - page number zero, which contains information on what is inside the index.
- Bucket pages - main pages of the index, which store data as "hash code - TID" pairs.
- Overflow pages - structured the same way as bucket pages and used when one page is insufficient for a bucket.
- Bitmap pages - which keep track of overflow pages that are currently clear and can be reused for other buckets.
Down arrows starting at index page elements represent TIDs, that is, references to table rows.
Each time the index increases, PostgreSQL instantaneously creates twice as many buckets (and therefore, pages) as were last created. To avoid allocation of this potentially large number of pages at once, version 10 made the size increase more smoothly. As for overflow pages, they are allocated just as the need arises and are tracked in bitmap pages, which are also allocated as the need arises.
Note that hash index cannot decrease in size. If we delete some of indexed rows, pages once allocated would not be returned to the operating system, but will only be reused for new data after VACUUMING. The only option to decrease the index size is to rebuild it from scratch using REINDEX or VACUUM FULL command.
Apache AGE
Apache AGE is graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL.
visit:

Top comments (0)