
limu is designed for modern browsers. It only considers the operating environment that supports Proxy and uses the mechanism of shallow copy on read and mark update on write. This allows users to operate variable data like original data. During the operation, only proxy objects are generated for the read nodes and returned to the user. After reading, the parent and child nodes are directly connected with shallow clone nodes. The proxy object is hidden in the meta data of the node. , after the operation is completed, a new data with structural sharing characteristics is generated, and the meta data generated during the reading process is removed.
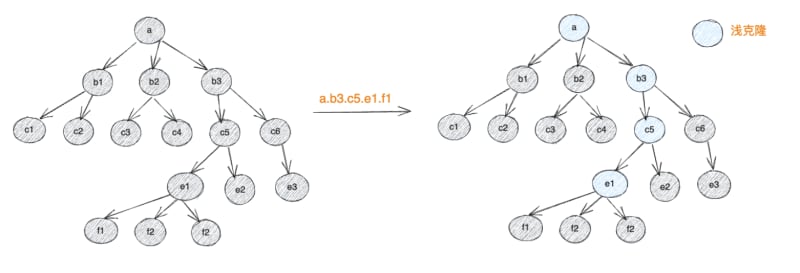
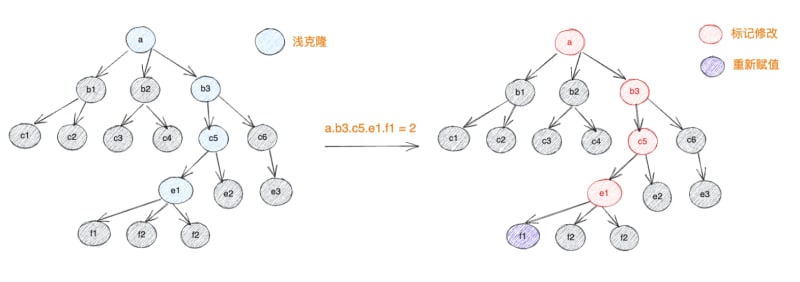
This design brings three major benefits:
Transparent data structure
limu is currently the only immutable operation library that can view the data structure of drafts in real time, and is debugging friendly.Excellent performance
Since the shallow cloning operation is done in advance, and only the read path is cloned and the path pointing between the parent and child nodes is changed, when ending the draft, you only need to judge whether themodifiedvariable is true or false to instantly complete the new copy generation action. In scenarios with large amounts of data and few reads, the performance exceeds that ofimmerby more than 20 times (the data before 3.12 was about4times)Simple code structure
Since only supportingProxyis considered, the code design has no historical baggage and can focus on core scenarios of immutable data such as data reading and writing, proxy generation, and frozen implementation, which is conducive to later upgrades and expansion of more features oriented to modern browser standards.
optimization process
Before 3.12, although the performance of limu was several times better than immer, it was far away from structura and mutative These new immutable data operation libraries still have many gaps, so they can only be debugged friendly and several times faster than immer as a promotional point. If you want to pursue the ultimate speed, it is recommended by default. mutative.
After 3.12, limu finally smoothed out these gaps. Let’s start to share the performance optimization process to see how limu cultivates and reaches the peak of performance.
Place meta
At the beginning of the article, we mentioned the point of meta data hiding. meta data records important information such as the proxy object of the current node, father, child, reachable path, data version number, etc. In order to prevent users from perceiving this data exists, and two attempts have been made.
symbol hides meta
Internally uses a symbol tag to store meta
const LIMU_META = symbol('LIMU_META');
const obj = { a: 1, b: { b1: 1 } };
// When reading obj.b, the object { b1: 1 } hides a meta
{ b1: 1, [LIMU_META]: { parent, path, version, modified ... } }
Then at the end of the operation draft, the levelScopes operation force needs to use the delete keyword to remove these redundant data. The inconvenience caused by this method is that when printing the data, you will see a very dazzling LIMU_META attribute in the object. , creating a psychological burden for users to pollute their data.
proto hides meta
In order to keep the data clean, in addition to continuing to use the symbol LIMU_META as a private attribute, this attribute is promoted to __proto__ and hidden. Then the problem arises. If __proto__ is directly operated, the prototype chain will be polluted.
var a = 1;
a.__proto__.meta = 1;
var b = 2;
console.log(b.__proto__.meta); // 1
a.__proto__.meta = 100;
console.log(b.__proto__.meta); // 100 ❌ The prototype chain has been contaminated
In order to bypass contamination, a separate prototype object is created for each object and mixed in the original prototype chain, as shown below:
before:
a.__proto points to Object.Prototype
after:
a.__proto points to Limu.Prototype, Limu.ProtoType points to Object.Prototype
// Each Limu.Prototype is a clean object generated by Object.create(null)
The simplified version of the code is implemented as follows
export function injectLimuMetaProto(rawObj) {
const pureObj = Object.create(null);
Object.setPrototypeOf(pureObj, Object.prototype);
Object.setPrototypeOf(rawObj, pureObj);
return rawObj;
}
This achieves the effect of using symbol to hide private attributes and using the reconstructed prototype chain to promote private attributes to the prototype chain without polluting the prototype chain.
Performance loss analysis
Although meta has been used to achieve the goal of generating structural shared data, the test results are still 4 to 5 times different from structura and mutative, which makes me believe that limu must still have huge room for improvement.
So I started to fine-tune the source code and run performance test scripts to find possible performance loss points.
Remove meta
When finishing the draft, we need to remove meta to avoid memory leaks. Then we will use the delete operator to disconnect the LIMU_META pointed to by the parent node. After I blocked this delete operation, the performance improved by 2 About times, then the key point becomes how to bypass the delete operation
function finishDraft(){
levelScopes()
}
function levelScopes()(
scopes.forEach((scope)=>{
// Comment out deletaMeta, performance improved by 2 times
// deletaMeta(scope);
});
)
Prototype chain reorganization
The injectLimuMetaProto mentioned above actually involves a process of prototype chain re-pointing, including two setPrototypeOf operations. This function is deliberately shielded and the lower part of meta is placed on the object. The performance is improved by about 4 times. It is found that setPrototypeOf of a large number of nodes actually causes a lot of performance loss.
injectLimuMetaProto(obj),
setMeta(obj, newMeta());
// Replace with the following writing method, performance improved by 4 times
obj[LIMU_META] = newMeta();
Customized optimization plan
After analyzing the performance loss points by constantly annotating the code and running the script, our goal is very clear. How to block the two major performance consumers of delete and setPrototypeOf, and also keep the data clean and meta can be obtained normally.
Finally, I came up with the new data structure Map of es6. When createDraft, a metaMap is generated for each draft, which is used to place the meta corresponding to the data. The pseudo code is as follows:
function getProxy(metaMap, dataNode){
const meta = !getMeta(dataNode);
if(!meta){
const copy = shallowCopy(dataNode);
const meta = newMeta(copy, dataNode);
// Use the shallow clone reference of the node itself as the key to store meta
metaMap[copy] = meta;
}
// Meta already exists, return the generated proxy object
return meta.proxyVal;
}
function createDraft(base){
const metaMap = new Map();
return new Proxy(base, {
get(parent, key){
const dataNode = parent[key];
return getProxy(metaMap, dataNode);
},
});
}
With this metaMap, there is no more setPrototypeOf behavior. At the same time, continue to operate this metaMap in the finishDraft step and cut off the relevant meta records. Compared with delete, map.delete More efficient, our data is stored in map, so we no longer need to deal with delete.
The pseudo code is as follows
function finishDraft(){
levelScopes();
}
function levelScopes(){
scopes.forEach((scope)=>{
// Comment out deletaMeta, performance improved by 2 times
// deletaMeta(scope);
});
}
So far, we have completed the purpose of completely blocking delete and setPrototypeOf. At the same time, the user's data is completely clean and transparent. Next, we enter the optimized performance testing process.
Performance Testing
We have placed the performance test-related code into benchmark. You only need to perform the following steps to experience the performance test performance of the latest version.
git clone git@github.com:tnfe/limu.git
cd limu
cd benchmark
npm i
Then execute the following four sets of commands and observe the printing results.
npm run s1 // Does not operate the draft array, the result is not frozen
npm run s2 // Manipulate the draft array, the result will not be frozen
npm run s3 // Does not operate the draft array, the result is frozen
npm run s4 //Operation draft array, the result is frozen
Test data design
In order to simulate complex data, our test data contains a dictionary of 20+keys.
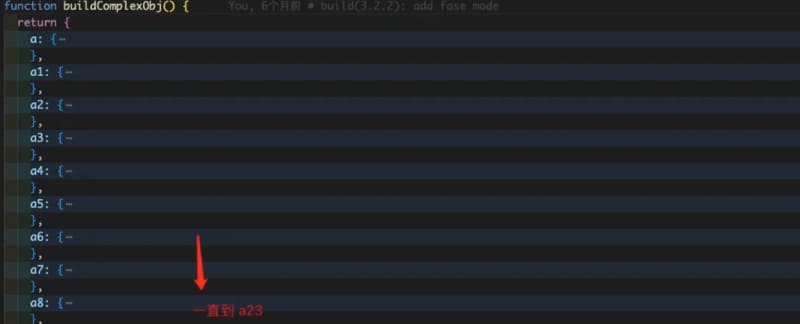
The data depth corresponding to the key is 26 layers
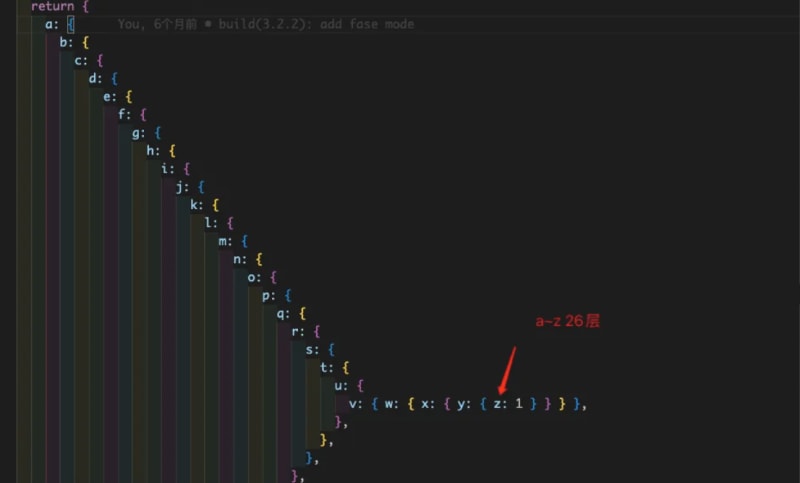
At the same time, an array of length 10000 will be generated.
Test role preparation
In addition to the four libraries immer, limu, mutative, and structura, the test role also adds pstr and native
pstr uses JSON.parse and JSON.stringify to simulate immer’s produce
// code of pstr
exports.createDraft = function (obj) {
return JSON.parse(JSON.stringify(obj));
};
exports.finishDraft = function (obj) {
return obj;
};
exports.produce = function (obj, cb) {
cb(exports.createDraft(obj));
};
native does nothing but manipulates native objects.
exports.createDraft = function (obj) {
return obj;
};
exports.finishDraft = function (obj) {
return obj;
};
exports.produce = function (obj, cb) {
cb(exports.createDraft(obj));
};
The purpose of adding pstr and native is to compare the performance difference between immutable operation efficiency and hard cloning JSON.parse(JSON.stringify(obj)) and the original operation.
Test code writing
In order to test the reading and writing of complex data, multiple deep-level reading and writing operations will be performed, and operateArr will be added to control whether it is convenient for array operations. Part of the suggestion code as follows:
runPerfCase({
loopLimit: 1000,
arrLen: 10000,
userBenchmark: (params) => {
const { lib, base, operateArr, moreDeepOp } = params;
const final = lib.produce(base, (draft) => {
draft.k1.k1_1 = 20;
if (moreDeepOp) {
draft.a.b.c.d.e.f.g.h.i.j.k.l.m.n.o.p.q.r.s.t.u.v.w.x.y.z = 666;
draft.a1.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a2.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a3.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a4.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a5.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a6.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a7.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
}
if (operateArr) {
draft.arr[draft.arr.length - 1].a = 888;
// draft.arr.forEach((item, idx) => { // bad way
lib.original(draft.arr).forEach((item, idx) => { // good way
if (idx === 100) {
draft.arr[1].a = 888;
}
});
}
});
if (base === final) {
die('base === final', lib);
}
},
}).catch(console.error);
Each character will be warmed up before officially starting to execute, and then start 1000 traversals. At the end of each traversal, a time is obtained. The final time consumption is summed and divided by 1000 to get the average time consumption of each traversal. Part of Schematic code is as follows:
function oneBenchmark(libName, options) {
const { userBenchmark, arrLen } = options;
let lib = immutLibs[libName]; // Get different immutable libraries
const base = getBase(arrLen);
const start = Date.now();
try {
//Execute user-written performance test cases
userBenchmark({
libName,
lib,
base,
operateArr: OP_ARR,
moreDeepOp: MORE_DEEP_OP,
});
const taskSpend = Date.now() - start;
return taskSpend;
} catch (err) {
console.log(`${libName} throw err`);
throw err;
}
}
function measureBenchmark(libName, options) {
const loopLimit = options.loopLimit || LOOP_LIMIT;
let totalSpend = 0;
const runForLoop = (limit) => {
for (let i = 0; i < limit; i++) {
totalSpend += oneBenchmark(libName, options);
}
};
// preheat
oneBenchmark(libName, options);
runForLoop(loopLimit);
console.log(`loop: ${loopLimit}, ${libName} avg spend ${totalSpend / loopLimit} ms`);
}
Test result display
My machine is macbook pro 2021, M1 chip, 32GB memory.
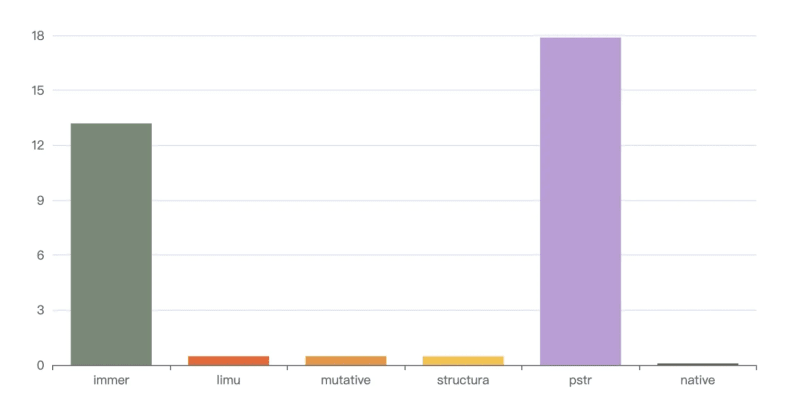
Executing npm run s1 means that the draft array will not be operated and the result will not be frozen. The result is as follows
loop: 1000, immer avg spend 13.19 ms
loop: 1000, limu avg spend 0.488 ms
loop: 1000, mutative avg spend 0.477 ms
loop: 1000, structura avg spend 0.466 ms
loop: 1000, pstr avg spend 17.877 ms
loop: 1000, native avg spend 0.084 ms
The visualization result is (unit ms, the lower the column, the better the performance)
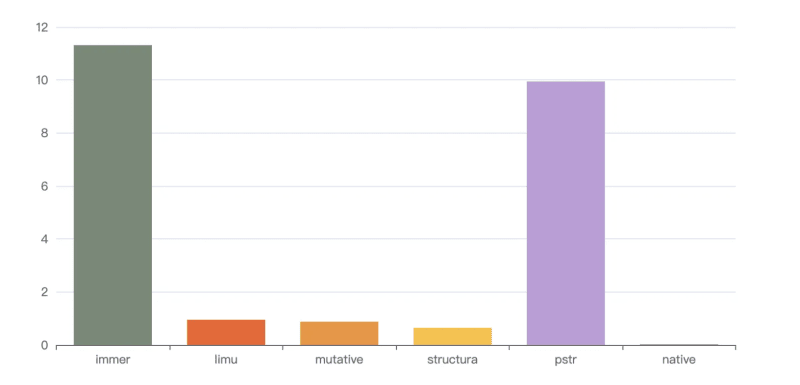
Executing npm run s2 means operating the draft array and the result is not frozen. The result is as follows
loop: 1000, immer avg spend 11.315 ms
loop: 1000, limu avg spend 0.95 ms
loop: 1000, mutative avg spend 0.877 ms
loop: 1000, structura avg spend 0.646 ms
loop: 1000, pstr avg spend 9.945 ms
loop: 1000, native avg spend 0.107 ms
Executing npm run s3 means that the draft array will not be operated and the result will be frozen. The result is as follows
loop: 1000, immer avg spend 18.931 ms
loop: 1000, limu avg spend 5.274 ms
loop: 1000, mutative avg spend 8.468 ms
loop: 1000, structura avg spend 17.328 ms
loop: 1000, pstr avg spend 10.449 ms
loop: 1000, native avg spend 0.02 ms
structura and immer perform worse than hard clone pstr in this scenario, limu performs best, and mutative comes second.
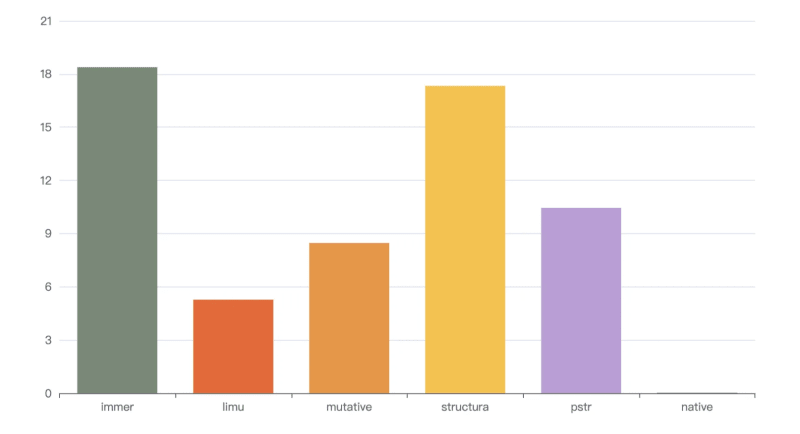
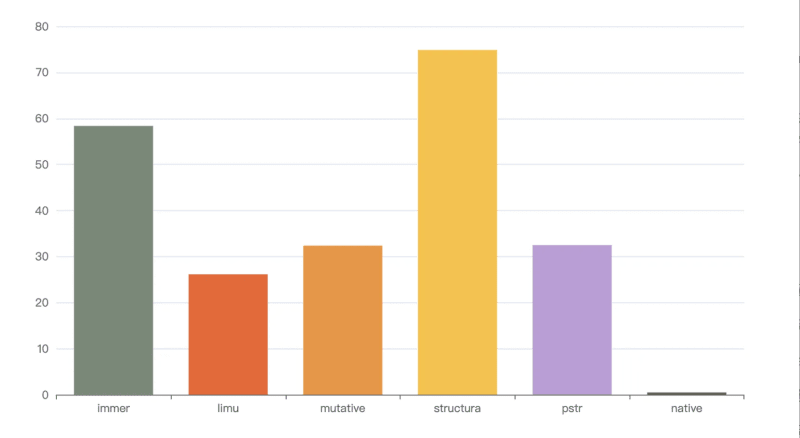
Executing npm run s4 means operating the draft array and the result is frozen. The result is as follows
loop: 1000, immer avg spend 58.359 ms
loop: 1000, limu avg spend 26.142 ms
loop: 1000, mutative avg spend 32.264 ms
loop: 1000, structura avg spend 74.851 ms
loop: 1000, pstr avg spend 32.481 ms
loop: 1000, native avg spend 0.481 ms
Due to the operation of an array of 10,000 lengths, the time is improved by 2 to 3 times compared to the previous group. structura and immer are still not as good as hard clone pstr in this scenario, limu performs best, and mutative performs best `The next best thing.
Test conclusion
After the above multiple rounds of testing, it is concluded that in the non-freezing scenario, the difference between limu, structura and mutative is not big, all between 10 times and 30 times.
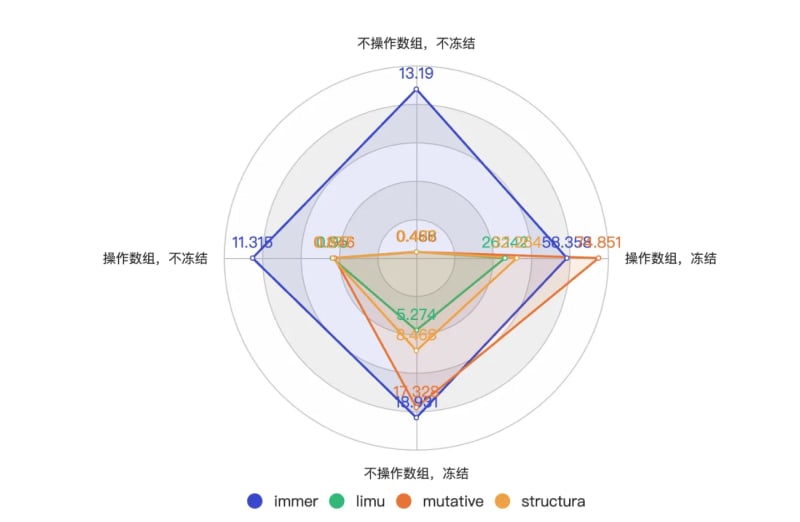
In the frozen scene, limu performs best, followed by mutative, and structura performs worse than immer. The performance is as follows when displayed as a radar chart.
Note: The smaller the area, the better the performance
Conclusion
After the above complete disclosure of optimization details and summary of test results, the performance test results of limu in various non-freezing scenarios are on par with structura and mutative, and are 1 to 2 ahead of structura and mutative in freezing scenarios. times, it can now be claimed that limu has reached the pinnacle of immutable data performance.
In addition to excellent performance, limu data can be viewed in real time. After deep expansion, it becomes json instead of Proxy. It is very friendly for debugging. If you have the ultimate pursuit of performance and do not consider compatibility with non-Proxy environments, limu It will be your best choice. It maintains the same API design as immer. If you do not use the applyPatches related API of immer, you can achieve seamless replacement.
one more thing
helux based on limu will be announced soon, hoping to redefine the react development paradigm and comprehensively improve react applications DX&UX (development experience, user experience), welcome to pay attention and understand in advance.

Friendly links:
❤️ Your little star is our biggest spiritual motivation for open source. Welcome to pay attention to the following projects:
limu The fastest immutable data js operation library.
hel-micro Toolchain-independent runtime module federation sdk.
helux A state engine that integrates atom, signal, and dependency tracking, and supports fine-grained response updates

Top comments (0)