引自:http://xianjing.github.io/2017/08/11/abilities/
如果你去买一部手机,你会考虑什么因素呢?一般我们都会首先考虑智能手机、照相功能、多大容量等。而除了这些,我们通常还会考虑品牌、颜色、外型好不好看、时尚与否。作为一个软件产品也不例外,用户首先会期望系统要满足正常的功能需求,同时系统还要满足好用、性能好、稳定可靠等其他特性。一般我们会把这些称为非功能性需求或者跨功能性需求。系统的每一次故障和宕机对用户都是不可忽视的损失,所以这些非功能性需求也是软件质量非常重要的属性,是软件架构设计需要满足的目标。
在运行时的非功能需求中,我们常常会提到几个词有 Availability、Stability 和 Reliability,即系统要高可用、高可靠和稳定。那么可用、可靠还有稳定是什么意思呢?如何衡量?它们之间又有什么区别?我经常在不同场景下听到这几个词的混用。今天就先来谈一谈这几个 ability。
1. Availability 可用性
Availability defines the proportion of time that the system is functional and working. It can be measured as a percentage of the total system downtime over a predefined period. Availability will be affected by system errors, infrastructure problems, malicious attacks, and system load. - Microsoft Application Architecture Guide
可用性指系统在给定时间内可以正常工作的概率,通常用 SLA 指标来表示,如下图所示。
SLA指标
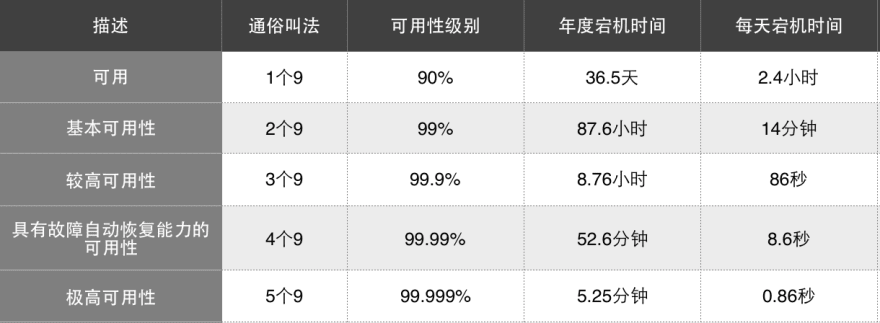
墨菲定律说 “会出错的事总会出错”,可用性做到 100 是可望而不可及的。对于 SLA 指标来说,9 的数字越多可用性越高,宕机时间越少,系统就可以在给定的时刻内高比例地正常工作。然而对系统的挑战就越大,投入的成本也会越高。 比如 5 个 9 要求系统每年只宕机 5 分钟左右,而 4 个 9 要求每年宕机时间不超过一个小时。这就使得系统需要在设计、基础设施、数据备份等不同层面采取多种方式,甚至增加基础设施投资来保证可用性。
“当你的设备处理人命关天的事情,或业务中断一分钟就会损失百万美刀,那么你可以考虑 99.99% 的可靠性。” Robertson(Linux 高可用项目开发者)
不同系统的可用性要求也是不同的,比如:淘宝、京东等这些电商系统用户量很多,不同区不同时刻都有大量的用户在使用系统,这必然对系统的可用性要求很高。据以往这些系统的故障统计和不准确地测试数据推测,它们目前的可用性是在 3 个 9 到 4 个 9 左右。相对而言,企业类的工作软件因为通常只在工作时间被使用,或只在某些特定的地区使用,或只给某部分人某一特定时间使用,可用性的需求就会低一些。典型的系统就数 salesforce 了,经常会看到 “周末又要升级了” 的提示。
影响可用性的因素有很多,包括系统故障、基础设施故障、数据故障、安全攻击、系统压力等等。
2. Reliability 可靠性
Reliability is a measure of the probability that an item will perform its intended function for a specified interval under stated conditions.
可靠性是在给定的时间间隔和给定条件下,系统可以无故障持续运行的概率。那么可靠性和可用性有什么区别呢?在《分布式系统原理与范型》中提到的下面例子中比较准确的解释了两者的区别:
如果系统在每小时崩溃 1ms,那么它的可用性就超过 99.9999%,但是它还是高度不可靠。与之类似,如果一个系统从来不崩溃,但是每年要停机两星期,那么它是高度可靠的,但是可用性只有 96%。
简而言之,可用性关注的是系统任何时刻可以持续正常工作的能力,关注的是服务总体的持续时间。系统在给定时间内总体的运行时间越长,可用性越高。而可靠性更关注系统可以无故障地持续运行的概率,关注的是故障率。故障的频率越高,可靠性越低。可靠性差一定程度上是会影响可用性的,但反过来不一定成立。
这里面还有一些常用的指标来衡量可用性和可靠性:
- MTBF(Mean Time Between Failure) 即平均无故障时间,是指从新的产品在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。MTBF 越长表示可靠性越高,正确工作能力越强 。
- MTTR(Mean Time To Repair) 即平均修复时间。是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。MTTR 越短表示易恢复性越好。
- MTTF(Mean Time To Failure) 即平均失效时间。系统平均能够正常运行多长时间,才发生一次故障。系统的可靠性越高,平均无故障时间越长。
基于以上指标,可用性可以如此计算:
Availability = UpTime/(UpTime+DownTime) = MTBF / (MTBF + MTTR)
作为系统的响应,首要目标是先降低故障的次数,频率要低,从而提高可靠性;同时在故障出现后,要提高故障的恢复时间,速度要快,从而提高业务的可用性。
影响可靠性的因素就是能够引起故障的所有因素,包括软件设计错误,编码错误,硬件故障等等。
3. Stability 稳定性
Stability is about how many failures an application exhibits; whether that is manifested as unexpected or unintended behaviour, users receiving errors, or a catastrophic failure that brings a system down. The fewer failures that are observed the more stable an application is.
软件的稳定性,指软件在一个运行周期内、在一定的压力条件下,在持续操作时间内出错的概率,性能劣化趋势等等。如果一个系统的故障率很高,它一定是高度不可靠的,也一定是不稳定的。那么如何区分稳定性和可靠性呢?
对于电力系统而言,稳定性就是 “人民用电不要忽明忽暗忽快忽慢”,可靠性就是” 不要用着用着突然没有啦 “。- 知乎盛夏白日梦
如果一个系统的性能时好时坏,它一定是不稳定的,而不一定是不可靠的。稳定性更关注系统在给定条件下的响应是否一致,行为是否稳定。可靠是可用的前提,稳定是可靠的进一步提升。
今天在 Stackoverflow 看到这样一段代码来表示这两个的区别,甚为有趣:
Reliable but unstable:
add(a,b):
if randomInt mod 5 == 0:
throw exception
else
print a+b
Stable but unreliable:
add(a,b):
if randomInt mod 5 == 0:
print a+a
else
print a+b
不知道写到这里,你是否对可用性、可靠性和稳定性有了更清晰的了解了呢?有了这些指标可以帮助我们去分析系统存在的问题,比如说故障频率较高,故障恢复时间较长,那么系统的可靠性可用性一定很低,对用户的影响一定很高,就可以促使我们去从各个角度去改进和提高,去找架构设计的问题,去找系统实现的缺陷,去找依赖的基础设施问题等等,从而改善我们的系统。尤其是在当下复杂的分布式系统下,这些显得尤为重要。
那么,最后请问我们常见的容错处理、蓝绿部署、回滚、cluster、灾备会有助于提高以上哪个 ability 呢?

Top comments (0)