
<< Week 7: Linked Lists | View Solution on GitHub | Week 9: Blockchain >>

Some of my favorite Links. (Image: TV Tropes)
Welcome back to Whiteboarding in Python. Last week we talked about linked lists: what are they, how to make one in Python. You probably thought, "Great. But what is the actual point of doing this? Can't we just use a regular Python list?" Good question.
You see, so far we just made a linked list, but we haven't done anything with it. Forget about Python lists for a moment, and think about an array. In many object oriented languages like Java, arrays are fixed length. That means if you want to add or remove a space, you need to make a new one and move all the previous contents into it. It's like if you lived in a house with 3 bedrooms and suddenly you needed a 4th bedroom: you would have to pack up all your stuff and move into a new house with four bedrooms.
Now Python lists aren't true arrays, but implemented dynamic arrays, which have different performance from both linked lists and arrays (more information here). But at least compared to the old arrays, Linked Lists make list manipulation much easier, because we don't have to make a whole new list just to add one node. We simply make a new node and change the pointers from the other nodes.
Let's look at a sample problem:
# Remove Dups: Write code to remove duplicates
# from an unsorted linked list.
First of all, we're going to need the Node class we wrote last week. Now we can make the linked list in question before we start manipulating it. Here's that code:
class Node:
def __init__(self, data):
self.next = None
self.data = data
def append(self, val):
end = Node(val)
n = self
while (n.next):
n = n.next
n.next = end
Let's start by defining the method to remove duplicates. It will take one parameter, the first node in the list. I'll call it front.
def remove_dups(front):
pass
Now let's try to imagine how we would solve this problem if it were a regular list. We would store a count of each value, and if we came accross the same value twice, we would remove it. You're probably thinking of using a dictionary, and if you know me, yep, I'll be using a default dicitonary.
To review, defaultdict is an object in Python collections that allows to set a default type for values in a dictionary. We can set it to bool so that if a key has no previous value, it will automatically set it to False. So, will import it and initialize our dictionary. I'll call it counted, since it represents whether or not we've seen each value before.
from collections import defaultdict
def remove_dups(front):
counted = defaultdict(bool)
Now, we have to make our iterator to traverse the list. You may remember this from last week, we make a separate node to point to each node in the list, "traversing" it, and this leaves the original list intact. Here's a helpful gif from GeeksForGeeks where a pointer traverses a linked list and removes the last node:
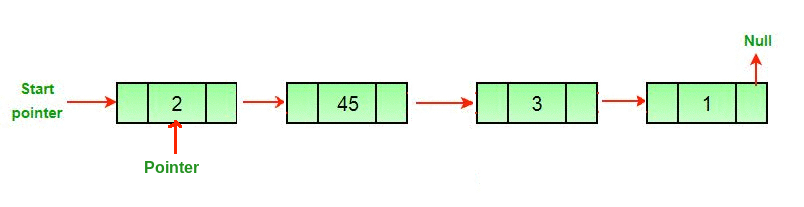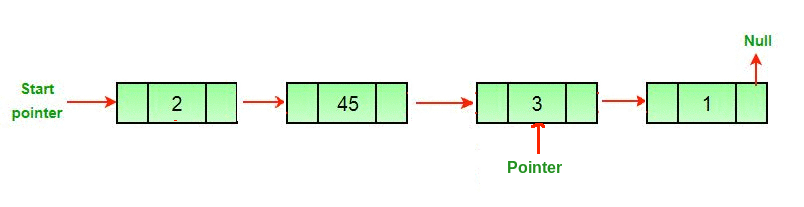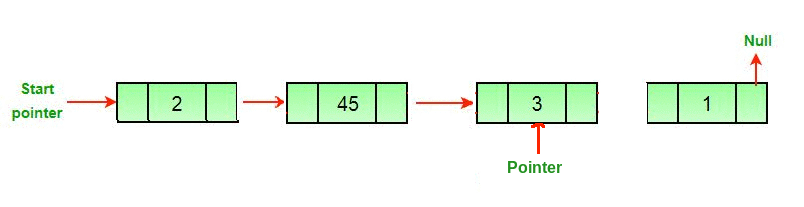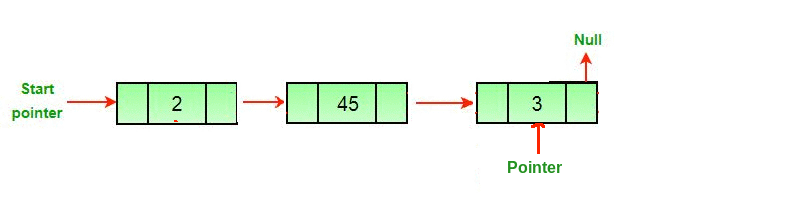
So, let's make our pointer. Traditionally, we might call it temp.
temp = front
Now, let's talk about traversing. We could check the value of the first node, then move onto the 2nd and check its value, and so on, but we'd have a problem. What if the node we were looking at had a duplicate value? We can only change its next pointer, not the pointer that goes before it. So, we'll look at the value of each next node, and if it happens to be a duplicate, we'll set temp.next to be None.
For example, let's say this is our list:
[1] --> [1] --> [2]
We start by putting the first node's value, 1, in our counted dictionary.
counted[temp.data] = True
Next, while still pointing to the first node, we look at the value of temp.next. Since this value is a duplicate, we want to remove the node. So we set temp.next to be the node after it, temp.next.next.
counted[temp.data] = True
while (temp.next):
# check the value of next Node
if (counted[temp.next.data]):
# if found in dictionary, remove it
temp.next = temp.next.next
If the value of temp.next is not True in counted, we want to set it to true. Then, we want to move onto the next node by setting temp to be temp.next.
counted[temp.data] = True
while (temp.next):
# check the value of next Node
if (counted[temp.next.data]):
#if found in dictionary, remove it
temp.next = temp.next.next
else:
counted[temp.next.data] = True
temp = temp.next
And that's it! Here is the full method:
from collections import defaultdict
def remove_dups(front):
counted = defaultdict(bool)
temp = front
counted[temp.data] = True
while (temp.next):
# check the value of next Node
if (counted[temp.next.data]):
#if found in dictionary, remove it
temp.next = temp.next.next
else:
counted[temp.next.data] = True
temp = temp.next
Testing our Method
Let's see if our method works. We'll start by making a linked list and appending some numbers to it.
ll = Node(1)
ll.append(2)
ll.append(3)
ll.append(3)
ll.append(1)
ll.append(4)
If you want to see the linked list, you'll have to traverse it and print each node. We went over this last week, but here is the code:
node = ll
print(node.data)
while node.next:
node = node.next
print(node.data)
This should print 1, 2, 3, 3, 1, 4. Now that we have our list built, let's call the method on it. You'll remember we past the front of the list, which happens to be ll.
remove_dups(ll)
If everything runs smoothly and you print the list again, the extra 1 and 3 should be removed to give 1, 2, 3, 4.
You might still be wondering why this is important to learn. Linked lists are kind of a holdover from traditional computer science. However, if you want to understand more complicated structures, such as binary trees, linked lists are a good stepping stone. And, if you can implement your own linked list, you can modify it to have custom methods to serve specific purposes. We'll look at this next week, when we use linked lists to implement a simple blockchain. You heard right! Blockchain is, in essence, a very complicated linked list. So maybe after next week, some of you will be able to make your own cryptocurrencies.
That's it for this week. Let me know if you like this content, and thanks to all of you who leave comments. It's been great to see the community getting involved, and that way we all learn more (myself included)!
<< Week 7: Linked Lists | View Solution on GitHub | Week 9: Blockchain >>
Sheamus Heikkila is formerly a Teaching Assistant at General Assembly Seattle. This blog is not associated with GA.





Top comments (0)