The sibling of security is reliability.
We are building an end-to-end encrypted photo storage service. In this post we describe how we ensure reliability by keeping 3 copies of customer's encrypted data, spread across 3 different cloud providers.
Threat model
Data loss due to machine failure is already covered even with a single good quality cloud provider, and we use three good quality ones. For example, one of our providers, Backblaze, provides a 11 nines durability with their actively monitored RAID arrays.
So we are already protected from data loss due to hard disk failure.
What then we want to protect against are more macro level threats. Specifically,
A cloud providers is unable to (or doesn't want to) provide us the data we've stored.
An attacker deletes the encrypted data because of a credential breach.
Protecting against denial of service by a cloud provider
The first of these threats is easy to mitigate - keep copies of the data in multiple clouds! The tradeoff here is cost: each copy we keep costs us 1x more.
Another factor here is availability during disaster recovery, i.e. the time to failover in case our primary storage is unavailable. Initially we had started with 2 providers - a hot storage and a ultra-long-term cold storage - but soon we realized that data recovery from the cold storage is going to take weeks. This is fine in case of absolute disaster, but isn't good enough for more mundane interruptions.
Finally, we also wish to store the data within EU, but that limits our geographical redundancy. So to protect against a widespread nuclear disaster or other act of god scenarios that affects large chunks of Europe, we picked a cold storage that is built with such threats in mind.
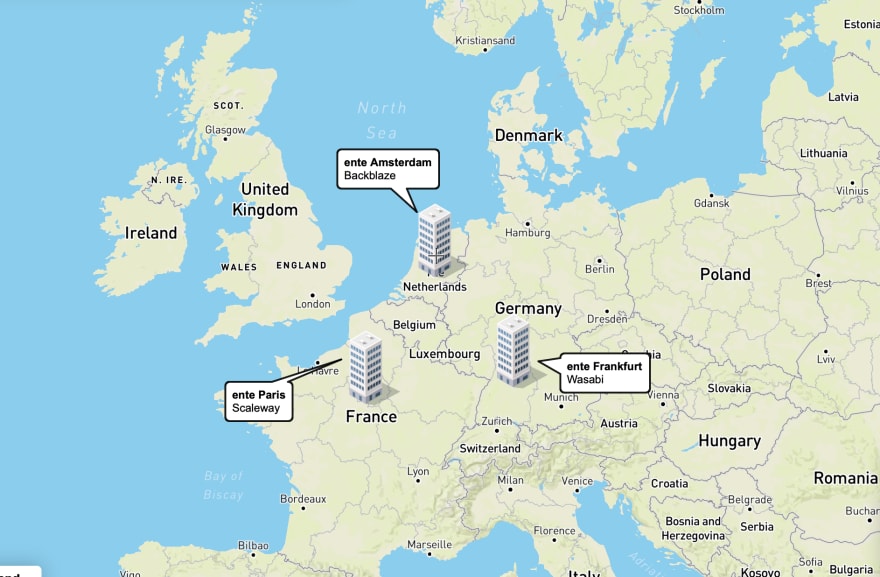
Given all these factors, our current basket of replicas contains the following 3 (2 hot, 1 cold) copies:
Backblaze, Amsterdam. Our primary hot storage. The data is stored in Backblaze's EU central region, the datacenter for which is in Amsterdam, Netherlands.
Wasabi, Frankfurt. Our secondary hot storage. The data is stored in Wasabi's EU central region, the datacenter for which is in Frankfurt, Germany.
Scaleway, Paris. Our cold storage. The data is stored in a refurbished nuclear fallout shelter 25 meters below Paris.
Protecting against accidental / malicious deletion of data
We want to ensure that there is at least one copy of the data that cannot be deleted in any scenario - either accidentally during normal operations, or by some attacker who gains access to credentials.
This is where we used Wasabi's compliance lock to guarantee that files cannot be deleted, even by us or someone who has our credentials, until they're marked for deletion by the customer.
The way this works is:
When a file is initially uploaded, it gets replicated to our secondary hot storage in Wasabi.
This Wasabi bucket has a 21-day compliance lock. This means that a file cannot be deleted from this bucket (even by us) until it is removed from compliance hold; and after removal from compliance hold, it still cannot be deleted for the next 21 days.
If the user deletes this file, then it goes to their trash. After 30 days, or if the user manually empties their trash, the file will marked as permanently deleted, and we go and remove the compliance hold on the file.
At this point, the file still cannot be deleted, but it'll become eligible for deletion after the retention period (21 days) elapses.
23 days after being marked as permanently deleted, our cleanup batch process to remove old data will pick this file. Since 21 days have elapsed, the file can (and will) now be removed.
The choice of 21, 23 and other durations is meant to strike a balance between providing a protection buffer whilst still allowing us to remove customer files within a month of account deletion (as mentioned in our privacy policy).
Database backups
The mechanism outlined above is for the replication of encrypted files (what we call as our "object storage"). Database replication is done slightly differently:
Our primary database is a high-availability active-passive replica pair of Postgres instances that run on Scaleway. So in case the active DB instance fails, the database will automatically switchover to the passive instance. The passive instance is continually kept up to date with the data on the active instance all the time, so there'll be no data loss in such a switch.
Every 6 hours, we take automated snapshots of the database, with a rolling retention period of 3 days for each snapshot. These snapshots are quick to take / quick to restore from, and form the next layer of defence.
Every day, we run a cron job to create an isolated backup of the database. Unlike the snapshot which is a proprietary Scaleway offering, these backups are portable database dumps that can be restored using standard pg_restore commands to a Postgres instance running anywhere, and are not tied to Scaleway's RDS.
These backups are retained in Scaleway's multi-AZ Paris region for 30 days, and thus have the same protection as the encrypted files in our nuclear fallout shelter cold storage get.
But that's not all. The cron job that takes the backup also downloads the backup, encrypts it, uploads the encrypted backup to a Backblaze bucket, and sets a 25 day object lock on the backup. Thus, in case we do not have access to Scaleway, we can still obtain an encrypted backup from Backblaze; and since this encrypted backup is under a object lock, it cannot be deleted for the next 25 days even by us accidentally, or by an attacker with credential access.
The cron job wraps up by removing backups older than 30 days from both Scaleway and Backblaze.
Note that the main PII information in our database - the customer's email - is not stored in plaintext in our database; instead, the email is stored in an encrypted form, alongwith a hash for lookups. So an attacker with access to the plaintext database will still not be able to obtain the customer's email address. Still, we encrypt the overall backup before storing it in Backblaze to add an extra layer of protection.
Taking backups is one half of the puzzle, the other half is ensuring that they can be restored from. For this purpose, we have a dedicated machine that just does one thing:
Every day, it downloads the most recent backup from Backblaze, creates a new Postgres instance locally, and restores the backup to it.
If something goes wrong, it'll bail out, otherwise it ends with a success message that gets logged to Grafana.
We have setup alerting that notices if this success message is not logged for 2 days, so that we get to know if the restores start failing.
The machine that checks the restores also runs an instance of our backend service. This service is the same as our production backend service, but with 2 differences in the configuration file:
Instead of the primary database, it connects to the local Postgres.
Instead of the primary hot storage (Backblaze), it connects to the secondary hot storage (Wasabi).
Finally, we have custom builds of our web app that can connect to this special backend. Using it, we can manually perform an end-to-end test of failover, and verify that both the secondary object storage and the database backups are ready to use.
Scope for improvement
Our current setup has one issue which might need architectural changes:
- The database snapshot frequency of once per 6 hours still leaves room for accidents to cause loss of recent database changes that happened in the few hours since the last snapshot was taken. One option is to further increase the snapshot frequency, but we are also thinking of potential architectural changes towards a more principled solution. For example, we could move to an event sourcing model, and/or retain the most recent few hours of API requests in a form which can be replayed to restore the state of the DB.
Then there are 2 aspects which can be improved on, where there is no technical limitation in our current architecture that prevents them from happening, but where it is a matter of us spending time and effort to implement these:
Time to recovery: While we have tested manual failover to our secondary hot storage / DB backup, it would be better to have an automated failover mechanism. This would reduce the time to recovery; further, we can also use such a setup to continually test the failover.
Varying SLAs: Not all customers might want the 3x protection that we provide, and some might be okay with reduced protection if it reduces the plan price. So we intend to make it possible for customers to opt into lesser, or different, replica choices. Indeed, one exciting direction here is to allow for customers to opt into blockchain storage (in addition to the primary replicas) if they wish.
Implementation details
We've been writing details of the parts that make up this replication strategy as we go about it (and get time to write!). For example, here is a post from the time we were tinkering with our schema, and here is a post describing how we retroffited the AWS go SDK to support Wasabi compliance.
Still, here is a 30k-foot recap:
The replication is performed using stateless goroutines. Each goroutine replicates one file. To replicate many files, we just start many goroutines. In practice, we haven't hit any limits and can scale up this process as fast as we want by deploying additional machines.
When the user uploads a new photo, we upload it directly to the primary hot storage. In addition, we create an entry in a DB table that serves as a queue for which all files are pending replication to the secondary hot storage and cold storage.
A goroutine comes around, and picks up an item from this queue. It keeps a running transaction on the queue item to ensure that nobody else picks it up.
It downloads the file from the primary, and uploads it to all places it needs to go. This is easily reconfigurable (we can have custom logic per file here if needed).
In case the goroutine gets abruptly terminated (say as part of a routine server update), the transaction gets rolled back and the item would be picked again.
Further details
For more details, including the history of our replication strategy and the overall motivation behind it, we request you to checkout this blog post.
If you'd like to help us improve further or have other suggestions, please reach out to us at engineering@ente.io or comment below.
We hope this gives you some pointers for your own work. Thank you for reading!

Top comments (0)