
Originally posted on Educative.io by Ayesha Alvi
According to Statista, more than half of the world’s population consists of active Internet users. We rely on the internet for just about everything: checking email, calling an Uber, and ordering food and clothes. While most of us rely on the internet, what goes on ‘behind-the-screens’ eludes most.
This post will allow you to understand what goes on when you enter a URL into a browser - a process that you not only interact with daily but also largely depend on.
Fundamentally, this process can be broken down into a few steps. We’ll discuss the technological details of each in a way that anyone can understand.
If you’d like to go beyond the scope of this post for a deep dive on networking fundamentals, you can visit Grokking Computer Networking for Software Engineers and check out a free preview. This course will be helpful for those who are getting their software development career started. If you already are a software engineer, a deeper knowledge of networks will help to set you apart from the crowd of engineers who assume the network ‘just works’.
Let’s get started!
What is a website?
All websites are files. A barebones website is just an HTML file, however, most websites today comprise of several inter-linked files which include JavaScript and CSS.
Websites exist on powerful computers called servers. Servers are usually located somewhere remote from your computer. In order to display the website on your browser, it has to retrieve it from the server. Each server, hence, has an address through which it can be accessed called an IP address.
Retrieving a website from a server is a lot like retrieving goods from a warehouse. The warehouse is akin to the server because it is remote, has an address just like servers have IP addresses and stores goods just like servers store or host websites.

IP addresses are represented as four numbers each between 0 and 255 separated by dots. Here’s an example of an IP address:
Every device that is connected to the Internet has an IP address, regardless of whether it is a server or not. Your computer has an IP address too. The simplest way to find your computer’s IP address is is to visit https://www.whatsmyip.org/. Note that all Internet-enabled devices have an IP address but not all of them are servers.
If your browser knows the IP address of the server on which a website exists, it will be able to access it. However, all it knows is the URL.
The Anatomy of a URL
A URL or Uniform Resource Locator is used to locate a resource, in our case, the website on a server. The requested resource can be a file of any kind, for example, an MP3 file, an image, or a cpp file. The URL tells your browser two things:
Domain name: a unique name that identifies a website. Examples include, facebook.com, educative.io, and google.com. A domain name specifies which server a resource/website is on.
Path to file: The files on the server have a location just the way your PC has a file system and each file has a location. The URL also tells where the specified resource that is requested is located on the server. The files or resources on the server have locations that are specified in the URL.

Suppose you enter a URL like the one above into your browser. In this case, course.php is the requested resource located inside the folder allcourses on the server with the domain name educative.io.
You might be wondering why URLs are used anyways. Why not just type IP addresses directly into browsers?
Well, there are a number of reasons for this. First, humans are generally not very good at memorizing random numbers. Imagine memorizing 73.22.49.2 over www.Facebook.com. It’s easy enough for one website but imagine having to do this for all the websites you access in a day. You’d likely end up with the IP addresses written somewhere! So URLs are just practical. Second, the server hosting the website may change over time which would mean the IP address would too. Keeping track of these changes is not pragmatic for users.
DNS
So how does your browser figure out the IP address from a supplied URL? Well, that is where the Internet’s directory service, Domain Name System or DNS, comes in. DNS is used to find IP addresses from domain names.
These domain name to IP address mappings are called DNS records.

These DNS records are part of a distributed database which means all the records are not stored at any one server but they are distributed amongst several servers.
Since a full network intensive-resolution can slow down the process, it is more efficient to check if the mapping is already known than prematurely conducting one. This is done in a number of steps. First, the browser’s local cache is checked. If it does not have the record, the OS’s cache is checked. If the record does not reside there either, the router is checked for the record. Lastly, the query is sent to the ISP (Internet Service Provider) for it to check its cache.
DNS servers are divided into zones that form a hierarchy. The servers at the top are called ‘root servers’ and they store IP addresses of other DNS servers called top level domain servers. Top-level domain (TLD) servers are divided by type, i.e., .com, .edu, etc. TLD servers have mappings to ‘second-level domain’ servers such as to a server for wikipedia.com and educative.io. These DNS servers that contain mappings to the actual servers that host the domain in question.
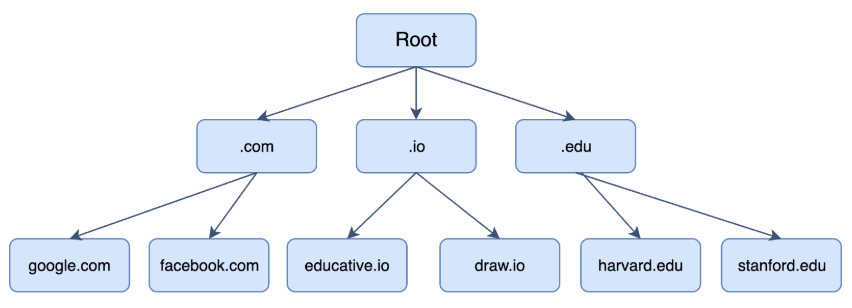
Hence, if the record cannot be found locally, a full DNS resolution is conducted as follows:
The first point of contact for a full resolution is a root server. As of the writing of this post, 1017 instances of root servers exist. Check out https://root-servers.org/ for more details and an interactive map!
The root server returns the IP address of the relevant top level domain server.
The top level domain returns the IP address of the second level domain server.
The second-level domain server contains the DNS record of the server we are looking for. The second-level domain server returns the IP address to the browser.
A good way to think of this is that a domain name is resolved in reverse:

You can think of a dot being there after the URL which represents the root server. The root server returns the address of a top-level domain server, in this case for an io server.
The io server then returns the address to the DNS server that knows the address of an Educative server.
The Educative DNS server returns the address to an Educative server.

Now that the browser knows the IP address of the server, it can send a request to it.
HTTP
These requests follow a ‘protocol’ or ‘rules of communication’ called HyperText Transfer Protocol (HTTP). This protocol dictates the format of the messages, when what message is sent, appropriate responses, and how messages are interpreted. HTTP messages are of two types: request and response.
An HTTP request message consists of a request line and headers. The message starts with a request line and is followed by headers. Here’s a sample HTTP request:
GET /path/to/file/index.html HTTP/1.1
Host: www.educative.io
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
Accept: text/html
The request line consists of a request method, a path, and the HTTP version. The request method, GET, in the example above tells the server what to do. GET, for example, tells the server that the client wants to retrieve the resource at the supplied path. Other examples of request methods include DELETE, which tells the server to delete a resource at the given path, and PUT, which tells the server to put a supplied resource at the given path. The HTTP version is also specified to cater for the differences between each.
Next come the HTTP headers. Headers allow the client to communicate extra information such as the server type and the date. Each header exists on a separate line, consists of a name, followed by a colon and then the value of the header. There are a number of headers. For example, the connection header indicates whether it's a HTTP connection type. If you’d like a more detailed dive into headers, you can visit Grokking Computer Networking for Software Engineers.
The server then sends an HTTP response message. Here’s a sample response message:
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15: 44 : 04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
[The object/file that was requested]
Response messages consist of a status line to start with, followed by a number of headers, followed by a blank line and ends with a resource if any was requested.
The status line consists of the HTTP version and a status code. There are a few types of status codes. Are you familiar with the annoying 404 Not Found?
Well, it’s an HTTP status code! Here’s a basic list and what each means:
200 OK: the request was successful, and the result is appended with the response message.
404 File Not Found: the requested object doesn’t exist on the server.
400 Bad Request: generic error code that indicates that the request was in a format that the server could not comprehend.
500 HTTP Internal Server Error: the request could not be completed because the server encountered some unexpected error.
505 HTTP Version Not Supported: the requested HTTP version is not supported by the server.
Next, the browser receives the response, interprets it and displays something accordingly to the user. For instance, if an HTML page is returned, the browser interprets it and displays it accordingly.
However, most websites today do not consist of simple HTML. This scenario is extremely oversimplified and this actually happening is very rare. Real world websites often consist of other resources such as images which are requested from the server via subsequent HTTP requests.
There are many reasons why you would want to learn more about networks.
If you want to start a career in software development, this knowledge will be immensely valuable. If you already are a software engineer, a deeper knowledge of networks will help to set you apart from the crowd of engineers who assume the network ‘just works’.
Furthermore, network security is a very exciting discipline. In addition to research, ethical hacking and pentesting are viable careers in network security. However, it cannot be learned or fully understood without a very solid foundation in networks.
Educative recently launched a course, Grokking Computer Networking for Software Engineers, that will help you learn the most crucial aspects of networking.
Happy learning!


Top comments (3)
Comprehensive but simplified and easy to learn. Keep up the good work 👍
An easy to follow and comprehensive article. Really enjoyed reading it.
Such important concepts simplified amazingly! Great job!