What is "Character Encoding"
A character encoding is a numeric representation of binary numbers so that a computer can handle the characters.
It is also referred to as the character set, charset, and character code.
ASCII (American Standard Code for Information Interchange)
ASCII is one of the Charset which contains Latin alphabets. Since English consists of about 100 characters including not only alphabets but also numbers and other symbols, ASCII is made of 7 bits which can represent 2^7=128 characters. ISO/IEC 646 is the nationalized version of ASCII.

8bits Code
The 8bits character code can be divided into the CL, GL, CR and GR areas as shown in the figure below. In CL and GL, the 8th bit is 0; in CR and GR, the 8th bit is 1; C and G mean control and graphical; L and R mean left and right, respectively.
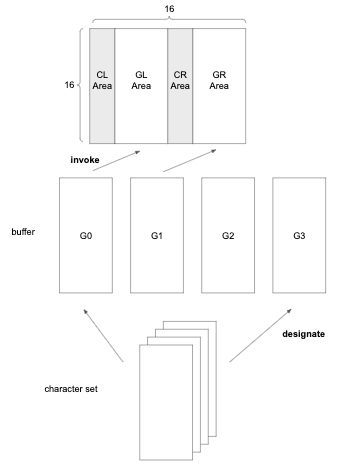
ISO/IEC 2022 makes it possible to use different character set by using Escape Sequence to invoke another character set to GL or GR area from buffers.
Also, in 8bits code, 2 byte character can represent 94x94 or 96x96 characters while keeping extensibility of the ASCII code. It is accomplished by setting ASCII in GL area and 2 byte code in GR area.
Unicode
Unicode is a character code based on the idea of putting all the world's characters in one table.

Unicode, which is correspondent table from character to code point, is called Coded Character Set, and the one from code point to code such as UTF-8 is called Character Encoding Scheme.
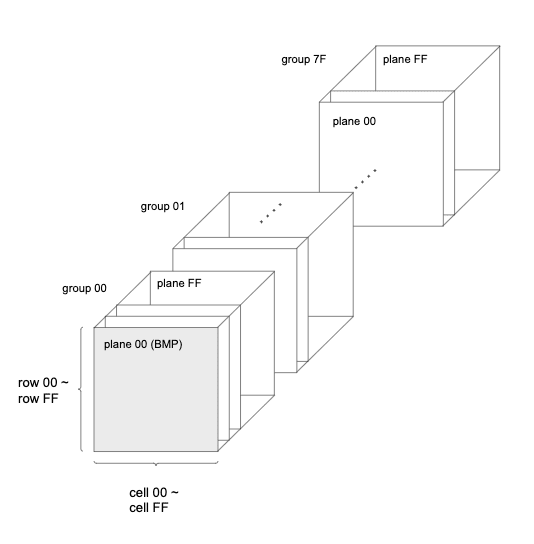
UCS-4, which is known as Unicode, consists of four bytes, which are groups, planes, rows and cells. Groups are from 00 to 7F and planes, rows and cells are from 00 to FF in hexadecimal. Plane00 in Group00 is called BMP (Basic Multilingual Plane) and also known as UCS-2, which is original Unicode. Most of the commonly used letters are included in BMP.
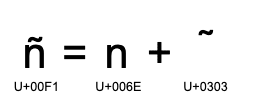
One of the complex structures of unicode is that there are two ways to represent combined characters.
However, there are some exceptions, such as combined emoji, which are only represented using ZWJ (Zero-Width Joiner), a kind of control character, and there's only one way of code to represent the combined emoji.

UTF-8
UTF-8 (Unicode Encoding Forms 8) is a variable length encoding scheme whose length varies from 1 to 4 bytes, depending on the value of the code point. It's compatible with ASCII, highly efficient and the most popular encoding scheme.
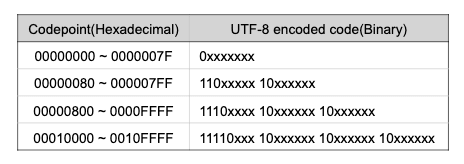
The steps encoding by UTF-8 varies depending the range of codepoint. First, divide the code into 1 to 4 parts. And then, add value in the front to make them bytes. Below is the table which shows what value is added.
Below is the example to encode U+611F which is represented by 3 bytes.
- Change it to binary
- Divide it into 4 bits, 6 bits and 6 bits
- Add 11100000, 100000000, 100000000 to each value

UTF-16
UTF-16 is an encoding scheme that encodes code point as 16 bits fixed-length data. Non-BMP characters are expressed using surrogate pairs. The same range as ASCII is not compatible with ASCII because it is also represented by 16 bits.
Surrogate pairs are a method of handling all code points in 16 bit * 2 pairs since 16 bits are not enough to represent over U+10000 codepoints. There are unused area in BMP which is U+D800 to U+DBFF (1024 bits) and U+DC00 to U+DFFF (1024 bits). Using these pairs to represent 1024 * 1024 = over 1,000,000 characters, which are allocated from U+10000 to U+10FFFF.
The steps converting from codepoint to surrogate pairs is below.
- Subtract U+10000 from the code point
- Change it to 20 bits by making it binary
- Divide it into 10 bits each
- Add U+D800(1101100000000000), U+DC00(1101110000000000) to each value


Top comments (0)