Hello all, It’s been a while since I did a blog post outside of the weekly updates. But I wanted to do one in terms of conversations that I’ve been having a lot lately and seems to be largely universal. High Availability. So more and more, software is becoming a critical part of every aspect of our lives. To that end, we really see as developers / engineers, the following scenarios have become a constant reality:
- For end customer software, not having access for an extend timeframe to an app or service can be the final nail in the coffin for a lot of users. Their tolerance for down time continues to drop. If you don’t believe me, research the metrics around how long someone will wait for a video to load before leaving according to YouTube.
- For enterprises, organizations are becoming more and more reliant on software to function at the most basic level, meaning that outages or downtime windows have an even greater impact on their business, causing more parts of the organization to have to function at a diminished capacity or not at all during an outage.
The end result of these perceptions / realities is that the demands put on software solutions for maintaining availability are going higher and higher. And it becomes important to architect and plan for high availability to start with, as if you don’t it can be very expensive and difficult to retro-fit your applications to meet these demands.
This is a huge topic, and one that I’m not going to be able to cover in one blog post, but I’m hoping that we can identify ways to help if you are being tasked with meeting these demands.
Defining SLA

So the first part of this conversation, always in my experience starts the same, “What’s our SLA?”, so let’s talk through what an SLA is? SLA stands for Service Level Agreement, and this is a legal agreement of what level of service you are required to provide.
Now the key part of that, is a “legal agreement”, this is not strictly a software function or engineering concept, but a business agreement in the sense that if an SLA is not met, there is a financial obligation from the organization to compensate the customer (in an enterprise setting).
Be Reasonable…

So the most common mistake I hear when someone starts down this road is “we need 100% SLA”, which is a bad place to start this process. Realistically this is almost impossible, the idea that you will never have an outage is extreme. And to get this level of resiliency you can expect to pay for it, and its easy to get upside down on your costs by starting out here. And really mean need to be realistic about the ask here.
Let’s walkthrough an example, let’s say you have a software the provides grant processing for a municipality, and that grant reviews are done monday to friday during business hours (8-6pm). If your customer says “We need a 100% SLA”, I would make the counter argument of “Do you really?” If the system is down from 1-2am on a saturday, does that really affect you and the nature of the business? Or is this just a matter of needing the solution to be up during those core business operating hours?
Conversely let’s go the other way, and say that you are providing a solution that provides emergency service communication in terms of a natural disaster? Would your customer be ok with a 5-minute downtime at 2am in the middle of a hurricane? Probably not. So tolerance should be measured in terms of actual impact to the end user and ability to function.
High Availability is like insurance, I can get add-ons to my policy for everything that could ever happen, but that means that I will likely be paying for things I don’t need. I can get volcano insurance in Pennsylvania, but the odds of needing it are so low to make it ridiculous.
So what we should be doing is finding a happy balance between what we can realistically do, and do by following recommended processes, and way the business calculation, and cost.
Let me give you a high level example, let’s say I deploy my production environment to one region, and I’ve calculated that the composite SLA (more on this later) to be 99.9% for one region. That means that right now I am telling my customers that I am expecting about 43.2 minutes of downtime a month.
But if I stood up a secondary region, and built out a lot of automation around failover and monitoring (lets say 80 hours of work), I could raise that SLA from 99.9% to 99.99% which would mean a downtime of 4.32 minutes.
Now what I need to weigh is the following:
- 80 hours worth of labor costs
- opportunity cost of not using that labor resource on new features
- doubling my environment costs (2 active regions)
- Potential advantage by supporting a higher SLA.
And I look at that and say, I’m saving 38.88 minutes of downtime in the process. So the question is, does that help my business and make sense from a financial position, or am I “ok” taking a financial hit and having only 1 environment up, and paying out if we are down for more than the 99.99% and rolling the dice on that.
I can’t say in the above discussion what the right answer is, because ultimately it depends on the type of business and resiliency of the application. You might be comfortable with that, you might not.
My point is that at the end of the day this is both an engineering problem and a business problem, and likely the right answer is somewhere in the middle.
Now to be clear, other times, especially in enterprise software, the customer may require a certain SLA, and at that point you might have to show that you meet that SLA by having specific redundancies in place. I’ll talk about this more in our next section.
Calculating a composite SLA

Another common area of question, is “How do I calculate the SLA of my service?” And this is more straight forward than people realize. Let’s take the following example:
Note: You can find all of azure’s SLAs here .
| Service | SLA |
| App Service | 99.95% |
| Azure SQL | 99.99% |
So based on the table above, the composite SLA would be:
.9995 * .9999 = .9994 = 99.94%
So that would imply that your cloud provider is standing behind these service to have downtime of :
730 (Hours per month) * (1 – .9994) = 26.28 minutes
Now the above is an estimate, but it would be around that time that we could expect to be our monthly downtime. This calculation doesn’t change the more services you add.
Now its important to note, this is the platform SLA, not your SLA. And I say that because at the end of the day, this is assuming that your application doesn’t have issues that cause downtime, so that should be considered as well.
How do we improve our SLA, start with “what is down?”

Now for many cloud services, Microsoft and every other cloud provider gives recommendations to enhance resiliency and improve your SLA. One way to do that is to leverage items like Availability Zones and multi-region deployments. This allows you to spread out your application across multi-regions and it makes the probability of an outage drop substantially.
Really the first step here is to do a failure mode analysis, and determination of critical functionality. And what I mean by that is we need to define what constitutes the system being “Down”. So let’s take for instance you have an eCommerce platform, something like NopCommerce, and you have the following use-cases:
- Browse the catalog
- Add items to shopping cart
- Purchase items
- Publish blogs
- Send out notifications of deals / sales
- Process Orders
Now based on the above, we could identify 1,2,3, and 5 as mission critical, if we can’t allow our customers to shop, buy, and receive their products, that means that we are out of business. If we can’t publish a blog when we want to, or if a sale notice goes out a little late, its not ideal, but its not the end of the world. And let’s say that we have azure functions sending the notifications, and the blogs and promotions are managed by Cosmos DB.
So now based on that, we need to examine our architecture and identify what components are required to maintain the 4 key uses cases we identified. Notice I left off the elements that are not part of our key functionality for our SLA.
Let’s say we have the proposed architecture:
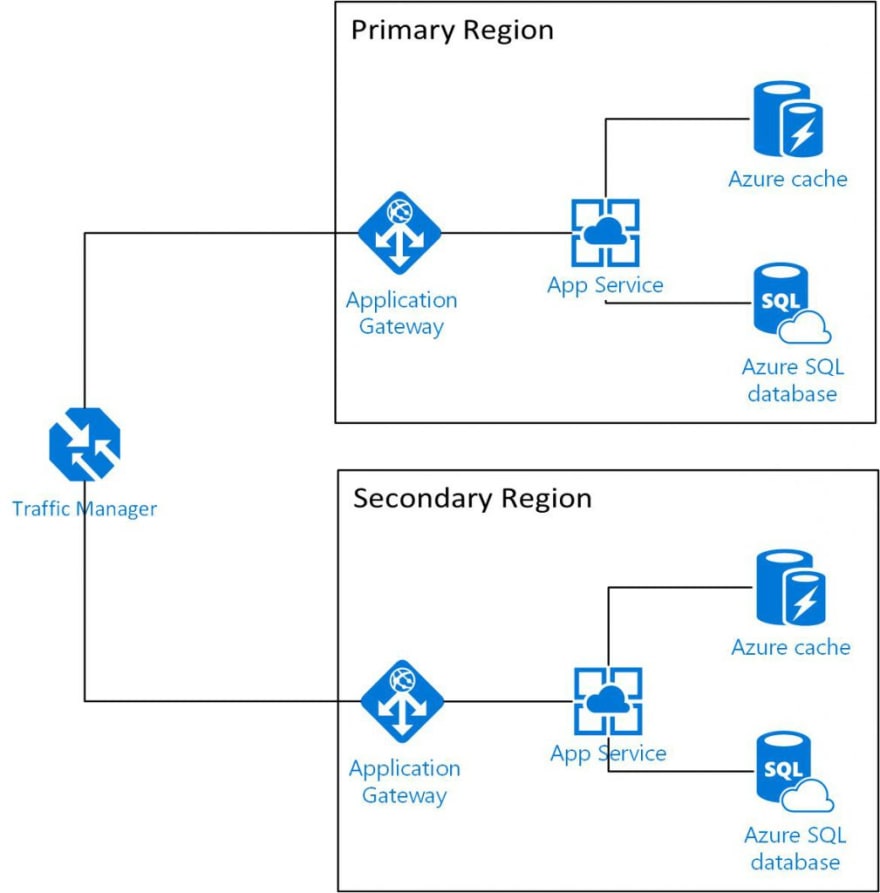
Now based on the above, I can calculate our primary region SLA to be:
| Service | SLA |
| Application Gateway | 99.95% |
| App Service | 99.95% |
| Azure SQL | 99.99% |
| Total SLA | 99.89% |
So as a result of the above, we need to examine what elements of our solution are critical to the meeting our uptime SLA, and then doing a failure analysis. So based on the above use-cases, we can assume that the Traffic Manager, Application Gateway, App Service, and Azure SQL are essential to our meeting of our SLA. For the sake of this example, let’s say that the caching layer meets with industry recommendations and is used only for speed of access, if not available the application will just reach out to the database.
So how do we calculate the compound SLA for the two regions, we do that with the following math:
We basically have to figure out the probability of both regions being offline, so if we take the region “unavailability” of .12% and multiply it by one another:
0.12% * 0.12% = 0.0121%
Convert it back to availability:
100 % – 0.0121% = 99.99%
Now we take that multiplied by traffic manager SLA:
.9999 * .9999 = 99.99%
Failure Mode Analysis:

A failure analysis means that we pick apart each element of the infrastructure and identify the following:
- What potential failures could occur?
- What are the different “modes” or “states” can this component be in?
- How likely is a failure of this component?
- What is the impact of each failure “mode” or “state” on the application?
After examining the above, you need to look at each of the “modes” or “states” and identify the following:
- How you will respond and recover?
- How you will monitor for this situation, before, during, and after?
So let’s take an example, because to me that always helps. If we examine the above solution, and say Azure SQL Database. If I were to do a failure mode analysis, I would find the following:
-
The database is offline in the following situations:
- The database can be offline due to a platform issue
- the database is shutdown
- the database is deleted
-
The database is in a degraded state in the following situations:
- Database is performing slowly due to high website demand.
- Database is running slowly due to bad query optimization
- Database is experiencing deadlocks
Now this is by no means an exhaustive list, but it hits the high points for our ecommerce site. Now in those states, I need to identify what do for these scenarios. So the question is how do we respond and recover. In the case of the database, the most common recommendations are, to use a standard tier, and to use active geo-replication.
So for “How do we respond, recover?” I would say we setup active geo-replication of our production database to a secondary region. In the event the database is “offline” we fail-over to a secondary region and leverage traffic manager to route to the backup site. We would see some data loss during the failover, but for this exercise, let’s say that is manageable.
The next question is the most important, how do we monitor for this? The answer is we could do this a couple of ways:
- Setup alerts via azure monitor around specific metrics.
- Setup alerts in Application Insights for Dependency failures for database calls.
- Build a page within our application that Traffic Manager can prob to identify when the database is unreachable and trigger failover.
The next mode was “degraded” and if we examine that the response is to increase the performance tier of the database to respond to increased demand, or do more in-depth analysis around the performance of the database. Again the monitoring would be similar of setting up alerts around these conditions to make appropriate staff aware.

So all kidding aside, this is a huge topic, and one I want to boil down more on how best to implement these solutions. This post didn’t begin to discuss the differences between RTO / RPO, or how you make sure to ensure resiliency through transient fault tolerance or distributed architectures, and that’s just scratching the surface, so more to come.

Top comments (0)