- Intro
- Check Network Tab First
- Impersonate TLS and HTTP Handshake
- User-Agent
- Code and Response examples with/without User-Agent
- Rotate User-Agents
- Additional Headers
- Ordered Headers
- IP Rate Limit
- Proxies
- Non-Overused Proxies
- CAPTCHA Solver
- Delays
- Become Whitelisted
- Using SerpApi
- Links
Intro
This ongoing blog post is about understanding ways of bypassing blocks when doing web scraping, and what tools might be handy to use.
At SerpApi we encountering all sorts of website blocks including CAPTCHA and want to share back a little of our knowledge gained while building our APIs.
Keep in mind that the techniques shown are not 1:1 to what we use in our production. It's more about showing different ways of achieving the same thing i.e reducing or avoiding blocks from the website.
Check Network Tab First
Before you try to make the most stealth bypass system, take a look in the Network tab under dev tools first and see if the data you want can be extracted via direct API/Server request call. This way you don't need to make things complicated from the beginning.
📌Note: API calls are also protected. For example, the Home Depot and Walmart block API requests without proper headers.
To check it, go to the Dev Tools -> Network -> Fetch/XHR. On the left side you'll see a bunch of requests send from/to the server, when you click on one of those requests, on the right side you'll see the response via preview tab.
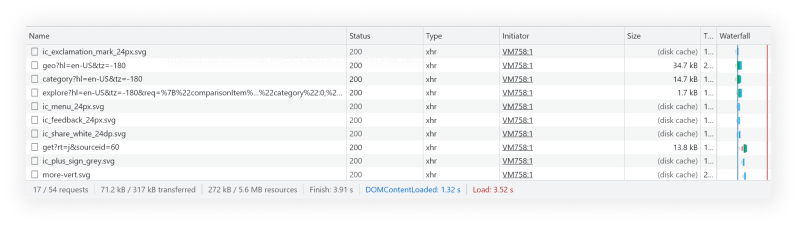

If some of those request have the data you want, click on it, go to headers tab on the right and copy URL to make a requests using Python requests.get() or Ruby HTTParty.get().

Impersonate TLS and HTTP Handshake
To put it simply, this approach prevents detection by a website that it's a script that sends a request. It allows to bypass most or all CAPTCHAs.
You can achive this with two ways (although could be more):
- Could be adapted to be used with multiple languages:
curl-impersonate - Python specific:
selenium-stealthorundetected-chromedriver
User-Agent
It's the most basic one and usually, for most websites, it will be enough, but user-agent does not guarantee that your request won't be declined or blocked.
In basic explanation, user-agent is needed to act as a "real" user visit, which is also known as user-agent spoofing, when bot or browser send a fake user-agent string to announce themselves as a different client. It's almost the same as Impersonate described in the previous section but more basic.
Impersonate TLS and HTTP handshake doing more advanced bypassing things under the hood to prevent request from being detected as a bot.
The reason why request might be blocked is that, for example in Python requests library, default user-agent is python-requests and websites understands that it's a bot and might block a request in order to protect the website from overload, if there's a lot of requests being sent.
User-agent syntax looks like this:
User-Agent: <product> / <product-version> <comment>
Check what's your user-agent.
In Python requests library, you can pass user-agent into request headers as a dict() like so:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
# add request headers to request
requests.get("YOUR_URL", headers=headers)
In Ruby with HTTPary gem it's identical process:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
# add request headers to request
HTTParty.get("YOUR_URL", headers:headers)
Code and response examples with and without user-agent
Examples below will be using Python and requests library. This problem is very common on StackOverFlow.
Let's try to get data from Google Search with and without user-agent passed into request headers. The example below will try to get the stock price.
Making request without passing user-agent into request headers:
import requests, lxml
from bs4 import BeautifulSoup
params = {
"q": "Nasdaq composite",
"hl": "en",
}
soup = BeautifulSoup(requests.get('https://www.google.com/search', params=params).text, 'lxml')
print(soup.select_one('[jsname=vWLAgc]').text)
Firstly, it will throw and AttributeError because the response contains different HTML with different selectors:
print(soup.select_one('[jsname=vWLAgc]').text)
AttributeError: 'NoneType' object has no attribute 'text'
Secondly, if you try to print soup object or response from requests.get() you'll see that it's a HTML with <script> tags, or HTML that contains some sort of an error.
Making requests with user-agent:
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
params = {
"q": "Nasdaq composite",
"hl": "en",
}
soup = BeautifulSoup(requests.get('https://www.google.com/search', headers=headers, params=params).text, 'lxml')
print(soup.select_one('[jsname=vWLAgc]').text)
# 15,363.52
Rotate User-Agents
If you are making a large number of requests for web scraping a website, it's a good idea to make each request look random by sending a different set of HTTP headers to make it look like the request is coming from different computers/different browsers.
The process:
- Collect a list of User-Agent strings of some recent real browsers from WhatIsMyBrowser.com.
- Put them in Python
list()ortxtfile. - Make each request pick a random string from this
list()usingrandom.choice().
import requests, random
user_agent_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
]
for _ in user_agent_list:
#Pick a random user agent
user_agent = random.choice(user_agent_list)
#Set the headers
headers = {'User-Agent': user_agent}
requests.get('URL', headers=headers)
Learn more at ScrapeHero about how to fake and rotate User Agents using Python.
Additional Headers
Sometimes passing only user-agent isn't enough. You can pass additional headers. For example:
-
Accept:
Accept: <MIME_type>/<MIME_subtype>; Accept: <MIME_type>/*; Accept: */* -
Accept-Language:
Accept-Language: <language>; Accept-Language: * -
Content-Type:
Content-Type: text/html; img/png
See more HTTP request headers that you can send while making a request.
Additionally, if you need to send authentification data, you can use requests.Session():
session = requests.Session()
session.auth = ('user', 'pass')
session.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
session.get('https://httpbin.org/headers', headers={'x-test2': 'true'})
Or if you need to send cookies:
session = requests.Session()
response = session.get('https://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(response .text)
# '{"cookies": {"from-my": "browser"}}'
response = session.get('https://httpbin.org/cookies')
print(response.text)
# '{"cookies": {}}'
You can view all request/response headers under DevTools -> Network -> Click on the URL -> Headers.
In Insomnia (right click on URL -> copy as cURL (Bash)) you can see what HTTP request headers being sent and play around with them dynamically:
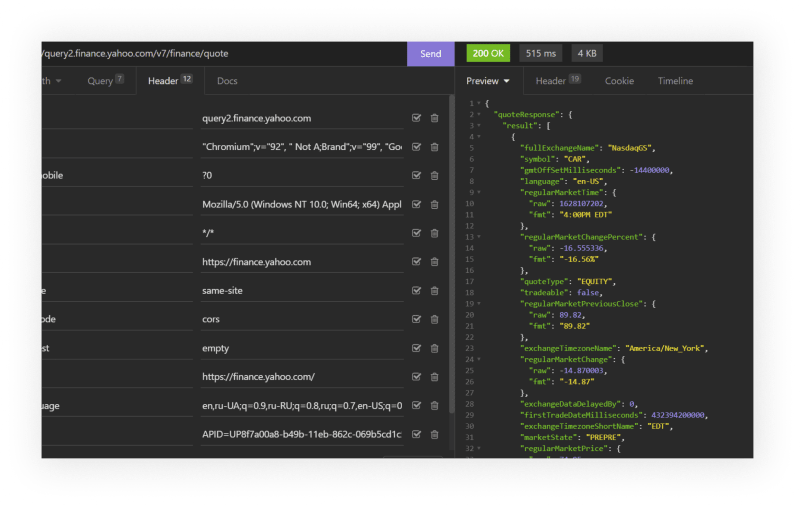
It can also generate code for you (not perfect all the time):

Ordered Headers
In unusual circumstances, you may want to provide headers in an ordered manner.
To do so, you can do it like so:
from collections import OrderedDict
import requests
session = requests.Session()
session.headers = OrderedDict([
('Connection', 'keep-alive'),
('Accept-Encoding', 'gzip,deflate'),
('Origin', 'example.com'),
('User-Agent', 'Mozilla/5.0 ...'),
])
# other code ...
custom_headers = OrderedDict([('One', '1'), ('Two', '2')])
req = requests.get('https://httpbin.org/get', headers=custom_headers)
prep = session.prepare_request(req)
print(*prep.headers.items(), sep='\n')
# prints:
'''
('Connection', 'keep-alive')
('Accept-Encoding', 'gzip,deflate')
('Origin', 'example.com')
('User-Agent', 'Mozilla/5.0 ...')
('One', '1')
('Two', '2')
'''
Code was taken from StackOverFlow answer by jfs. More about Requests Header Ordering.
IP Rate Limit
IP rate limits work similar to API rate limits, but there is usually no public information about them.
In that case, multiple proxies are a way to go since when one proxy has trouble returning a response, the second one can make a request while the first one is struggling and return the successful response.
It's a basic security system that can ban or block incoming requests from the same IP. It means that a regular user would not made 100 requests to the same domain in a few seconds, so "they" proceed to tag (or whatever they do) that connection as dangerous/unusual/suspicious so we cannot know for sure how many requests we can do per X period of time safely.
Try to save HTML locally first, test everything you need there, and then start making actual requests to the website(s).
Proxies
Sometimes passing request headers isn't enough. That's when you can try to use proxies in combination with request headers.
Why proxies in the first place?
- If you want to scrape at scale. While web scraping there's could a lot of traffic while making requests. Proxies are used to make traffic look like regular user traffic making things balanced.
- If destination website you want to scrape only available in some countries, then you make a request from a specific geographical region or device.
- If you want to have an ability to make concurrent sessions to the same or different websites which will reduce chances to get banned or blocked by the website(s).
It's also great to rotate proxies in combination with rotating user-agents as it will reduce the chance of being blocked quite a lot.
Using Python to pass proxies into request (same as passing user-agent):
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
Using HTTParty to add proxies like so, or like in the code snippet shown below:
http_proxy = {
http_proxyaddr: "PROXY_ADDRESS",
http_proxyport: "PROXY_PORT"
}
HTTParty.get("YOUR_URL", http_proxy:http_proxy)
Or using HTTPrb to add proxies:
HTTP.via("proxy-hostname.local", 8080)
.get("http://example.com/resource")
HTTP.via("proxy-hostname.local", 8080, "username", "password")
.get("http://example.com/resource")
Non-overused proxies
To keep things short, if possible, do not use overused proxies because:
- Public proxies are the unsafest and the most unreliable proxies.
- Shared proxies are usually the cheapest proxies, because many clients split the cost and get to use more proxies for the same price.
You can scrape a lot of public proxies and store them in the list() or save it to .txt file to save memory and iterate over them while making a request to see what's the results would be, and then move to different types of proxies if the result is not what you were looking for.
Learn more about other types of proxies and which one of them is the best for use case.
CAPTCHA Solver
An additional step is to use CAPTCHA solver, for example, 2captcha that supports multiple languages. It allows bypassing all possible CAPTCHAs depending on the target website.
An ideal scenario is when it is used with residential proxies and impersonates the TSL, HTTP handshake to avoid most or all blocks.
Delays
Delays could do the trick sometimes, but it very depends on the use case, and it will depend on whether you should use them or not.
In Python, you can use built-in time.sleep method:
from time import sleep
sleep(0.05) # 50 milliseconds of sleep
sleep(0.5) # half a second of sleep
sleep(3) # 3 seconds of sleep
In Ruby, it's an identical process using sleep method as well:
# Called without an argument, sleep() will sleep forever
sleep(0.5) # half a second
sleep(4.minutes)
# or longer..
sleep(2.hours)
sleep(3.days)
Become Whitelisted
Get whitelisted means to add IP addresses to allow lists in website which explicitly allows some identified entities to access a particular privilege, i.e. it is a list of things allowed when everything is denied by default.
One of the ways to become whitelisted is you can regularly do something useful for "them" based on scraped data which could lead to some insights.
Using SerpApi to deal with Search Engines
If you're dealing with search engines like Google, Bing, Yahoo, etc, you can avoid all of these problems using SerpApi. It's a paid API with a free plan.
The biggest difference is that all of the things is already done for the end-user, except for the authentification part and you don't have to think about it either maintain it or understand how to scale it.





Top comments (0)