![Cover image for [Tutorial] Web Scraping with NodeJs and Cheerio](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fi%2Fxovwc1mm2gxukjxajw2e.png)
In this article, we’ll cover the following topics:
-What is Web Scraping?
-What is Cheerio?
-Scraping data with Cheerio and Axios(practical example)
*A brief note: I'm not the Jedi Master in these subjects, but I've learned about this in the past months and now I want to share a little with you. If you are more familiar with these subjects feel free to correct me and enrich this post.
What is Web Scrapping?
First, we need to understand Data Scraping and Crawlers.
Data Scraping: The act of extract(or scraping) data from a source, such as an XML file or a text file.
Web Crawler: An agent that uses web requests to simulate the navigation between pages and websites.
So, I like to think Web Scraping is a technique that uses crawlers to navigate between the web pages and after scraping data from the HTML, XML or JSON responses.
What is Cheerio?
Cheerio is an open-source library that will help us to extract relevant data from an HTML string.
Cheerio has very rich docs and examples of how to use specific methods. It also has methods to modify an HTML, so you can easily add or edit an element, but in this article, we will only get elements from the HTML.
Note that Cheerio is not a web browser and doesn't take requests and things like that.
If you are familiar with JQuery, Cheerio syntax will be easy for you. It's because Cheerio uses JQuery selectors.
You can check Cheerio's docs here
Scraping data with Cheerio and Axios
Our target website in this article is Steam. We will get the Steam Weeklong Deals.

If you inspect the page(ctrl + shift + i), you can see that the list of deals is inside a div with id="search_resultsRows":
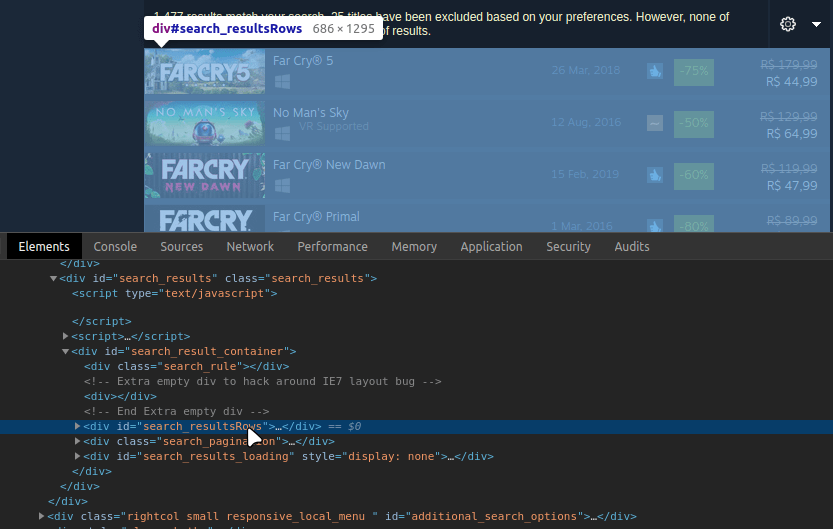
When we expand this div we will notice that each item on this list is an "< a >" element inside the div with id="search_resultsRows":

At this point, we know what web scraping is and we have some idea about the structure of the Steam site.
So, let's start coding!
Before you start, make sure you have NodeJs installed on your machine. If you don't, install it using your preferred package manager or download it from the official Node JS site by clicking here.
First, create a folder for this project and navigate to the new folder:
mkdir web-scraping-demo && cd web-scraping-demo
Once in the new folder, you can run:
yarn init -Y
or if you use npm :
npm init
To make HTTP requests I will use Axios, but you can use whatever library or API you want.
run:
yarn add axios
or if you use npm :
npm i axios
After installing Axios, create a new file called scraper.js inside the project folder. Now create a function to make the request and fetch the HTML content.
//scraper.js
const axios = require("axios").default;
const fethHtml = async url => {
try {
const { data } = await axios.get(url);
return data;
} catch {
console.error(
`ERROR: An error occurred while trying to fetch the URL: ${url}`
);
}
};
And here we start using Cheerio to extract data from the response, but first... We need to add Cheerio to our app:
run:
yarn add cheerio
or if you use npm :
npm i cheerio
Right, in the next block of code we will:
1- Import cheerio and create a new function into the scraper.js file;
2- Define the Steam page URL;
3- Call our fetchHtml function and wait for the response;
4- Create a "selector" by loading the returned HTML into cheerio;
5- Tell cheerio the path for the deals list, according to what we saw in the above image
//scraper.js
const cheerio = require("cheerio");
const scrapSteam = async () => {
const steamUrl =
"https://store.steampowered.com/search/?filter=weeklongdeals";
const html = await fethHtml(steamUrl);
const selector = cheerio.load(html);
// Here we are telling cheerio that the "<a>" collection
//is inside a div with id 'search_resultsRows' and
//this div is inside other with id 'search_result_container'.
//So,'searchResults' is an array of cheerio objects with "<a>" elements
const searchResults = selector("body")
.find("#search_result_container > #search_resultsRows > a");
// Don't worry about this for now
const deals = results.map((idx, el) => {
const elementSelector = selector(el);
return extractDeal(elementSelector)
})
.get();
return deals;
};
For this example, I will not get all the properties from each item. But you can get all the other properties as a challenge for you ;)
Note that for each "< a >" element in our deals list, we will call
the extractDeal function that will receive our element "selector" as argument.
The first property we will extract is the title. Look for the game title inside the HTML:

Oh, now it's time to implement our extractDeal function.
//scraper.js
const extractDeal = selector => {
const title = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_name ellipsis'] > span[class='title']")
.text()
.trim();
return { title };
}
Using the same method, we can get the game release date:
Inspecting the element on the Steam site:
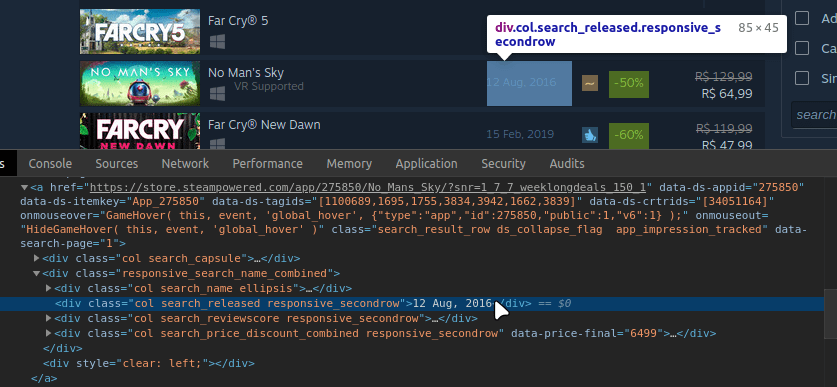
Then mapping the path in our function:
//scraper.js
const extractDeal = selector => {
const title = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_name ellipsis'] > span[class='title']")
.text()
.trim();
const releaseDate = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_released responsive_secondrow']")
.text()
.trim();
return { title, releaseDate };
}
Now we will get the deal's link. As we saw before, every item of the deals list is an "< a >" element, so we just need to get their "href" attribute:
//scraper.js
const extractDeal = selector => {
const title = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_name ellipsis'] > span[class='title']")
.text()
.trim();
const releaseDate = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_released responsive_secondrow']")
.text()
.trim();
const link = selector.attr("href").trim();
return { title, releaseDate, link };
}
It's time to get the prices. As we can see in the image below, the original price and the discounted price are inside the same div.
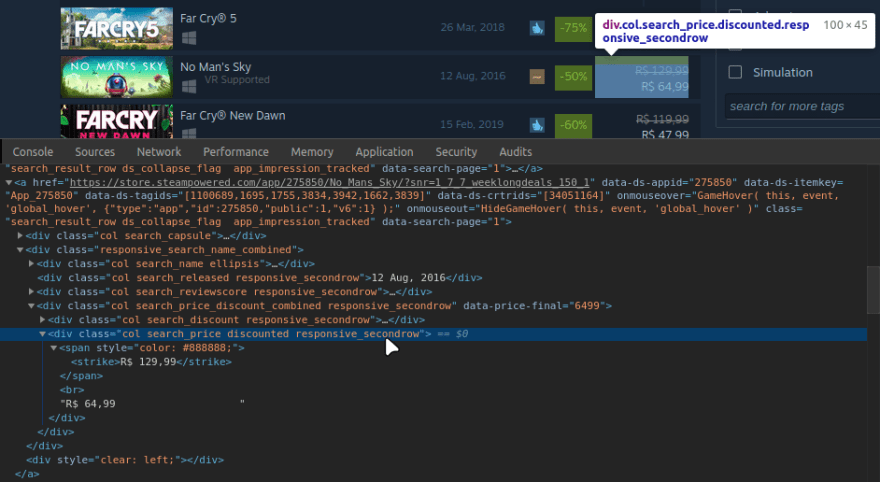
So we will create a custom selector for this div with prices:
const priceSelector = selector
.find("div[class='col search_price_discount_combined responsive_secondrow']")
.find("div[class='col search_price discounted responsive_secondrow']");
And now we will get the original price inside the path "span > strike":
//scraper.js
const extractDeal = selector => {
const title = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_name ellipsis'] > span[class='title']")
.text()
.trim();
const releaseDate = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_released responsive_secondrow']")
.text()
.trim();
const link = selector.attr("href").trim();
const originalPrice = priceSelector
.find("span > strike")
.text()
.trim();
return { title, releaseDate, originalPrice, link };
}
And finally, we will get the discounted price property. But... Notice that this value isn't inside a specific HTML tag, so we have some different ways to get this value, but I will use a regular expression.
//First I'll get the html from cheerio object
const pricesHtml = priceSelector.html().trim();
//After I'll get the groups that matches with this Regx
const matched = pricesHtml.match(/(<br>(.+\s[0-9].+.\d+))/);
//Then I'll get the last group's value
const discountedPrice = matched[matched.length - 1];
Right! Now we have scraped all the properties we want.
Now we just need to export our scrapSteam function and after create our server.
Here is our final scraper.js file:
//scraper.js
const cheerio = require("cheerio");
const axios = require("axios").default;
const fethHtml = async url => {
try {
const { data } = await axios.get(url);
return data;
} catch {
console.error(`ERROR: An error occurred while trying to fetch the URL: ${url}`);
}
};
const extractDeal = selector => {
const title = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_name ellipsis'] > span[class='title']")
.text()
.trim();
const releaseDate = selector
.find(".responsive_search_name_combined")
.find("div[class='col search_released responsive_secondrow']")
.text()
.trim();
const link = selector.attr("href").trim();
const priceSelector = selector
.find("div[class='col search_price_discount_combined responsive_secondrow']")
.find("div[class='col search_price discounted responsive_secondrow']");
const originalPrice = priceSelector
.find("span > strike")
.text()
.trim();
const pricesHtml = priceSelector.html().trim();
const matched = pricesHtml.match(/(<br>(.+\s[0-9].+.\d+))/);
const discountedPrice = matched[matched.length - 1];
return {
title,
releaseDate,
originalPrice,
discountedPrice,
link
};
};
const scrapSteam = async () => {
const steamUrl =
"https://store.steampowered.com/search/?filter=weeklongdeals";
const html = await fethHtml(steamUrl);
const selector = cheerio.load(html);
const searchResults = selector("body").find(
"#search_result_container > #search_resultsRows > a"
);
const deals = searchResults
.map((idx, el) => {
const elementSelector = selector(el);
return extractDeal(elementSelector);
})
.get();
return deals;
};
module.exports = scrapSteam;
So, we will create our Web API /server. I will use Hapi because we don't need much-advanced features for this example, but it's still free to use Express, Koa or whatever framework you want.
run:
yarn add @hapi/hapi
or if you use npm :
npm i @hapi/hapi
I copied and pasted the example of the Hapi documentation into a new file called app.js. Then, I created a route for "/ deals", imported and called our scrapSteam function:
//app.js
const Hapi = require("@hapi/hapi");
const scrapSteam = require("./scraper");
const init = async () => {
const server = Hapi.server({
port: 3000,
host: "localhost"
});
server.route({
method: "GET",
path: "/deals",
handler: async (request, h) => {
const result = await scrapSteam();
return result;
}
});
await server.start();
console.log("Server running on %s", server.info.uri);
};
process.on("unhandledRejection", err => {
console.log(err);
process.exit(1);
});
init();
Now, you can run your app using:
node app.js
To see the results visit localhost:3000/deals:
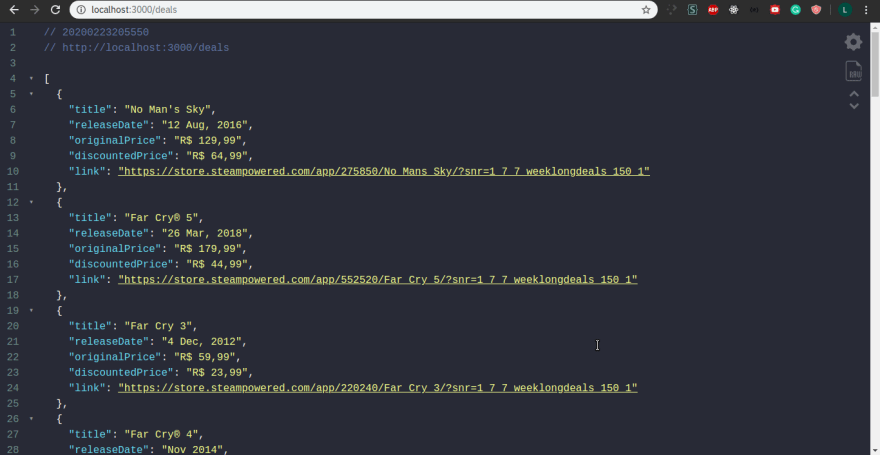
Notes:
1- Depending on when you are reading this article, it is possible to obtain different results based on current "Weeklong Deals";
2- Depending on where you are, the currency and price information may differ from mine;
3- My results are shown in this format because I use Json Viewer extension with the Dracula theme.
You can find the source code in my repo.
I hope this article can help you someday. : D
Feel free to share your opinion!




Top comments (4)
This was what I was looking for. I mean for this article which show use of axios and cheerio together, I scraped the web manually. 👍😊
Muito show! Estou iniciando uma pesquisa no tema e me ajudou bastante :)
Que ótimo! Fico feliz em saber que pude te ajudar de alguma forma xD
Hello if you deploy to heroku not working
You can test scrapping on local but not working on heroku
Any Suggestion