If one of the promise of microservices is greater development is greater productivity, then why do most companies find that microservices are slowing them down?
The answer is often: we divided the monolithic application into microservices at the wrong boundaries.
Where did we go wrong?
Here's the tip:
Stop using domain decomposition as your sole criteria.
Hold on a sec, I thought that domain decomposition was the standard way to break up a monolith? Why is it a problem?
While it's important to understand the business needs, there is a better technique (read below). The reason why domain decomposition alone can be dangerous is because it can cause:
- slow delivery of value as a result of having to deploy and promote multiple microservices whenever a new feature is developed
- late feedback of bugs due to the distributed nature of microservices
- put nicely, this means:

- put nicely, this means:
Okay, so how should we divide the monolith?
Ask yourself this question:
If I divide the monolith this way, will I have to deploy two or more pull requests every time I want to make a substantial change?
I do not claim to be an expert in this matter. But I'll let my favorite architect speak to this topic in this tweet:
 Stefan Tilkov@stilkov
Stefan Tilkov@stilkov “Microservices” are building blocks of an architectural style where deployment boundaries are a first-class software architecture principle08:29 AM - 09 Sep 2016
“Microservices” are building blocks of an architectural style where deployment boundaries are a first-class software architecture principle08:29 AM - 09 Sep 2016


Surely, there are many experts who have spoken on this (and I'd encourage you to share your favorite links in the comments). However, I have lived through the monolith -> microservices transformation at a few companies.
What I've learned is that you have to constantly think about developer productivity when considering how you'll break the monolith into separate microservices.
How do I factor developer productivity into my designs?
Solution 1: Pull request heatmap
One way is to look at your previous pull requests (PRs) in the monolith.
Ask yourself, "which of the proposed microservives are being touched with this change?"
That "gut-level check" question can be answered somewhat objectively by looking at commit history. If you already are in a "nano service" landscape where you microservices have been sliced-and-diced to thinly, you can use Github commit graphs to see the frequency of commits to each microservice. You can then turn that into a heatmap to see which microservices
In the absence of git commit data, you'll need to rely on thinking through the flows of functionality and which parts of the system are touched. This is essentially a simplistic version of event storming (which is beyond the scope of this article), but we'll look at how an event passes through the system. The emphasis is on functionality as opposed to entities (i.e. like the distinction between typical hierarchical object oriented design versus functional programming).
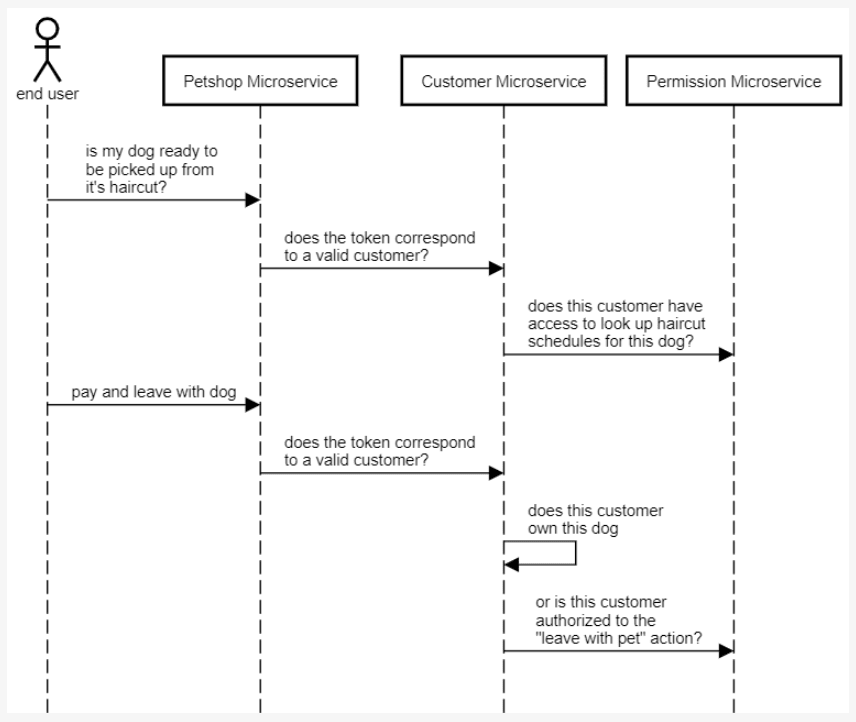
For instance, imagine that we have one PR that introduces the functionality to let an end user check if a pet is ready to be picked up from their haircut appointment. In the past, the sequence diagram for this would have looked like one large box since it was just a monolithic application.
But when you think back to the PR for this schedule lookup feature and you consider the potential microservices that would be necessary, you might see that your "customer" microservice and your "permissions" microservices have to be touched whenever you want to introduce a change.
Let's further this point by introducing a feature that involves paying for the haircut. The sequence diagrams again that your deployment boundary is essentially the entire system. So why even have separate microservices?
Solution 2: look through the lens of testing
While reviewing the flow of functionality in your system, you can also think: "How am I going to test this?"
Deeper questions for that same thought process involve:
- if we separate the customer DB from the permissions DB, is there a way for us to test the end-to-end functionality easily?
- if we don't have end-to-end tests for this functionality, are we willing to invest in the cost of contract testing?
- are we willing to make sure that every one of our APIs is upholding that contract and updating all consumers? (I mean, you always should, but this might not be achievable for smaller companies)
- if don't plan to use end-to-end tests or contract testing, are you willing to invest in running containerized versions of each dependency in the PR to get fast-feedback?
- if you can't find any way to get fast-feedback (i.e. the PR being rejected by a failing automation test), are you willing to let bugs get into the hands of the end user?
Hopefully the answer to the last question is always "no."
So what would the ideal breakdown of the monolith look like?
I don't have a simple, general answer. But I feel confident that you will be able to define better boundaries than ever before if you ask yourself those test-driven questions above and continue to place emphasis on flows not entities.





Top comments (0)