I provided a brief introduction to coupling in part 1. This article is specifically aimed at coupling in object-oriented systems.
There are academic ways of Measuring Cohesion and Coupling of Object-Oriented Systems. And there are formal explanations of types of coupling and cohesion and complexity metrics.
I’m ignoring academia and formality and measures. I’ll explain the types of relationships in object-oriented systems that create complexity. This complexity is often a large component of technical debt. I’ll refer to all types of relationships as coupling even when it’s not formally the correct term.
There is a lot of theory on reducing coupling with tools like encapsulation, inheritance, and abstraction. I am writing about what I’ve experienced in decades of practice which does not always match the promises of theory.
Relationship Example
I had a client with 100s of Java applications and 1000s of packages intended to be reused wherever needed. One of my tasks was to extend “App 1” (in the diagram) to include features from “Package B”.
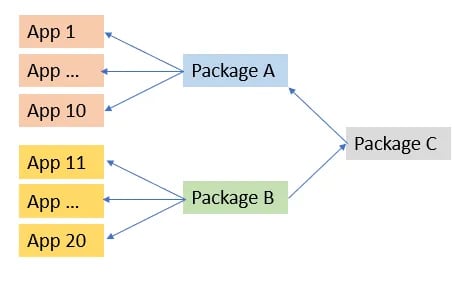
B was used pretty heavily in many apps without issue, so this should be easy. But it wasn’t.
To keep this short, A acted weird after B was added to App 1. And nobody knew much about C. And there were a dozen other packages that were just as likely to be the problem.
We finally figured out that if there were no explicitly configurated properties for C, it chose defaults that were altered by an optional dependency injection that B provided.
There are many ways this could have been avoided. And it could have been a reasonable implementation when C was created.
Configuration issues are not a problem that is specific to object-oriented systems. This example is not meant to show OO or DI is bad. But that there are hidden relationships as well as explicit dependencies involved in the coupling among parts of the system. And also, because of the number of packages, classes, and interfaces used by the app, it’s unlikely that documentation of C would have helped to find the issue.
chatGPT tells me
To minimize coupling, developers can use techniques such as encapsulation, abstraction, and inheritance, which promote modularity and loose coupling between different parts of the system.
While this is true, a little loose coupling can cause trouble. And a lot of loose coupling makes a system difficult to maintain and extend.
Interfaces
Interfaces can be used to reduce coupling.
In this diagram, ConsumerA only depends on the interface. In theory, any of the implementations can be provided to a ConsumerA object and it will work.

In practice, there are many relationships in a code base with these items. There are many things that may cause problems in the future:

A necessary change to InterfaceA requires changes to all implementations
A new implementation may follow the interface contract, but not the intent. It just happens to be an easy hook into consumers, so it is used.
ImplB is modified and causes performance issues with consumers
ImplC has side effects. It’s usually used for other things but a DI change causes it to be injected into a consumer which breaks because of the side effects.
Interfaces are great and have many uses. Most will not cause problems, but in a project with dozens or hundreds of global interfaces, it’s easy to have a few that cause problems in version 2, or 3, or N.
Interfaces can reduce coupling if used well. But a little thought of scope and functionality during architecture design can reduce the chance of future problems. It’s not a simple matter of “create an interface and coupling is reduced”.
Data
Data is usually encapsulated so users of a class cannot access fields directly. While this provides some protection, it is a relationship that can break in the future.
In this diagram, the Base class implements virtual methods getA() and setA(). SubclassB overrides them.

There are a few relationships that need to be considered:
Type of field A: If this changes, it will require changes anywhere Base get/setA() is used.
Implementation of SubclassB: this subclass may have (or add) constraints that break ConsumerA. If ConsumerA is given a Base object, the writer may not be aware that SubclassB.setA() is different than Base.setA()
SubclassA: this subclass may be changed to override getA() and setA() with constraints or modifications. While there is no coupling at this time in the code, there is a relationship in the architecture that may cause issues.
SubclassC: As with interfaces, future subclasses may be created which match the contract of getA() & setA() but have side effects or performance issues.
When architecting a class hierarchy it’s good to consider why getters and setters are created. Do consumers really need access? Can the scope be limited (package, subclass)? I’ve heard arguments for including getters and setters
It makes the class more flexible when consumers can access the data. Encapsulation protects the data so why not?
While this is true, it also adds coupling now or potentially in the future. The class designer should determine what consumers will need and why. It takes more thought in the architecture/design phase but limits potential complexity to be intentional about data access.
Methods
Methods have a similar coupling as data getters and setters, including future relationships from being virtual.
Any method which is called from within a class, or a subclass, or an external class is a relationship. If it is not called but is within scope, it is a possible future relationship.

As with data, a broader scope makes the class more flexible since coders of external classes can decide when and how a method is used. A good class design considers not only why a method exists, but when, where, and how the method should be used. Leaving those decisions up to consumers leads to complexity and often misuse of classes which becomes difficult if not impossible to untangle.
One way to significantly reduce virtual method complexity is to make all virtual methods protected. A common virtual method pattern is to make the virtual method public and use it in the subclass
public override int methodA(int b)
{
var result = base.methodA(b);
/* do more */
return result;
}
This creates a heavy coupling between consumers calling methodA and any implementation. It also allows a subclass to not call base.methodA() – intentionally or accidentally. Even if the base implementation does nothing now, in the future it may add validation or calculations, or any number of other functionality that it expects subclasses to call.
It is better to have a base public methodA that is not virtual. It will always be in control and subclasses only need to implement what they need
internal class BaseB
{
private int a;
public int methodB(int b) {
if (!isValid(b))
{
throw new ArgumentException();
}
setupB(b);
doMethodB(b);
cleanupB(b);
return a;
}
private bool isValid(int b) { return b >= 0; }
protected virtual void setupB(int b) { }
protected virtual void doMethodB(int b) { a = b; }
protected virtual void cleanupB(int b) { }
}
This looks like more effort than a public methodB(). But it only needs to be implemented once. All subclasses are guaranteed to call
- isValid
- setupB
- cleanupB
in the correct order. Consumers are guaranteed that argument validation is called and that any necessary setup and cleanup is performed. Additional mandatory functionality can be added to the base class in the future without the possibility of subclasses not calling the base method. There are many other advantages that may come up over multiple versions of an application. It may only occur in a small percentage of classes, but it can be very helpful to add code to the base class and be guaranteed that it will be called for every subclass and in the right order. Some of these areas are
- logging
- resource management (open/close files, create/free drawing contexts)
- monitoring & metrics
- performance (timeout, caching, etc)
- synchronization
With no public virtual methods, users of the class only have tight coupling to a single known base class. It’s possible for subclasses to cause problems, but it’s much less likely when they implement the minimal polymorphic functionality and the base class guarantees documented common functionality.
Dependency Injection
Dependency Injection is very powerful for many things from testing to configurable runtime implementations. It also can create relationships and chains of relationships that neither the dependent class nor the dependency class has considered.
It provides a simple way to create proxy classes to execute a method remotely or add validation, logging, or any number of other extensions without modifying the dependency class. The proxy class (or alternate implementation) can also add
- performance issues
- stability issues
- security issues (logging a password)
- synchronization issues
When DI is used to create architected configurations of components it is powerful. When it is used to put components together in a way the injector decides is appropriate it’s easy to end up with unknown relationships and complexity.
The runtime architectural structure should be intentional. Stability is difficult when the structure is a result of many independent injection requests.
Client-Server
It’s common to share components on a client and server. Whether its
- data structure
- class design
- class implementation
it is very tempting to have both sides of an API use the same thing. This can happen with a web front end using a nodeJS API. Or with microservices calling each other in any language. It certainly speeds up development when the same component can be used on both sides.
It’s easy to end up with one side not being architected – it just copies the other side. It’s unlikely that the architecture on both sides ends up as good as it could be. And it’s very likely that there will be future limitations and difficulties because of the tight coupling between the client and server.
This is a specialization of the DRY principle. It’s important to look not just at the what and how, but why the functionality is needed. If the why is different, there is an unnecessary relationship that can be restrictive in the future.
In general, data on the server exists for different reasons than the client (e.g. database CRUD vs UI). It is unlikely that the same classes will be appropriate as the system iterates through versions. It is likely that changes on one side will be limited by the other or cause problems on the other.
Avoidance
Object-oriented systems have many relationships by design. One way to avoid system complexity is to localize useful relationships.
Module & Package Interfaces
Keywords like sealed, internal, final, protected, and private are often avoided because “they make the class/module/package less flexible”. But that flexibility is what leads to unmanageable complexity.
The 2 class designs below have the same number of objects and modules. The one on the right has additional interface objects (rectangles) and all inter-module relationships are isolated to those interfaces.
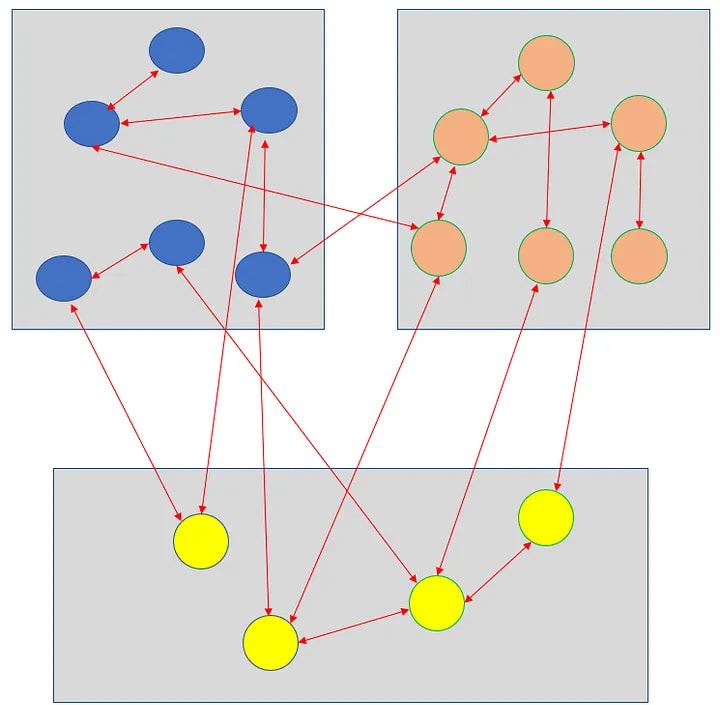

The entire implementation inside of a module can be replaced without risk to other modules on the right design. While that is the idea behind interfaces, what simplifies this design is that the interfaces share data-only objects. There are no relationships between classes in one module and methods of classes in another.
Modules are usually used to group related objects or functionality. They are less often used to isolate complexity, but that is where they are most powerful as an application iterates through multiple versions.
While it’s rarely possible or even desirable to hide module function (i.e. public methods) it is useful to think about the minimal interface (data & methods) a module can expose and still meet its objective.
Access can always be loosened later if necessary (e.g. protected–>public) fairly easily. Tightening access can be much more difficult.
Microservices
I’ve seen microservices used, not to reduce complexity, but because changes made in one part of a monolithic service always break other parts. Instead of requiring all parts of the system to be debugged and deployed together, only the changed service needs to work.
The microservice deployments are a bandaid over a complex monolithic system that is no longer maintainable. There will certainly be shared components of any system with microservices. The components need to have as few relationships as possible in order to avoid the same problems a tightly coupled monolithic system has.
Data Mappers
Learn to love data mappers. In version 1 they may do nothing. Or may make a copy of an object.
Once mapper infrastructure is in place, it is trivial for one component (class, module, client) to change its data structure without impacting others. Each component should use data structures that suit it best, and not make do with objects it is passed using data that is appropriate for another module.
A data mapper may create a new object and copy/transform data from another object. Or it may be a wrapper around another object with restricted access or transformations on get/set. Or an interface that provides a limited view of fields. The most important value of a data mapper is that it encourages the developer to think through the data design for each module rather than using a system-wide entity definition.
API (client-server)
Architect the client and server independently. While the architectures may have a lot in common, the 2 systems serve different purposes and there should be differences in the architecture. This includes data, transformations, functionality, and many other things.
It will be tempting to reuse components (e.g. classes) but think carefully about copy/paste instead of shared classes. For rapid prototyping without much architecture, it can be much quicker to share classes initially. But as soon as you have reached some amount of stability & correctness consider copy/paste to create 2 versions of the same class that can move forward independently in the direction that is best for each side of the API.
Summary
In a large, complex system, it’s important to minimize relationships between components. With tight coupling, changes in one part of the system cascade to others. It can become difficult to make a change anywhere without impacting a significant portion of the rest of the system. Even minor changes are risky because it’s difficult to estimate how they will affect other parts of the system.
In addition, tight coupling (or any coupling) restricts changes that can be made. Or it requires significantly more effort than should be necessary as all of the coupled classes need to be modified as well. And, the higher the coupling in the system, the more the changes cascade causing – requiring changes, testing, and debugging throughout the system.
By nature, an object-oriented system has significant amounts of coupling. Using module boundaries and data mapping can localize coupling complexity and significantly improve the stability of a large system undergoing changes.
If you have any corrections, comments, or suggestions, let me know on Twitter.

Top comments (0)