 video sequence with OpenPose](https://res.cloudinary.com/practicaldev/image/fetch/s--ORd5rolz--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://cdn-images-1.medium.com/max/800/0%2AvLPWgysrOYR7aP5C.gif)
Originally published at Medium on
A lot has been said on OpenPose. This real-time multi-person groundbreaking keypoints detection method has many features, along with:
- 2D real-time multi-person keypoint detection
- 3D real-time single-person keypoint detection
- Calibration toolbox
- Single-person tracking
- Supporting Python API, Unity Plugin, Cuda, OpenCL, and CPU only
Moreover, more features are in the works by the team (Gines Hidalgo, Zhe Cao, Tomas Simon, Shih-En Wei, Hanbyul Joo, Yaser Sheikh, and Yaadhav Raaj) at Carnegie Mellon University. The below link is being updated occasionally for new frameworks’ changes. Besides, it contains an installation guide, troubleshooting, and a quick start section. So, go ahead, have a look, and play with it.
[CMU-Perceptual-Computing-Lab/openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose "https://github.com/CMU-Perceptual-Computing-Lab/openpose)
What 🙋?
One of the caveats of OpenPose framework is to identify a partial human image as determined by my Master’s supervisor, Professor Hagit Hel-Or. The system’s model was trained on human figures taken from several datasets (COCO and MPII), while the images contain different people on various backgrounds, most of them don’t include only “part” of a person image (for example, only shoulders).
It means the algorithm fails to identify the connected graph of all identified body parts. While a body part is an element of the human body (like hand, neck, hip) and a pair is two connected parts.
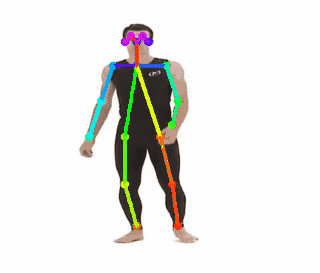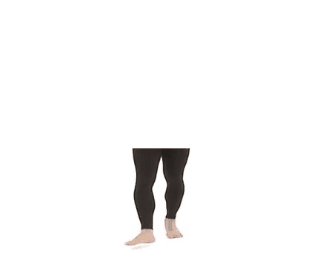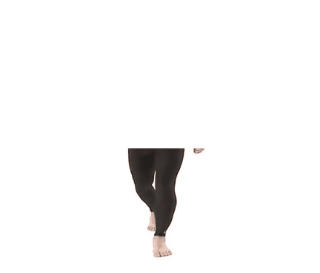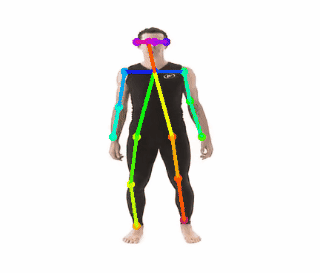
The image below, taken from the excellent Medium blog-posts series by Ale Solano displays the skeletons as represented by the COCO dataset (pairs and parts):
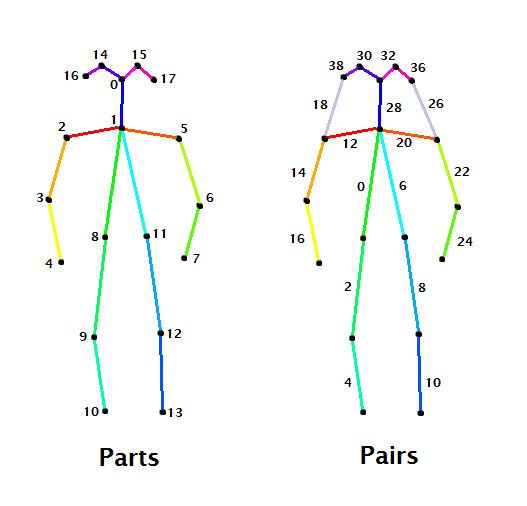
Parts and Pairs indexes for COCO dataset
I recommend reading Ale Solano’s series for more details on OpenPose pipeline which I don’t plan to drill down into as part of this blog-post.
My goal in this opensource project is to allow using the vast capabilities of OpenPose system on images containing only partial body parts. The following GIF emphasizes the framework’s limitation:
Why 🤷?
I intended to learn various concepts to enrich my technical stack, like using machine learning, get a better understanding of computer vision concepts, and using OpenPose. I did all the above while having fun and eventually contributing to the opensource community.
As a side effect, by sorting out OpenPose limitation, it may help other researchers who hesitate using it.
Say, for example, you would like to identify a person’s key points, or as said in the computer vision jargon, skeleton. However, the image appears cut or intentionally contains only part of the human body. One application may be for physical therapy to identify treatment improvements. More usages exist depending on the user’s purpose.
How 🤓?
The proposed method (credit to my Master’s supervisor) is to add the missing body part into the image wisely. Afterward, run the OpenPose framework on the reconstructed image. The result is then manipulated to show the skeleton on the original body image.
The following images show the algorithm flow on an original image of human legs:
- A partial (legs) image is given
- An upper (dummy) image is matched to the original body part, and a merged image is created
- An OpenPose skeleton is generated for the combined image
- The skeleton result is reduced to the original image only
As can be seen below:

The reconstructed image is created by first identifying the object in the original image, using a tensorflow trained model (DetecorAPI with faster_rcnn) based on COCO dataset. The model returns a bounding box of the detected object. Then by using the box’s dimensions, the dummy image is being manipulated to the original image characteristics by an affine transformation.
Eventually, the two images are being stitched together, and OpenPose is being triggered on the new image.
The below video demonstrate the result of a walking person video:


To sum up, OpenPose has great potential for endless applications, enabling motion detection without dedicated hardware like Kinect, a 2D camera is enough. Overcoming on one of the framework limitations can step us forward for that goal, and this is the real power of the opensource community.
I hope you’ll find it interesting (👏).
The project’s code can be found here:

Top comments (0)