
You'd be hard-pressed to find a data scientist who doesn't use pandas for their day-to-day work, but sometimes it pays to go from pandas to NumPy.
Pandas boasts great accessibility and a wide range of tools for small and medium-scale projects, but not all pandas methods utilize vectorization, which reduces the runtime of code. Take the apply() method, for instance. It's essentially a glorified Python "for" loop, and it comes with immense speed constraints, especially with large data sets.
On the bright side, you can speed up many pandas methods by pulling from NumPy. Let's look at how to speed up pandas with NumPy methods using a data notebook.
Use cases for using NumPy methods to speed up pandas
Runtime optimization is crucial in a business context. It directly impacts the performance of programs --- especially bigger, more complex ones.
Just consider the importance of customer experience. If your company's application is powered by a program that runs faster and more efficiently, your end users are bound to be more satisfied. Hence, increased customer loyalty and lifetime value. On the other hand, a sluggish app runs the risk of sending customers to your competitors.
There are also cost savings and scalability to consider. Optimizing the runtime of a program means it will require fewer resources to execute, helping to reduce costs. And as applications grow in size and complexity, runtime optimization becomes even more critical to making sure performance doesn't suffer.
The issue with pandas is that although it supports vectorization, some of its methods don't. This is true for the apply() and groupby() methods. You end up using native Python "for" loops for execution, which slows pandas down.
But NumPy can help improve the performance of pandas in several ways. For instance, if you're performing numerical operations, NumPy offers a suite of numerical functions, including element-wise operations and linear algebra. By using these functions instead of equivalent pandas methods, you can get a performance boost.
Plus, since NumPy provides a high-performance array data structure that is optimized for numerical computations, you can often achieve faster computations when compared to pandas DataFrames. There's also the fact that NumPy arrays are stored in a contiguous block of memory, making them slightly more memory-efficient than DataFrames, which store data in a more complex structure and form.
Using NumPy methods to speed up pandas in a data notebook
Pandas and NumPy are supported across both interactive Python environments and Python scripts. Therefore, runtime optimization can be achieved in either of them.
For this tutorial, we'll be exploring how to go from pandas to NumPy methods in a notebook that has Python installed.
👉 Keep in mind that you can skip the setup process below if you're using a Deepnote notebook. Deepnote comes complete with the most popular data analytics and machine learning Python libraries already installed, so you can seamlessly import them into your project.
Installing pandas & NumPy
To install pandas and NumPy in a Jupyter notebook, run the following command:

Importing pandas & NumPy
Next, to use their methods, we must import them. The commonly used alias for pandas is pd and for NumPy it's np.

Pandas vs. NumPy runtime comparison
First, let's create a dummy data set for experimentation:

Next, let's create a NumPy array with two columns and 10⁸ rows. From this array, we create a pandas DataFrame using the pd.DataFrame method.
The first five rows are shown below:

Pandas apply() vs. NumPy where() for conditional columns
We mostly use the apply() method to create conditional columns in pandas. The implementation is shown below:

We categorize the column as "Class A" if the entry is less than 45 and "Class B" otherwise.

As discussed above, the apply() method is basically a glorified "for" loop. As a result, it misses the whole point of vectorization.
Using NumPy's where() method, we can create conditional columns while also having vectorization in place.

With this method, the condition is passed as the first argument. This is followed by the result if the condition evaluates to True (second argument) and False (third argument). As you can see above, the np.where() method is approximately five times faster.
Pandas apply() vs. NumPy select() for conditional columns
The np.where() method allows us to choose between two results (i.e., it's for binary conditions). If there are multiple conditions, np.select() should be used.
Consider we have the following function:

With the apply() method, we get the following runtime:

But if we use np.select(), we get:
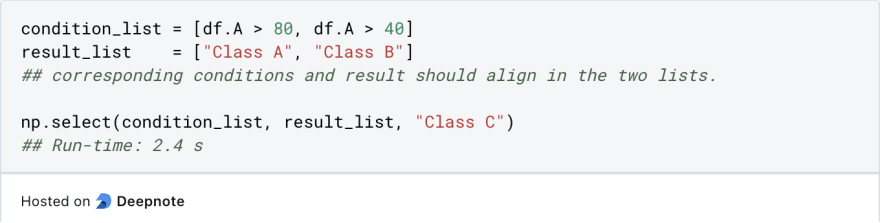
The conditions and the corresponding results are passed as the first two arguments. The last argument is the default result.
You can see that the np.select() method is five times faster than the apply() method. This is because it's using vectorization, while the apply() method is looping through the column to create a new column based on the conditions.
Pandas sort_values() vs. NumPy sort()
Sorting is a common operation to arrange data in a specific order. In pandas, we use the df.sort_values() method to sort a DataFrame.
With the earlier DataFrame, we get the following runtime:

But NumPy also provides a sorting method. More specifically, it's the np.sort() method:

Using NumPy, we first convert the column we want to sort into a NumPy array. Next, we sort the obtained array. Lastly, we create a new DataFrame using the sorted array and rearrange the column entry of the other column.
The NumPy approach is roughly 33% faster than pandas.
Best practices for runtime optimization with pandas & NumPy
Optimization is important, but it's also important to proceed with caution.
It's always a good practice to profile your code first so you're aware of the bottlenecks. If you optimize your code before profiling it, you may end up optimizing the wrong parts, making it even slower.
The biggest bottlenecks in pandas usually come from looping through a DataFrame. Thus, look for parts that can be replaced with vectorization.
Additionally, getting support from external libraries can offer many benefits as well. They're often optimized for performance and can be faster than custom implementations.
Lastly, ensure that you don't compromise the readability of your code for optimization. Optimizing your code can sometimes make it less readable, which makes it harder for other people to understand and maintain it.
In general, you should only move forward with optimization if you have evidence from profiling that your code is slow and that optimization will lead to a significant performance boost.
Combine pandas & NumPy with Deepnote
Get started for free to explore, collaborate on, and share your data.

Top comments (0)