
Paperspace est une plateforme de développement ML et de cloud computing haute performance pour la création, l’entraînement et le déploiement de modèles d’apprentissage automatique.
Des dizaines de milliers de particuliers, de startups et d’entreprises utilisent Paperspace pour itérer plus rapidement et collaborer sur des moteurs de prédiction intelligents et en temps réel.
Gradient est un produit Paperspace destiné aux développeurs à tous les stades du cycle de développement de l’apprentissage automatique.
La façon la plus rapide de commencer à utiliser Gradient est de suivre le tutoriel de l’un des trois points d’entrée de Gradient.
Gradient - Machine Learning Platform | Paperspace
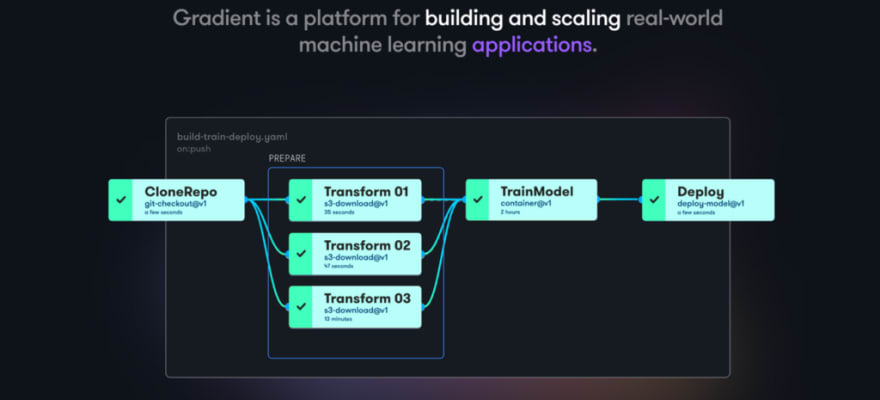

Gradient propose d’ailleurs en Free tier une carte GPU QUADRO M4000 avec 8 CPU et 8 GB de mémoire vive.
https://medium.com/media/2d0e02e91f2b194404044466245e2ab0/href

C’est ce que je vais utiliser avec la création d’un notebook via Jupyter Lab :

Avec les détails du conteneur Docker utilisé ici :
La machine avec 32 Gb de mémoire vive est ici prête :

Je peux directement lancé le Notebook Jupyter :

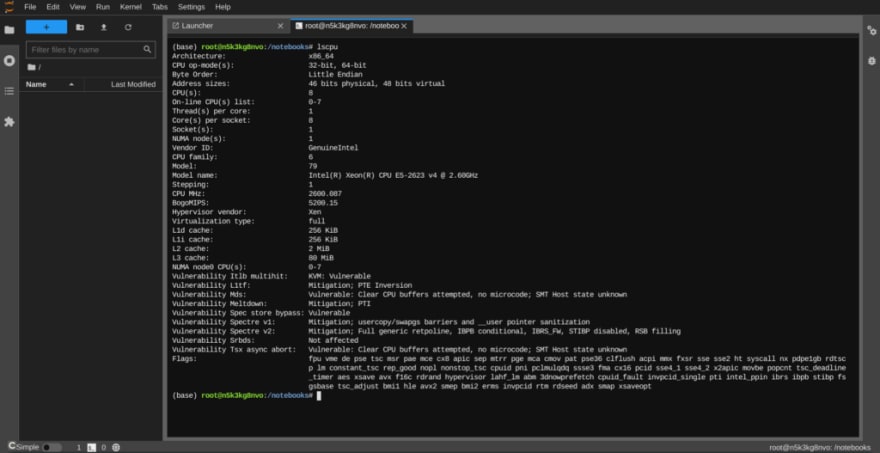
Le Kernel Julia est disponible via le conteneur Jupyter Datascience de Paperspace :
Le multi-threading de Julia fournit la capacité de programmer des tâches simultanément sur plus d’un thread ou d’un cœur de CPU, en partageant la mémoire. C’est habituellement la manière la plus facile d’obtenir du parallélisme sur un PC ou sur un grand serveur multi-core.
Le multithreading de Julia est composable. Quand une fonction multithread appelle une autre fonction multithread, Julia planifiera tous les threads globalement sur les ressources disponibles, sans sursouscription.
J’ajoute donc les 8 coeurs dans IJulia avec cette formule :
using IJulia
installkernel("Julia (8 threads)", env=Dict("JULIA_NUM_THREADS"=>"8"))

J’ai donc ensuire un notebook IJulia disponible avec 8 coeurs :


Je disponse donc ici d’une carte GPU NVIDIA que je peux surveiller via Nvitop :
pip3 install git+[https://github.com/XuehaiPan/nvitop.git#egg=nvitop](https://github.com/XuehaiPan/nvitop.git#egg=nvitop)
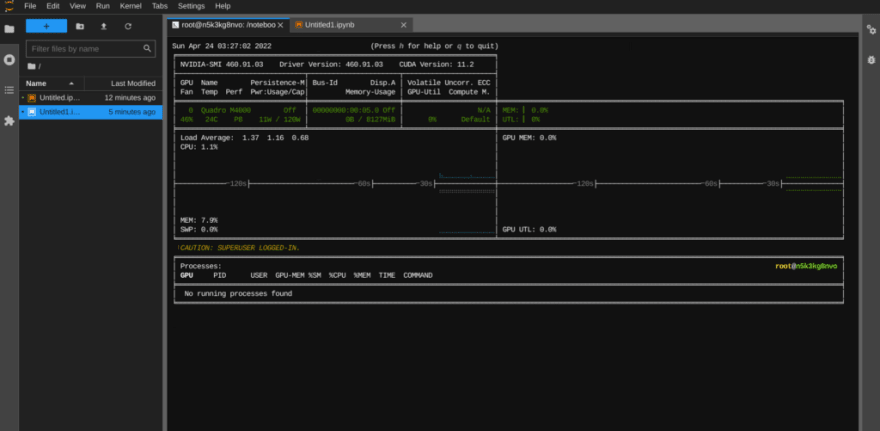
# nvitop -m full --force-color
Je commence par installer FluxArchitectures.jl, un package qui contient un ensemble d’architectures de réseaux neuronaux (légèrement) plus avancées, principalement axées sur la prévision des séries temporelles et basées sur Flux.jl, une bibliothèque pour l’apprentissage automatique :
using Pkg
Pkg.add(["Plots","FluxArchitectures"])


Je pars d’un premier exemple avec LSTnet, “réseau de séries chronologiques à long et à court terme” basé sur l’article de Lai et. al avec cette architecture :

et ce code en Julia :
using FluxArchitectures, Plots
[@info](http://twitter.com/info) "Charger les données"
poollength = 10
horizon = 15
datalength = 1000
input, target = get_data(:exchange_rate, poollength, datalength, horizon) |> gpu
[@info](http://twitter.com/info) "Creation de modèle et perte"
inputsize = size(input, 1)
convlayersize = 2
recurlayersize = 3
skiplength = 120
model = LSTnet(inputsize, convlayersize, recurlayersize, poollength, skiplength, init=Flux.zeros32, initW=Flux.zeros32) |> gpu
function loss(x, y)
Flux.reset!(model)
return Flux.mse(model(x), y')
end
cb = function ()
Flux.reset!(model)
pred = model(input)' |> cpu
Flux.reset!(model)
p1 = plot(pred, label="Prediction")
p1 = plot!(cpu(target), label="Données réelles", title="Pertes $(loss(input, target))")
display(plot(p1))
end
[@info](http://twitter.com/info) "Début de Perte" loss = loss(input, target)
[@info](http://twitter.com/info) "Début de l'entrainement"
Flux.train!(loss, Flux.params(model),Iterators.repeated((input, target), 20), ADAM(0.01), cb=cb)
[@info](http://twitter.com/info) "Perte finale" loss = loss(input, target)
On remarque ici que CPU et GPU sont utilisés pour ce modèle … Les ensembles de données proviennent de ce dépôt et ici on part de la collection des taux de change quotidiens de huit pays étrangers dont l’Australie, la Grande-Bretagne, le Canada, la Suisse, la Chine, le Japon, la Nouvelle-Zélande et Singapour allant de 1990 à 2016 :
GitHub - laiguokun/multivariate-time-series-data

CPU et GPU sont utilisés ici conjointement et notamment via CUDA.jl.
Le paquet CUDA.jl est le principal point d’entrée pour la programmation des GPU NVIDIA dans Julia. Le paquetage permet de le faire à différents niveaux d’abstraction, depuis les tableaux faciles à utiliser jusqu’aux noyaux écrits à la main utilisant des API CUDA de bas niveau.
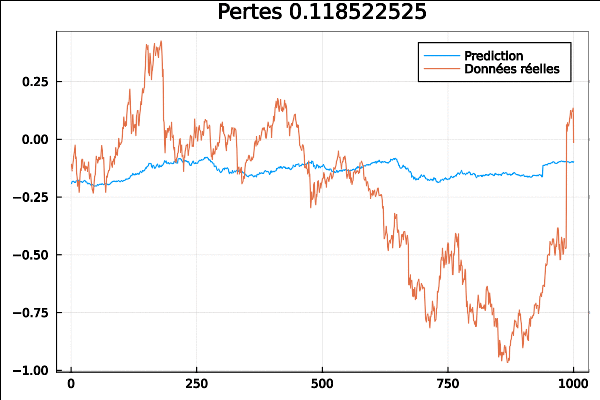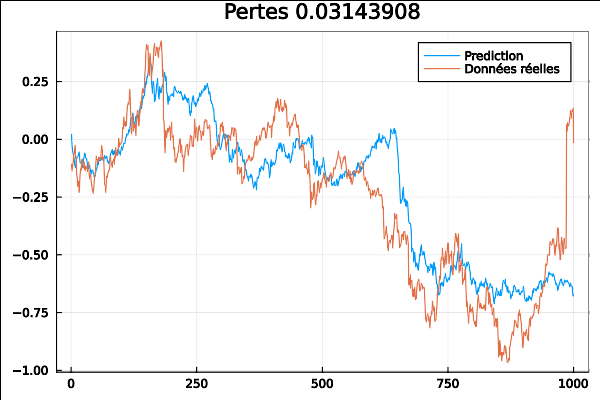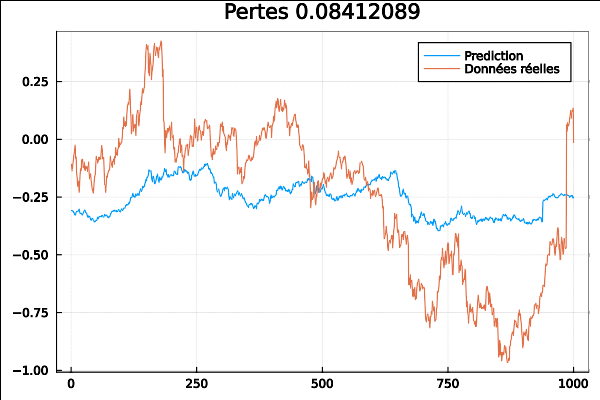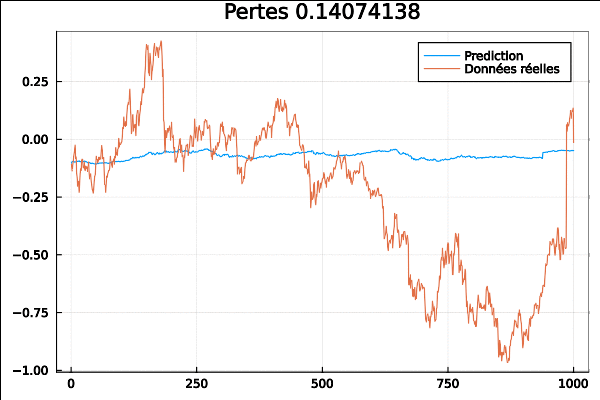
On voit à la fin que courbes de données réelles et de prédiction se rapprochent au fur et à mesure de l’entrainement :

Je passe à un autre exemple avec DARNN ou “Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction” est basé sur l’article de Qin et al :
A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction
Le réseau neuronal a une structure assez complexe. Partant d’une structure d’encodeur-décodeur, il se compose de deux unités, l’une appelée mécanisme d’attention d’entrée, et l’autre mécanisme d’attention temporelle.
- Le mécanisme d’attention d’entrée alimente les données d’entrée à un réseau LSTM. Dans les calculs ultérieurs, seul son état caché est utilisé, où des couches de réseau supplémentaires tentent d’estimer l’importance des différentes variables cachées.
- Le mécanisme d’attention temporelle prend l’état caché du réseau encodeur et le combine avec l’état caché d’un autre décodeur LSTM. Des couches de réseau supplémentaires essaient à nouveau d’estimer l’importance des variables cachées de l’encodeur et du décodeur combinés.
- Les couches linéaires combinent la sortie des différentes couches pour obtenir la prédiction finale de la série temporelle.
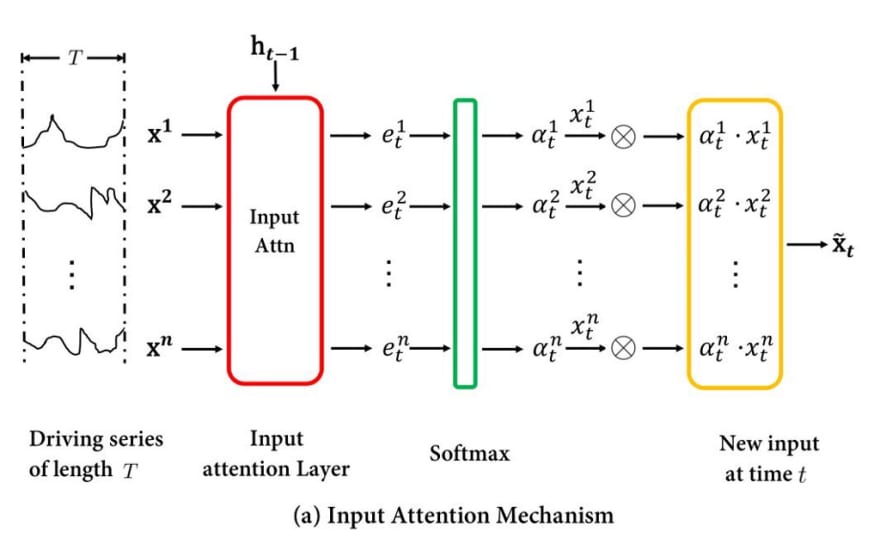
Encoder Structure. Image from Qin et. al., “Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction”, ArXiv, 2017.
La partie décodeur se compose de :
- Une couche de décodeur LSTM. Son état caché est utilisé pour déterminer une mise à l’échelle de la série temporelle originale.
- Une couche d’attention temporelle opérant sur l’état caché de la couche d’encodage, composée de deux couches denses similaires à l’encodeur.
- Une couche dense opérant sur la sortie de l’encodeur et la couche d’attention temporelle. Sa sortie est introduite dans le décodeur.
- Une couche dense pour obtenir la sortie finale basée sur l’état caché du décodeur.

Decoder Structure. Image from Qin et. al., “Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction”, ArXiv, 2017.
Le code est basé sur une implémentation PyTorch du même modèle avec de légers ajustements et on part des données brutes provenant des enregistrements de la production d’énergie solaire en 2006, qui sont échantillonnés toutes les 10 minutes à partir de 137 centrales photovoltaïques dans l’État de l’Alabama :
Solar Power Data for Integration Studies
using FluxArchitectures, Plots
poollength = 10
horizon = 15
datalength = 500
input, target = get_data(:solar, poollength, datalength, horizon) |> gpu
inputsize = size(input, 1)
encodersize = 10
decodersize = 10
model = DARNN(inputsize, encodersize, decodersize, poollength, 1) |> gpu
function loss(x, y)
Flux.reset!(model)
return Flux.mse(model(x), y')
end
cb = function ()
Flux.reset!(model)
pred = model(input)' |> cpu
Flux.reset!(model)
p1 = plot(pred, label="Prediction")
p1 = plot!(cpu(target), label="Données réelles", title="Pertes $(loss(input, target))")
display(plot(p1))
end
[@info](http://twitter.com/info) "Début de Perte" loss = loss(input, target)
[@info](http://twitter.com/info) "Début de l'entrainement"
Flux.train!(loss, Flux.params(model),Iterators.repeated((input, target), 20), ADAM(0.007), cb=cb)
[@info](http://twitter.com/info) "Perte finale" loss = loss(input, target)
la carte GPU est encore très utilisée :

pour fournir les outputs :
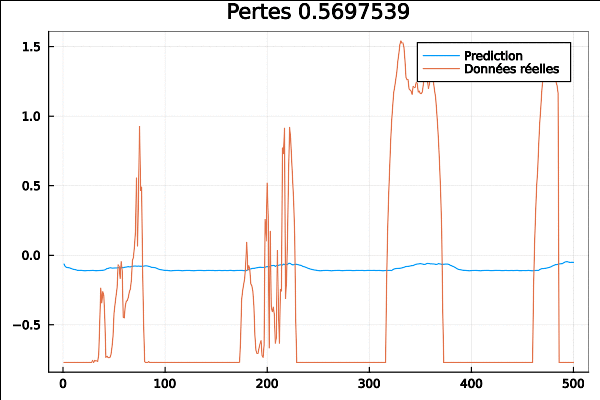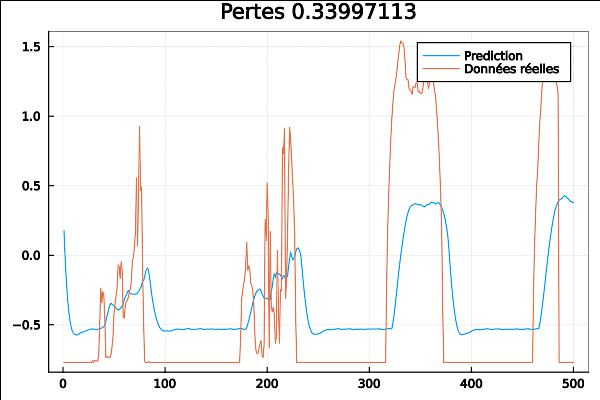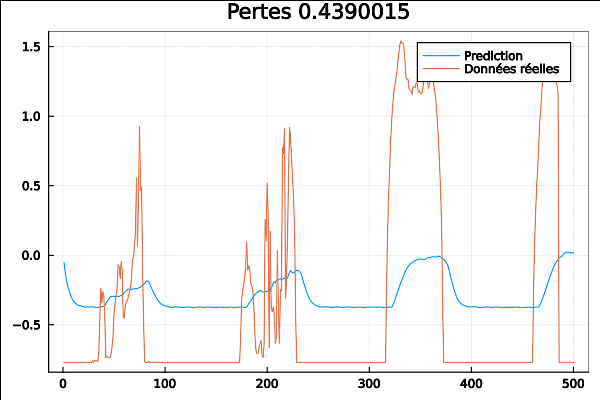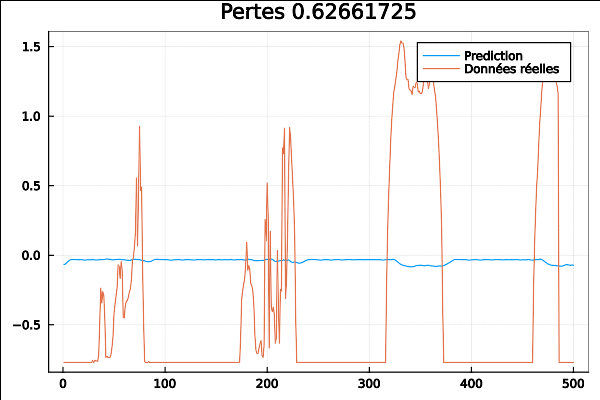

On passe au réseau TPA-LSTM ou “LSTM Temporal Pattern Attention” qui est basé sur l’article “Temporal Pattern Attention for Multivariate Time Series Forecasting” de Shih et. al.
https://medium.com/media/16209ed4c1b28072b68f8ed1ef17ff9f/href
Il prétend avoir une meilleure performance que LSTnet, avec l’avantage supplémentaire qu’un mécanisme d’attention essaie automatiquement de déterminer les parties importantes de la série temporelle, au lieu d’introduire des paramètres qui doivent être optimisés par l’utilisateur.
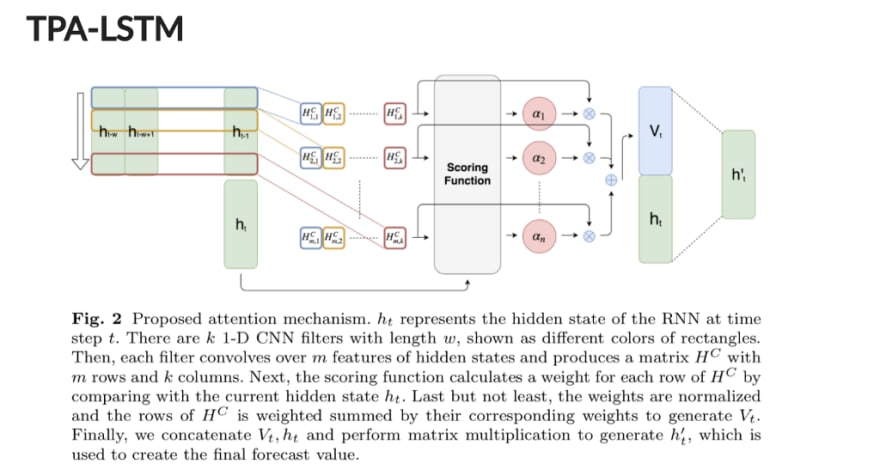
La première partie du réseau neuronal consiste en une couche LSTM encastrée et empilée composée des éléments suivants :
- Une couche d’incorporation dense pour les données d’entrée.
- Une couche LSTM empilée pour les données d’entrée transformées. Le mécanisme d’attention temporelle consiste en
- Une couche dense qui transforme l’état caché de la dernière couche LSTM dans le StackedLSTM.
- Une couche convolutive opérant sur la sortie groupée de la couche précédente, estimant l’importance des différents points de données.
- Une couche dense opérant sur l’état caché du LSTM et la sortie du mécanisme d’attention.
- Une dernière couche dense est utilisée pour calculer la sortie du réseau.
La version empilée d’un certain nombre de cellules LSTM est obtenue en fournissant l’état caché d’une cellule comme entrée à la suivante. La configuration standard de Flux.jl permet seulement d’alimenter la sortie d’une cellule comme nouvelle entrée.
using FluxArchitectures, Plots
poollength = 10
horizon = 15
datalength = 2000
input, target = get_data(:electricity, poollength, datalength, horizon) |> gpu
inputsize = size(input, 1)
hiddensize = 10
layers = 2
filternum = 32
filtersize = 1
model = TPALSTM(inputsize, hiddensize, poollength, layers, filternum, filtersize) |> gpu
function loss(x, y)
Flux.reset!(model)
return Flux.mse(model(x), y')
end
cb = function ()
Flux.reset!(model)
pred = model(input)' |> cpu
Flux.reset!(model)
p1 = plot(pred, label="Prediction")
p1 = plot!(cpu(target), label="Données réelles", title="Pertes $(loss(input, target))")
display(plot(p1))
end
[@info](http://twitter.com/info) "Début de Perte" loss = loss(input, target)
[@info](http://twitter.com/info) "Début de l'entrainement"
Flux.train!(loss, Flux.params(model),Iterators.repeated((input, target), 20), ADAM(0.02), cb=cb)
[@info](http://twitter.com/info) "Perte finale" loss = loss(input, target)
On utilise ici le jeu de données brut provenant de la consommation d’électricité en kWh a été enregistrée toutes les 15 minutes de 2011 à 2014 pour 321 clients. Les données ont été nettoyées et converties en consommation horaire :
UCI Machine Learning Repository

On obtient la simulation suivante :
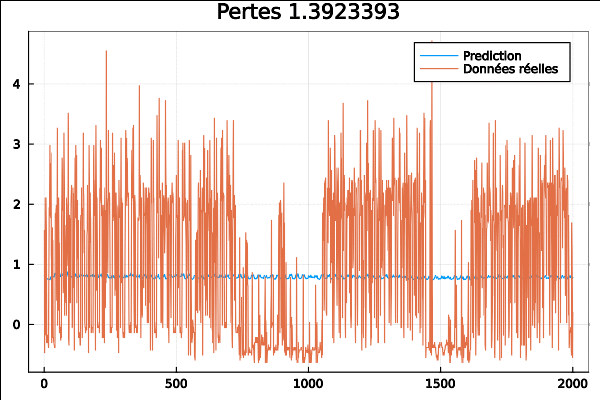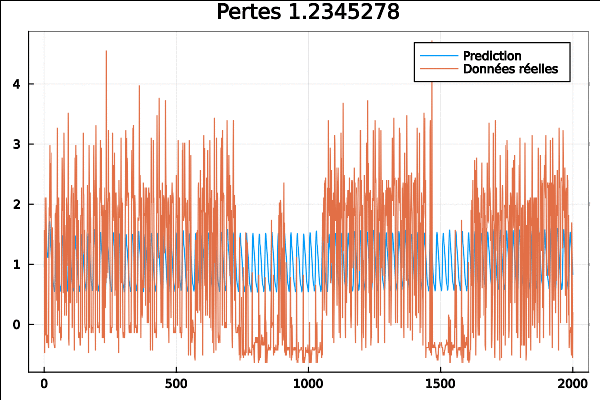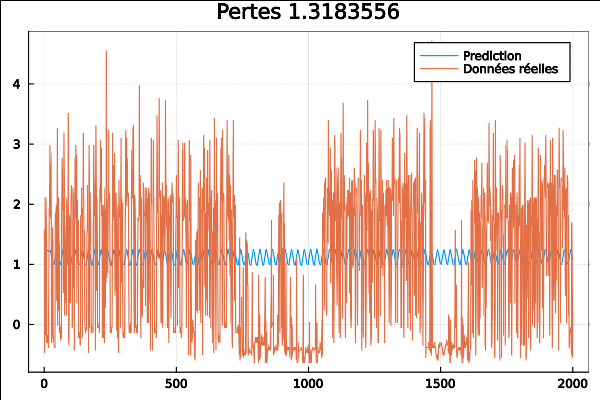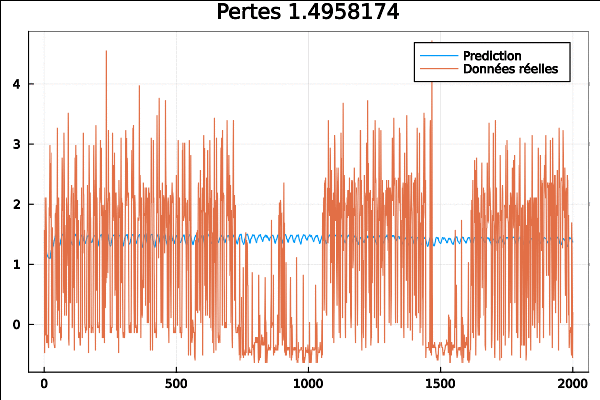

Le même code mais avec cette fois-çi les données issues d’une collection de données horaires sur 48 mois (2015–2016) provenant du département des transports de Californie. Les données décrivent les taux d’occupation des routes (entre 0 et 1) mesurés par différents capteurs sur les autoroutes de la baie de San Francisco.
using FluxArchitectures
using Plots
[@info](http://twitter.com/info) "Chargement des données"
poollength = 10
horizon = 15
datalength = 2000
input, target = get_data(:traffic, poollength, datalength, horizon) |> gpu
[@info](http://twitter.com/info) "Création modèle et Perte"
inputsize = size(input, 1)
hiddensize = 10
layers = 2
filternum = 32
filtersize = 1
# Definir le réseau neuronal
model = TPALSTM(inputsize, hiddensize, poollength, layers, filternum, filtersize) |> gpu
function loss(x, y)
Flux.reset!(model)
return Flux.mse(model(x), permutedims(y))
end
cb = function ()
Flux.reset!(model)
pred = model(input) |> permutedims |> cpu
Flux.reset!(model)
p1 = plot(pred, label = "Prediction")
p1 = plot!(cpu(target), label = "Données réelles", title = "Pertes $(loss(input, target))")
display(plot(p1))
end
# Training loop
[@info](http://twitter.com/info) "Début Perte" loss = loss(input, target)
[@info](http://twitter.com/info) "Début de l'entrainement"
Flux.train!(loss, Flux.params(model), Iterators.repeated((input, target), 50),
ADAM(0.02), cb = cb)
[@info](http://twitter.com/info) "Fini"
[@info](http://twitter.com/info) "Perte finale" loss = loss(input, target)

Il manque ici DSANet, ou “Dual Self-Attention Network for Multivariate Time Series Forecasting” qui est basé sur l’article de Siteng Huang et al.
https://medium.com/media/515473ffdb3684973599eb5b5a464e54/href
Le réseau neuronal se compose des éléments suivants :

- Une partie autorégressive.
- Un mécanisme de convolution temporelle locale, alimenté par une structure d’auto-attention.
- Un mécanisme de convolution temporelle globale, alimenté par une structure d’auto-attention.
Le code suivant peut être ajouté mais DSANet souffre de certaines instabilités numériques. Les paramètres suivants donnent un exemple :
using FluxArchitectures
using Random
using Plots
[@info](http://twitter.com/info) "Chargement des données"
poollength = 10
horizon = 15
datalength = 4000
input, target = get_data(:traffic, poollength, datalength, horizon) |> gpu
inputsize = size(input, 1)
local_length = 3
n_kernels = 3
d_model = 4
hiddensize = 1
n_layers = 3
n_head = 2
[@info](http://twitter.com/info) "Creation modèle et perte"
Random.seed!(42)
model = DSANet(inputsize, poollength, local_length, n_kernels, d_model,
hiddensize, n_layers, n_head) |> gpu
┌ Info: Chargement des données
└ @ Main In[29]:5
┌ Info: Creation modèle et perte
└ @ Main In[29]:21
DSANet(862, 10, 3, 3, 4, 1, 3, 2)
En conclusion, on peut aussi s’intéresser au projet JuliaDynamics qui propose notamment TimeseriesPrediction.jl.
Prédire les séries temporelles de systèmes chaotiques peut être une tâche très difficile. La plupart des méthodes employées pour un tel exploit reposent généralement sur de grands réseaux neuronaux et sur l’apprentissage automatique. Mais on n’en a pas besoin ici !
Dans le paquet TimeseriesPrediction.jl, des méthodes tirent parti de la théorie des systèmes dynamiques et notamment la “modélisation locale” (le modèle “local” fait référence au fait que les images (points futurs) du voisinage d’un point sont le seul composant utilisé pour faire une prédiction).
Exemple avec ces notebooks :
https://medium.com/media/0764ef256425097eae14fc89f81230f2/href
https://medium.com/media/0095f3b58c7428c20d20f3f3d087ab39/href

À suivre !

Top comments (0)