
Processing Streaming Twitter Data using Kafka and Spark series.
Part 0: The Plan
Part 1: Setting Up Kafka
Architecture
Before we start implementing any component, let’s lay out an architecture or a block diagram which we will try to build throughout this series one-by-one. As our intention is getting to learn more technologies using one use case, this fits just right.
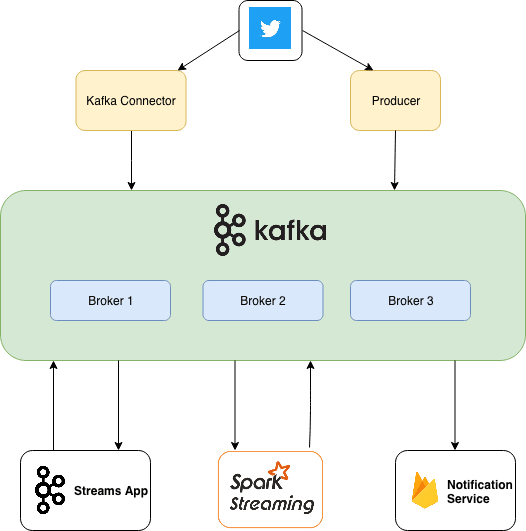
This diagram covers all points I laid out in The Plan. We already finished setting up a Kafka Cluster in Part 1.
In this article, we’ll focus on building a Producer which will fetch latest tweets on #bigdata and push them to our cluster.
What is a Producer?
Everyone may want to use Kafka for different purposes. Some might want to use it as a queue, some as a message bus, while some as a data storage platform. Whatever might be the case, you will always use Kafka by writing a producer that writes data to Kafka, a consumer that reads data from Kafka, or an application that serves both roles.
Kafka has built-in client APIs that developers can use when developing applications that interact with Kafka. In this article we’ll use Producer API to create a client which will fetch tweets from Twitter and send them to Kafka.
A Note from Kafka: The Definitive Guide:
In addition to the built-in clients, Kafka has a binary wire protocol which you can implement in programming language of your choice. This means that it is possible for applications to read messages from Kafka or write messages to Kafka simply by sending the correct byte sequences to Kafka’s network port. Such clients are not part of Apache Kafka project, but a list of non-Java clients is maintained in the project wiki.
Following are the features of the Java Producer API that ships with Kafka:
The producer is thread safe and sharing a single producer instance across threads will generally be faster than having multiple instances.
The producer has a pool of buffer space that holds records that haven’t yet been transmitted to the server
It also has a background I/O thread that is responsible for turning these records into requests and transmitting them to the cluster.
Failure to close the producer after use will leak these resources.
How to fetch latest Tweets?
Twitter provides an open source client called Hosebird(hbc), a robust Java HTTP library for consuming Twitter’s Streaming API.
It is a robust Java HTTP library for consuming Twitter’s Streaming API. It enables clients to receive Tweets in near real-time. Every Twitter account has access to the Streaming API and any developer can build applications using it.
Generating Twitter API Keys
If you don’t have developer access, go to https://dev.twitter.com/apps/new and apply for a Developer access.
Go to https://developer.twitter.com/en/apps and Create a new Application. (Leave callback URL blank)
Go to Keys and tokens tab and copy the consumer key and secret pair to a file for later use.
Click on “Create” to generate Access Token and Secret. Copy both of them to a file.
Now you have all things needed for developing the producer.
Let’s go ahead and start implementing a Kafka Producer Client which will utilize this service. For all those who want to see the completed code, here is the link: https://github.com/dbsheta/kafka-twitter-producer
Create Maven Project
Open IDE of your choice and create a new maven project. I’ll name mine kafka-twitter-producer
Add Kafka,Twitter and Gson dependencies in pom.xml and rebuild the project.
Implement Producer
First of all, let’s define constants to configure Kafka Producer.
Now, we’ll copy the secrets and tokens from Twitter Developer console.
The tweet returned by Twitter API is very large string(json) and contains all details we require for our project. You can find full response here.
We create two entities Tweet and User to hold json responses since it would be easier to work with POJOs than with String responses. At this point, while sending tweets to Kafka, we’ll call toString() on the Tweet object so we don’t have to write serializer for our custom class.
Note: It is better to use a serialization library in such scenarios. We’ll see in a future post, how we can use Avro to serialize/de-serialize java objects while sending to or consuming from Kafka. We’ll discuss benefits of using Avro with Schema registry at that point.
Now, we have all the basic things needed for implementing producer. Let’s start creating TwitterKafkaProducer.
We will initialize our Twitter client in the constructor for our producer class. We have to pass key, secrets and token for authentication. Then we have to pass a list of terms which we want to track. Currently, I’m focused only on #bigdata
This completes the configuration of twitter client. Now we have to configure Kafka producer. I have created below a fairly simple producer.
Let’s go over the main knobs that we turned here. Rest you can easily find in Kafka Documentation and are pretty much self-explanatory.
BOOTSTRAP_SERVERS_CONFIG: List of brokers that act as initial contact point to the cluster. It is advisable to pass more than one broker in case one goes down, producer still should have options to connect to the cluster.
ACKS_CONFIG: 0, 1 or All. ‘0’ means producer doesn’t wait for acknowledgement. ‘1’ means producer waits for leader to acknowledge that it has written to the disk. ‘all’ means producer waits for acknowledgement that all the in-sync replicas have persisted the message. We have used ‘1’ as the data in our case does not require strict acknowledgement. It’s okay for us even if we get one confirmation as data is not that sensitive. Minor loss of data is okay for us.
RETRIES_CONFIG: Number of times producer retires when message fails to be acknowledged (in case acks is set to ‘1’ or ‘all’). Note that setting this to more than 0 may lead to retried message being delivered out of sequence. You may need to turn a few more knobs to ensure same sequence which is out of scope of this article. Interested folks can ask in the comments section.
Streaming Tweets to Kafka Cluster
Now, after configuring twitter client as well as producer, we only need to make a connection to twitter using the client, wait for someone to tweet with #bigdata. Once we get a tweet, send it to kafka using producer.
The client is responsible for fetching latest tweets on #bigdata and push it to BlockingQueue. In the infinite loop, we take one tweet at a time from the queue and push it to kafka by using Tweet ID as key and the whole tweet as value. Since we have used BlockingQueue, queue.take() will block the flow until twitter client fetches new tweet.
Full code available at: https://github.com/dbsheta/kafka-twitter-producer
Lights. Camera. Action.
Let’s see our code in action! First, I will create a new topic bigdata-tweets with replication factor of 2 and number of partitions 3.
> bin/kafka-topics.sh --create --zookeeper X.X.X.X:2181 --replication-factor 2 --partitions 3 --topic bigdata-tweets
> bin/kafka-topics.sh --describe --zookeeper X.X.X.X:2181 --topic bigdata-tweets
Topic:bigdata-tweets PartitionCount:3 ReplicationFactor:2 Configs:
Topic: bigdata-tweets Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: bigdata-tweets Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: bigdata-tweets Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Now, just to verify that the tweets really were persisted by kafka, we’ll start a simple console consumer provided with Kafka distribution.
> bin/kafka-console-consumer.sh --bootstrap-server bigdata-1:9092 --topic bigdata-tweets --from-beginning
Run the TwitterKafkaProducer app. It should start sending data to Kafka.
You should see something like this on your console consumer:
Tweet{id=1059434252306210817, text='I want to assist to meet you and see your latest tools', lang='en', user=User{id=198639877, name='Antonio Molina', screenName='amj_69', location='Moralzarzal-Madrid-Spain', followersCount=399}, retweetCount=0, favoriteCount=0}
Tweet{id=1059434263232348160, text='RT @InclineZA: #AI & #MachineLearning: Building use cases & creating Real-Life Benefits >> https://t.co/noWy1NS3OU
If you see the tweets like these, congrats my friend, you have created one data pipline! You fetched data from a source (Twitter), pushed it to a message queue, and ultimately consumed it (printed on console).
Conclusion
We used Twitter Streaming API along with Kafka Clients API to implement a Producer app which fetches data from twitter and sends it to kafka in real-time. In the next part, we’ll see how we can consume this data to do collect some stats in real-time on streaming data.
Until then…



Top comments (5)
when will you come up with part 3? I would like to know how to use these data fetched from twitter to Kafka, how to use them? any related article?
why spark and not stream dsl/processor api?
Spark has mllib and I have worked with it so it comes as a natural choice to me when I want to analyze large data. Have you tried any machine learning use cases using streams api?
Ha ok, I understood. Yeah I was on a big project that involved
kafka streams for data collection and manipulation + dl4j for ml in java. However the Company collapsed before I could get my hands on the machine learning task :D
However, you should look for stream dsl / processor apis. they are very powerful, native and works in a similar manner to spark topologies
Thanks for the very nice post. I am also waiting for Part 3 of this tutorial, which would use Spark Streaming to do sentiment analysis.