Originally published here by Alexey Ryabov
Estimating story points may be a term you've come across in software development, as it is a common method used by teams to estimate the effort required to complete tasks. Unfortunately, without a deeper understanding of how or why it works, this method can be misused by teams and can even lead to unintended consequences and valuable time wasted.
This article will break down the fundamentals of what story points are and provide a step-by-step guide on how to use them to estimate tasks in software development teams.
Here's what we'll cover:
- What are story points?
- How to estimate in story points?
- Why use story points?
- Examples of using story points
At the end, you will find additional resources that can help you deepen your understanding of story points more.
What are story points?
Story points are an abstract unit of measurement to estimate the overall effort. Story points are a flexible and elegant method as they can take into account different factors based on your team's needs such as time, complexity, amount of work, risks and uncertainties, etc.
The tasks are estimated in story points relative to each other. That's why it's important to have some baseline tasks that you have estimated together with your team and have discussed that estimation in detail. This will serve as a benchmark for everyone to estimate the other tasks.
Story points are usually assigned using a scale such as the Fibonacci sequence (1, 2, 3, 5, 8, 13, 21, etc.). It's not a requirement to use this particular scale, you can use any scale that works for you. The advantage of the Fibonacci sequence is that it's a non-linear sequence that brings the following properties:
- Represents well the idea that estimating a task becomes less precise as the task becomes larger.
- Illustrates well the idea of relative sizing. Using a linear scale (e.g., 1, 2, 3, 4, 5) might give the false impression that each story point is the same amount more complex as the one before. The Fibonacci sequence avoids this pitfall by emphasizing that the relationship between sizes is approximate and non-linear. The ratio between values is more important than the values itself.
How to estimate in story points?
1. Define factors of story points
Before using story points, you need to define what a story point represents. You need to think about which factors are the most important for your team and describe them in detail.
The factors can vary between teams and projects.
In this guide, we will be using the following factors:
⌚ Time
Even though Time isn't usually listed as a factor in other guides, I believe that it's quite an important one for tasks that are clear (usually small tasks). Instead of trying to give a precise amount of time to implement a task, it's better to use an approximate amount which improves the accuracy of estimations and makes it easier to estimate. If it's too hard to predict, we give our estimate based on other factors. If other factors differ a lot from the time, then it can mean that you need to revisit your estimation.
Questions
- How long does it take to complete the task approximately?
Options
- 0 - 2 hours
- 3 - 8 hours
- 9 - 16 hours
- 17 - 26 hours
- 27 - 40 hours
- Unknown
🧠 Complexity
Complexity takes into account such things as a need for special knowledge, clarity of implementation, amount of edge cases, etc.
Questions
- How hard is it to complete this task?
- Do you need special knowledge to complete this task?
- Is the solution clear or does it require some time to come up with a solution?
Options
- Lowest
- Low
- Medium
- High
- Highest
🛠️ Amount of work
Amount of work assesses the sheer volume of work required to complete a task. This factor is quite related to Time but answers different questions. It's often the case when it's hard to estimate time but it's clear that you need to write a lot of code or you need to do some research before implementing a task.
Questions
- Does it require writing a lot of code?
- How much work needs to be done?
- How much do you need to research?
Options
- Lowest
- Low
- Medium
- High
- Highest
💣 Risk and uncertainty
Risk and uncertainty take into account things you can't know until starting a task. For example, you can't envision what issues you will stumble across during an upgrade of some library to a major version even when it has clear release notes.
Questions
- How much is known about a task?
- Is the task clear?
- Is there something that's hard to predict?
Options
- None
- Low
- Medium
- High
- Highest
In the Examples section, we will use those factors, commenting on a decision for each of them.
2. Determine your story point sequence
Your team needs to have a limited set of possible story points to make the estimation process more accurate and easier. It's not that important the actual values of story points. It can be numbers or even letters (e.g. S, M, L, see T-shirt sizing). But the values should be relative to each other and easy to understand.
Some popular choices are:
- Fibonacci sequence (1, 2, 3, 5, 8, 13, 21)
- T-shirt sizing (XS, S, M, L, XL)
It's usually a good idea to have a small set of story points (~5 options) because as an estimate becomes bigger it becomes less accurate. When your estimate is big for a task, it's a good sign that you need to break the task down into smaller tasks and estimate them separately.
In this guide, we will be using the Fibonacci sequence (1, 2, 3, 5, 8).
3. Create a story point matrix
A story point matrix helps your team to estimate tasks by accumulating all the factors. It makes estimations more consistent, helps the team to be on the same page when it comes to estimations and to argue the estimation.
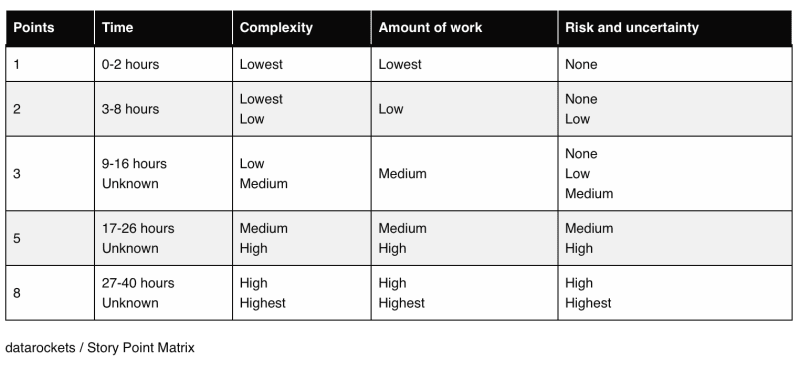
4. Explain the concept to the team
Once you set the definition of a story point, determined a sequence, and created a story point matrix, now it's time to explain it to the team and show how to use it. It's important that each team member understands the concept.
5. Prepare baseline tasks for future estimates
You need to select some tasks that will act as a reference/baseline for future estimates and estimate them in detail together with a team using the matrix. It will simplify the estimation process a lot in the future and will make story points and the matrix much clearer.
The more you use story points, the more accurate estimates become so feel free to change baseline tasks from time to time.
Ideally, you need to have at least one baseline task for each story point value you have.
6. Set up a poker planning session
Poker planning helps to organize the estimation process. The idea of poker planning is that each participant estimates a task in story points privately and the result isn't shown until the voting is over. If the story points are the same, move on to the next task. If the story points differ much, it's time to discuss it together and clarify why participants chose a certain amount of story points.
There are a lot of tools for this. In our team, we use Slack for communication and it has a good extension "Poker Planner for Slack". It has all the configurations we need, it's easy to use, and makes it possible to make the session asynchronous.
7. Execute your sprint and measure its velocity
The beautiful side of estimation is that it allows us to measure a team's velocity. The velocity is the measure of a team's capacity to complete work during a sprint. Story points improve accuracy by having a limited amount of values and taking into account multiple factors. Knowing the team's velocity helps to see potential issues, discuss them with the team, and set realistic goals for the next sprints.
To calculate the velocity, you just need to calculate the total amount of completed story points when a sprint ends. This number is the velocity of your team for the sprint.
After completing several sprints, it's a good idea to measure an average velocity which will help you to understand how many story points you can plan for the next sprints.
Why use story points?
Now, when we know what story points are and how to use them, we can summarize the benefits of story points. Understanding these benefits will shed light on why teams often choose story points over other methods for estimation and planning.
- More Accurate Estimations. Story points help us to estimate tasks more accurately compared to other simple measurements such as time because it takes into account multiple measurements, which often impact the estimations, such as complexity, amount of work, risks and uncertainties. Besides accuracy, it makes it easier to estimate because all the factors are approximate values and a team doesn't need to give precise estimations for each factor.
- Reduced Pressure on Teams. Since story points aren't tied to time only and it's an abstract unit, it reduces pressure on teams which leads to more productive work.
- Improved Team Collaboration. Story points define an exact process for estimating tasks. It involves the whole team into the estimation process and gives a common language for estimating which improves communication. Techniques such as "Poker planning" make the estimation process more efficient and productive.
- Statistics. Story points help the team to analyze their performance by calculating different metrics such as velocity. Having statistics helps us to spot performance issues in advance, discuss it with a team, and plan the next sprints more accurately based on the statistics.
Examples
To better understand story points, let's estimate some tasks together using the matrix from this guide.
Task #1. Use pluralization rules for text
Description
We need to update all instances in the UI where we use a noun with a dynamic number to use a function that automatically applies the appropriate pluralization rule. For example, "1 word", "2 words", etc.
Additional context
We're going to use a library which we've used on other projects before. The codebase is of medium size and it's not hard to search in it.
Estimation
- Time - 0-2 hours. Knowing the existing code base isn't very big, we're pretty sure that this task won't take more than 2 hours.
- Complexity - Lowest. There is nothing complex to implement. We don't need to implement pluralization from scratch since we're going to use a library for that.
- Amount of work - Low. It requires us to go through the codebase and find places where we need to update text.
- Risk and uncertainty - Low. Since we don't know the exact places where we need to update text, there is a small risk of underestimating and having more places than we initially expected.
- Points - 1
Task #2. Add virtualization to feed
Description
We have a feed of users' posts with infinite scroll. We need to implement virtualization in the list to improve its performance when the list becomes large.
Additional context
We're going to use some library for virtualization but we don't know which one yet. The list has items with dynamic height. The code for the feed is readable and written quite well.
Estimation
- Time - 3-8 hours. We don't need to implement the virtualization logic from scratch since we're going to use some library for that. We previously had experience of applying virtualization in previous projects, so we know the general idea and know approximately how much time it can take.
- Complexity - Medium. Virtualization is not a straightforward concept. To successfully apply it, we need to understand how it works. We have a dynamic height for a list item and an infinite scroll, which complicates the usage of virtualization.
- Amount of work - Low. Since we had experience previously using some libraries for virtualization, we know that, in most cases, it doesn't require a lot of changes in the codebase. The code for the feed is written well, and it's easy to change and understand.
- Risk and uncertainty - Medium. We don't know exactly what library we're going to use. There are some risks of something not working as before because it changes drastically the way the feed is rendered.
- Points - 2. Here we have an uncertain situation because the factors we chose don't map to the matrix fully. From the matrix, it should be either 2 or 3. We ended up choosing 2 because everyone was sure that it wouldn't take more than 8 hours, and it was a decisive factor.
Task #3. Implement login page
Description
In the scope of this task, we need to add a new page /sign-in which contains a simple form with email and password fields and a submit button. We need to handle errors from API. We also need to establish architecture for protected/unprotected routes and make the login page available only for unauthenticated users.
Additional context
We're going to use some library for managing forms. We have all basic components like input, button, etc. in UI kit we use.
Estimation
- Time - 9-16 hours. Based on previous experience and taking into account that we're going to use a lot of existing solutions, we think that it won't take more than 16 hours.
- Complexity - Low. It contains pretty common functionality. UI doesn't have anything complex and most of the components are already ready. All the complex form management/validation will handle some library. Amount of work - Medium. We need to do several things, like choosing a library for form management, communicating with API, handling errors from API, implementing an architecture for protected/unprotected routes.
- Risk and uncertainty - Low. It's clear how it should work. We know how to communicate with API. We have experience working with forms, so even though we don't know which library we're going to use, we don't expect a lot of risks from it.
- Points - 3
Task #4. Implement chart on dashboard
Description
We need to implement a chart on a dashboard which shows some statistics. It's a bar chart with a tooltip. The design for the chart is custom.
Additional context
We're going to use some library for building charts but we don't know which one yet. We don't have any experience building charts. We need to implement it to look the same as on the design so we need a library where we can customize the appearance of charts as we need. We need to think about the loading state, empty state. We need to communicate with API.
Estimation
- Time - Unknown. It's hard to estimate how much time it needs since we don't have prior experience in implementing charts.
- Complexity - High. Data visualization isn't an easy concept and requires special knowledge to successfully build custom charts.
- Amount of work - High. We need to find a library which covers all our requirements. We need to learn the found library and learn data visualization in general.
- Risk and uncertainty - High. Since we never did it before, there are a lot of uncertainties and risks. We don't know which library we're going to use, we don't know how hard it's to use that library and which issues it has, we don't know how hard it's to learn data visualization.
- Points - 8. Even though it might not take much time in the end, we still chose 8 because there are a lot of uncertainties.
Additional resources
If you want to understand better story points then I highly recommend to read these articles:




Top comments (0)