As technology advances and data continues to explode, traditional disk file systems have revealed their limitations. To address the growing storage demands, distributed file systems have emerged as dynamic and scalable solutions. In this article, we explore the design principles, innovations, and challenges addressed by three representative distributed file systems: Google File System (GFS), Tectonic, and JuiceFS.
- GFS pioneered commodity hardware use and influenced systems like Hadoop Distributed File System (HDFS) in big data.
- Tectonic introduced layered metadata and storage/compute separation, improving scalability and performance.
- JuiceFS, designed for the cloud-native era, uses object storage and a versatile metadata engine for scalable file storage in the cloud.
By exploring the architectures of these three systems, you will gain valuable insights into designing distributed file systems. This understanding can guide enterprises in choosing suitable file systems. We aim to inspire professionals and researchers in big data, distributed system design, and cloud-native technologies with knowledge to optimize data storage, stay informed about industry trends, and explore practical applications.
An overview of popular distributed file systems
The table below shows a variety of widely-used distributed file systems, both open-source and proprietary.
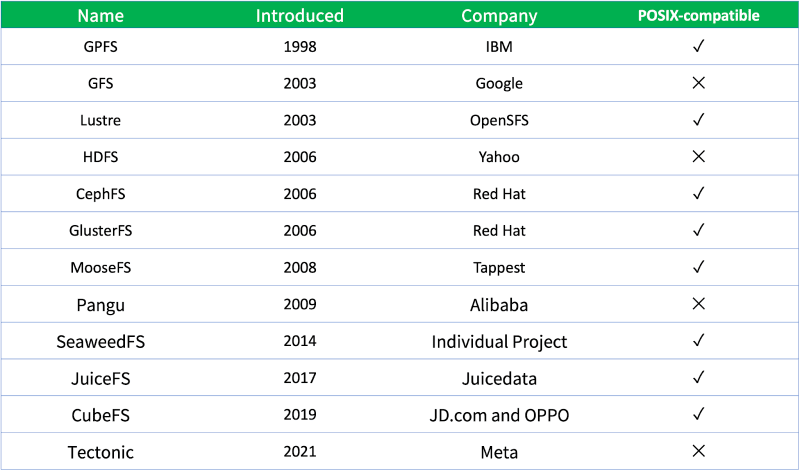
As shown in the table, a large number of distributed systems emerged around the year 2000. Before this period, shared storage, parallel file systems, and distributed file systems existed, but they often relied on specialized and expensive hardware.
The "POSIX-compatible" column in the table represents the compatibility of the distributed file system with the Portable Operating System Interface (POSIX), a set of standards for operating system implementations, including file system-related standards. A POSIX-compatible file system must meet all the features defined in the standard, rather than just a few.
For example, GFS is not a POSIX-compatible file system. Google made several trade-offs when it designed GFS. It discarded many disk file system features and retained some distributed storage requirements needed for Google's search engine at that time.
In the following sections, we’ll focus on the architecture design of GFS, Tectonic, and JuiceFS. Let's explore the contributions of each system and how they have transformed the way we handle data.
GFS architecture
In 2003, Google published the GFS paper.** It demonstrated that we can use cost-effective commodity computers to build a powerful, scalable, and reliable distributed storage system, entirely based on software, without relying on proprietary or expensive hardware resources.**
GFS significantly reduced the barrier to entry for distributed file systems. Its influence can be seen in varying degrees on many subsequent systems. HDFS, an open-source distributed file system developed by Yahoo, is heavily influenced by the design principles and ideas presented in the GFS paper. It has become one of the most popular storage systems in the big data domain. Although GFS was released in 2003, its design is still relevant and widely used today.
The following figure shows the GFS architecture:

A GFS cluster consists of:
- A master, which serves as the metadata node
- To maintain metadata such as directories, permissions, and attributes for a file system, a central node, the master, is used. The master is structured in a tree-like design.
- Multiple chunkservers, which store the data
- The chunkserver relies on the local operating system's file system to store the data.
- Multiple clients
The communication between the master and chunkserver is through a network, resulting in a distributed file system. The chunkservers can be horizontally scaled as data grows.
All components are interconnected in GFS. When a client initiates a request, it first retrieves the file metadata information from the master, communicates with the chunkserver, and finally obtains the data.
GFS stores files in fixed-size chunks, usually 64 MB, with multiple replicas to ensure data reliability. Therefore, reading the same file may require communication with different chunkservers. The replica mechanism is a classic design of distributed file systems, and many open-source distributed system implementations today are influenced by GFS.
While GFS was groundbreaking in its own right, it had limitations in terms of scalability. To address these issues, Google developed Colossus as an improved version of GFS. Colossus provides storage for various Google products and serves as the underlying storage platform for Google Cloud services, making it publicly available. With enhanced scalability and availability, Colossus is designed to handle modern applications' rapidly growing data demands.
Tectonic architecture
Tectonic is the largest distributed file system used at Meta (formerly Facebook). This project, originally called Warm Storage, began in 2014, but its complete architecture was not publicly released until 2021.
Prior to developing Tectonic, Meta primarily used HDFS, Haystack, and f4 for data storage:
- HDFS was used in the data warehousing scenario (limited by the storage capacity of a single cluster, with dozens of clusters deployed).
- Haystack and f4 were used for unstructured data storage scenarios.
Tectonic was designed to support these three storage scenarios in a single cluster.
The figure below shows the Tectonic architecture:

Tectonic consists of three components:
- The Client Library
- The Metadata Store
- The Chunk Store
Layer design in Tectonic
Innovations in Tectonic architecture design
Innovation #1: Layered metadata
Tectonic abstracts the metadata of the distributed file system into a simple key-value (KV) model. This allows for excellent horizontal scaling and load balancing, and effectively prevents hotspots in data access.
Tectonic introduces a hierarchical approach to metadata, setting it apart from traditional distributed file systems. The Metadata Store is divided into three layers, which correspond to the data structures in the underlying KV storage:
- The Name layer, which stores the metadata related to the file name or directory structure, sharded by directory IDs
- The File layer, which stores the file attributes, sharded by file IDs
- The Block layer, which stores the metadata regarding the location of data blocks in the Chunk Store, sharded by block IDs
The figure below summarizes the key-value mapping of the three layers:

This layered design addresses the scalability and performance demands of Tectonic, especially in Meta’s scenarios, where handling exabyte-scale data is required.
Innovation #2: Separation of storage and compute for metadata
The three metadata layers are stateless and can be horizontally scaled based on workloads. They communicate with the Key-Value Store, a stateful storage in the Metadata Store, through the network.
The Key-Value Store is not solely developed by the Tectonic team; instead, they use ZippyDB, a distributed KV storage system within Meta. ZippyDB is built on RocksDB and the Paxos consensus algorithm. Tectonic relies on ZippyDB's KV storage and its transactions to ensure the consistency and atomicity of the file system's metadata.
Transactional functionality plays a vital role in implementing a large-scale distributed file system. It’s essential to horizontally scale the Metadata Store to meet the demands of such a system. However, horizontal scaling introduces the challenge of data sharding. Maintaining strong consistency is a critical requirement in file system design, especially when performing operations like renaming directories with multiple subdirectories. Ensuring efficiency and consistency throughout the renaming process is a significant and widely recognized challenge in distributed file system design.
*To address this challenge, Tectonic uses ZippyDB’s transactional features. When handling metadata operations within a single shard, Tectonic guarantees both transactional behavior and strong consistency. *
However, ZippyDB does not support cross-shard transactions. This limits Tectonic's ability to ensure atomicity when it processes metadata requests that span multiple directories, such as moving files between directories.
Innovation #3: Erasure coding in the Chunk Store
As previously mentioned, GFS ensures data reliability and security through multiple replicas, but this approach comes with high storage costs. For example, storing just 1 TB of data typically requires three replicas, resulting in at least 3 TB of storage space. This cost increases significantly for large-scale systems like Meta, operating at the exabyte level.
To solve this problem, Meta implements erasure coding (EC) in the Chunk Store which achieves data reliability and security with reduced redundancy, typically around 1.2 to 1.5 times the original data size. This approach offers substantial cost savings compared to the traditional three-replica method. Tectonic's EC design provides flexibility, allowing configuration on a per-chunk basis.
While EC effectively ensures data reliability with minimal storage space, it does have some drawbacks. Specifically, reconstructing lost or corrupted data incurs high computational and I/O resource requirements.
According to the Tectonic research paper,the largest Tectonic cluster in Meta comprises approximately 4,000 storage nodes, with a total capacity of about 1,590 petabytes, which is equivalent to 10 billion files. This scale is substantial for a distributed file system and generally fulfills the requirements of the majority of use cases at present.
JuiceFS architecture
JuiceFS was born in 2017, a time when significant changes had occurred in the external landscape compared to the emergence of GFS and Tectonic:
- There had been remarkable advancements in hardware resources. To put it into perspective, the network bandwidth in Google data centers back then was merely 100 Mbps. Today, on AWS, machine network bandwidth can reach up to 100 Gbps, a thousandfold increase.
- Cloud computing had become mainstream, with enterprises transitioning into the "cloud era" through public, private, or hybrid clouds. This shift presented new challenges for infrastructure architecture. Migrating traditional infrastructure designed for IDC environments to the cloud often brought about various issues. Maximizing the benefits of cloud computing became a crucial requirement for seamless integration of infrastructure into cloud environments.
Moreover, GFS and Tectonic were in-house systems serving specific company operations, operating at a large scale but with a narrow focus. In contrast, JuiceFS is designed to cater to a wide range of public-facing users and to meet diverse use case requirements. As a result, the architecture of JuiceFS differs significantly from the other two file systems.
Taking these changes and distinctions into account, let’s look at the JuiceFS architecture as shown in the figure below:

JuiceFS consists of three components:
- The Metadata Engine
- The Data Storage
- The Client
While JuiceFS shares a similar overall framework with the aforementioned systems, it distinguishes itself through various design aspects.
Data storage
Unlike GFS and Tectonic, which rely on proprietary data storage, JuiceFS follows the trend of the cloud-native era by using object storage. As previously mentioned, Meta’s Tectonic cluster uses over 4,000 servers to handle exabyte-scale data. This inevitably leads to significant operational costs for managing such a large-scale storage cluster.
For regular users, object storage has several advantages:
- Out-of-the-box usability
- Elastic capacity
- Simplified operations and maintenance
- Support for erasure coding, resulting in lower storage costs compared to replication
However, object storage has limitations, including:
- Object immutability
- Poor metadata performance
- Absence of strong consistency
- Limited random read performance
To tackle these challenges, JuiceFS adopts the following strategies in its architectural design:
- An independent metadata engine
- A three-layer data architecture comprising chunks, slices, and blocks
- Multi-level caching
Metadata engine
JuiceFS supports various open-source databases as its underlying storage for metadata. This is similar to Tectonic, but JuiceFS goes a step further by supporting not only distributed KV stores but also Redis, relational databases, and other storage engines. This design has these advantages:
- It allows users to choose the most suitable solution for their specific use cases, aligning with JuiceFS's goal of being a versatile file system.
- Open-source databases often offer fully managed services in public clouds, resulting in almost zero operational costs for users.
Tectonic achieves strong metadata consistency by using ZippyDB, a transactional KV store. However, its transactionality is limited to metadata operations within a single shard. In contrast, JuiceFS has stricter requirements for transactionality and demands global strong consistency across shards. Therefore, all supported databases integrated as metadata engines must support transactions. With a horizontally scalable metadata engine like TiKV, JuiceFS can now store over 20 billion files in a single file system, meeting the storage needs of enterprises with massive data. This capability makes JuiceFS an ideal choice for enterprises dealing with massive data storage needs.
Client
The main differences between the JuiceFS client and the clients of the other two systems are as follows:
- The GFS client speaks non-standard protocol and does not support the POSIX standard. It only allows append-only writes. This limits its usability to a specific scenario.
- The Tectonic client also lacks support for POSIX and only permits append-only writes, but it employs a rich client design that incorporates many functionalities on the client side for maximum flexibility.
- The JuiceFS client supports multiple standard access methods, including POSIX, HDFS, S3, WebDAV, and Kubernetes CSI.
- The JuiceFS client also offers caching acceleration capabilities, which are highly valuable for storage separation scenarios in cloud-native architectures.
Conclusion
Distributed file systems have transformed data storage, and three notable systems stand out in this domain: GFS, Tectonic, and JuiceFS.
- GFS demonstrated the potential of cost-effective commodity computers in building reliable distributed storage systems. It paved the way for subsequent systems and played a significant role in shaping the field.
- Tectonic introduced innovative design principles such as layered metadata and separation of storage and compute. These advancements addressed scalability and performance challenges, providing efficiency, load balancing, and strong consistency in metadata operations.
- JuiceFS, designed for the cloud-native era, uses object storage and a versatile metadata engine to deliver scalable file storage solutions. With support for various open-source databases and standard access methods, JuiceFS caters to a wide range of use cases and seamlessly integrates with cloud environments.
Distributed file systems overcome traditional disk limitations, providing flexibility, reliability, and efficiency for managing large data volumes. As technology advances and data grows exponentially, their ongoing evolution reflects industry's commitment to efficient data management. With diverse architectures and innovative features, distributed file systems drive innovation across industries.
Note: This article was originally published on InfoQ on June 26, 2023.




Top comments (0)