
Running any application in production assumes reliable monitoring to be in place and serverless applications are no exception.
As modern cloud applications get more and more distributed and complex, the challenge of monitoring availability, performance, and cost get increasingly difficult. Unfortunately, there isn't much offered right out of the box from cloud providers. Although you can't fully understand what's happening just with CloudWatch alone, it is a great place to start and have it as the first line of defense for ensuring service availability and performance.
Let's explore the basics and more complex use cases for monitoring your Lambda functions with CloudWatch.
CloudWatch Metrics You Can Gather
CloudWatch gathers basic metrics allowing you to observe how your system is performing.
For Lambda functions, the gathered metrics are: errors, invocations, concurrency, latency, and memory usage. Since it's unlikely that you'll happen to check your metrics at the exact right time when something goes wrong, or about to go wrong, it's good to configure alarms in case some unexpected threshold or condition is met to notify you through various channels.
How to Set Up CloudWatch Metric Alarms
You can configure a CloudWatch alarm to trigger an SNS topic in case a predefined condition is met. That SNS trigger can then invoke a Lambda function which will take action to either notify or possibly fix the situation.
You will need to use CloudWatch Logs subscription and match entries with a specific error pattern in your logs. This way you can automate the task of being notified for errors rather than manually parsing through countless rows of logs.
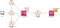

The solution is:
- You define the errors you wish to be alerted on.
- CloudWatch Logs catches those errors and invokes a Lambda function to process the error to alert you via Amazon SNS topic.
Let's configure a basic alarm for when a Lambda function fails for any reason --- here is a simple guide on deploying the above:
Create an SNS topic to configure the email subscription
Create an IAM role and a policy
Create a Lambda function to alert you via SNS (sample code below)
Copyright 2020 Amazon.com, Inc. or its affiliates. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License").
You may not use this file except in compliance with the License.
A copy of the License is located at## http://aws.amazon.com/apache2.0/
or in the "license" file accompanying this file.
This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,
either express or implied. See the License for the specific language governing permissions
and limitations under the License.
Description: This Lambda function sends an email notification to a given AWS SNS topic when a particular pattern is matched in the logs of a selected Lambda function. The email subject is Execution error for Lambda-. The JSON message body of the SNS notification contains the full event details.
Author: Sudhanshu Malhotra
import base64
import boto3
import gzip
import json
import logging
import os
from botocore.exceptions import ClientError
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(name)
def logpayload(event):
logger.setLevel(logging.DEBUG)
logger.debug(event['awslogs']['data'])
compressed_payload = base64.b64decode(event['awslogs']['data'])
uncompressed_payload = gzip.decompress(compressed_payload)
log_payload = json.loads(uncompressed_payload)
return log_payload
def error_details(payload):
error_msg = ""
log_events = payload['logEvents']
logger.debug(payload)
loggroup = payload['logGroup']
logstream = payload['logStream']
lambda_func_name = loggroup.split('/')
logger.debug(f'LogGroup: {loggroup}')
logger.debug(f'Logstream: {logstream}')
logger.debug(f'Function name: {lambda_func_name[3]}')
logger.debug(log_events)
for log_event in log_events:
error_msg += log_event['message']
logger.debug('Message: %s' % error_msg.split("\n"))
return loggroup, logstream, error_msg, lambda_func_name
def publish_message(loggroup, logstream, error_msg, lambda_func_name):
sns_arn = os.environ['snsARN'] # Getting the SNS Topic ARN passed in by the environment variables.
snsclient = boto3.client('sns')
try:
message = ""
message += "\nLambda error summary" + "\n\n"
message += "##########################################################\n"
message += "# LogGroup Name:- " + str(loggroup) + "\n"
message += "# LogStream:- " + str(logstream) + "\n"
message += "# Log Message:- " + "\n"
message += "# \t\t" + str(error_msg.split("\n")) + "\n"
message += "##########################################################\n"
Sending the notification...
snsclient.publish(
TargetArn=sns_arn,
Subject=f'Execution error for Lambda - {lambda_func_name[3]}',
Message=message
)
except ClientError as e:
logger.error("An error occured: %s" % e)
def lambda_handler(event, context):
pload = logpayload(event)
lgroup, lstream, errmessage, lambdaname = error_details(pload)
publish_message(lgroup, lstream, errmessage, lambdaname)
If you need an error-generating Lambda function to test out, here's one from Amazon which you can use:
import logging\
import os
logging.basicConfig(level=logging.DEBUG)\
logger=logging.getLogger(name)
def lambda_handler(event, context):\
logger.setLevel(logging.DEBUG)\
logger.debug("This is a sample DEBUG message.. !!")\
logger.error("This is a sample ERROR message.... !!")\
logger.info("This is a sample INFO message.. !!")\
logger.critical("This is a sample 5xx error message.. !!")
Code Source: Amazon
Best Practices for Setting Metric Alerting
So when should you configure a metric alarm?
In general, you only want to receive alerts in cases that require your attention. If you create a situation where you have alerts too frequently and responding to them is optional, it won't be long until you miss a critical alert from the noise or worse yet --- start ignoring alerts altogether.
For example, you can ask yourself these questions: Is it okay if 1% of all requests fail for a specific Lambda function? Maybe it's important that requests take less than 1 second? You probably want to know if your Lambdas are reaching an account-wide concurrency limit. The settings are individual for every application and usually take some time and iteration to get right.
The other thing to think about is should you try to configure alerts that are preventive by nature --- to trigger when something hasn't failed yet but might very soon. For example, if a Lambda function is near a timeout or very close to its memory capacity?
Setting Custom Metrics on CloudWatch
Once you've defined your requirements for metrics you can start setting them up one by one.
This can be done through CloudWatch as well. Amazon shares some examples you can follow here but it is quite the tedious task to not only configure them correctly, but also making sure everything stays up-to-date and in working order with your growing application.
Using CloudWatch alarms is a great first line of defense but debugging applications just through CloudWatch is hard and time-consuming, especially when your functions have a non-trivial amount of invocations.
As you can see from the above contents, creating alarms for even the most basic metric is quite an annoying task. Alarms for custom metrics is a ton of work as well. There is an easier and better solution --- Dashbird's automated preconfigured alarms! Dashbird's automated alarms listen to events from logs and metrics, catching code exceptions, slow API responses, failed database requests and slow queues, and will notify you instantly of an error via Slack, Email, SNS or Webhooks if anything is about to break, so that you can quickly jump in and fix it before anything starts affecting your customers.

There is no extra instrumentation needed so you can start using it today and you won't have to re-deploy any of your Lambda functions. Dashbird sets up metrics and alerts for all supported AWS resources, so you don't have to. These are based on years of experience with monitoring serverless systems for Dashbird customers --- we have over 5,000 AWS accounts connected and ingesting monitoring data.
We built Dashbird to make serverless monitoring, debugging, and alerting easy and straightforward, without losing the granularity. Dashbird not only detects failures, it also points you to the exact request, shows you logs, X-ray traces, and relevant metadata for that invocation.

Lastly, we use the AWS Well-Architected Framework --- the official resource from AWS for building and maintaining applications on the AWS cloud.
Further Reading:

Top comments (0)