
Caching is a common technique we use when creating our applications to increase performance by storing frequently-used data in ephemeral but fast storage. A cache can help you to reduce the amount of time that an application takes to access that data, which can improve the overall user experience and make the application more responsive.
When you have enough experience programming you start learning new things apart from the typical frameworks, libraries, design patterns, etc. One of these is how you can manage your information to improve your application performance, and here it’s where a cache comes in place.
In this article, we will explore the basics of caching in software development and discuss some of the key considerations when implementing a cache for your application.
What is caching?
First of all, we need to explain in depth a little bit more about caching.
As we said, caching is a way to store data in a temporary location so that it can be accessed faster and more scalable by our application.
This can be useful for reducing the amount of time that an application takes to retrieve data that is used frequently, such as the results of a database query or the contents of a frequently-visited web page. By storing this data in a cache, the application can access it faster the next time it is needed, which can improve the overall performance of the application dramatically.
This is the main reason why it’s very important for a software developer to master all aspects of caching and use it to make faster and more reliable applications.
This is the theory but, a lot should be said when you are going to implement a cache.
Key features of a cache
Before coding anything or installing the new trendy cache engine you need to think about the key aspects of a cache and make a lot of decisions.
Depending on your use case, the resources you have, the programming language you are using and the way your application is going to use the data, you will choose a different kind of cache and a different configuration for it.
The main parameters you should pay attention to are the following:
- type of cache: you can choose to store data in a local or distributed cache
- data to store: you can choose between storing data as is or compiling it to save time for future usages in your app
- filling strategy: you can implement a lazy or eager cache depending on your use case the strategy chosen could improve or ruin your performance
- size of cache: you need to know the amount of data you are going to store because it will define the number of cache entries you can store
- keys: you should pay attention to the key or keys you use to store your data so it’s searchable the way you need it
- TTL (time to live): is another essential parameter that defines how long data will be stored in the cache
- eviction policy: this policy decides when a particular key will be removed from the cache to store new data
I know... there are a lot of parameters to configure and a ton of decisions to be made even before you write a single line of code... that’s why a cache it’s so amazing!
To make it easier we will review some of the most important in the following sections.
Local or distributed cache
Essentially we can identify two types of cache: local or distributed.
A local cache works in the same machine that is going to use the information. In other words, a local cache uses the same machine resources as your application does.
You can find two approaches to implementing a local cache: memory-based or disk-based
A memory-based cache stores data in memory that could be inside your application memory or using another process, shared memory, etc. The main advantage of this implementation is that it is the fastest way to access data. On the other hand, it has a particular caveat and it’s that data is only available as long as the cache engine is running.
A disk-based implementation uses disk storage which is slower than memory but can be persisted even if the application restarts. Another advantage is that usually, disk is cheaper and bigger than memory so you can store more data at lower costs.
A distributed cache works across a network and multiple machines access it, it’s useful to scale applications and to share data between different servers supporting huge applications. The typical way to implement these caches is to install an instance or a cluster of a specific cache engine server. These systems are meant to scale horizontally so it’s very common for them to have some features like clustering and sharding out of the box.
Which one is better? It depends on your use case... Because we have thousands of use cases for a cache, you have thousands of options to choose from. I have created the following comparison table to help you choose between a distributed or local cache for your application.

As you can see local and distributed caches are really different, but both make a lot of sense depending on your use case.
Let’s say you have data, like for example, weather information for a particular city and you want to cache it. In this example data it’s the same for all requests, doesn’t change so often and it’s small (in size). This use case could use a small local cache in disk or memory so you will avoid scaling a remote cache if you have a lot of requests.
Another use case that will need a distributed cache could be a requests access control system. These systems, for example, will store a cache with information about the number of requests per minute per API user. So you need to have all the information from all servers in a shared database to count all requests properly. In this use case, you need to use a distributed cache so you can share the information between all servers.
Important to notice that here we are not speaking about a particular technology. It is because you can implement local or remote cache using the same technology in most cases. For example, you can use a Redis instance for a local or remote cache. Some of you could think it’s a lot of overengineering but makes a lot of sense if you want to change a local cache for a distributed one in the future. In this case, you will be able to use the same technology without changing a single line of code of your application.
Choosing the best filling strategy
When we talk about the filling strategy we are talking about the way data will be inserted into the cache. Here we have two ways to do it: eager or lazy.
If you are going to use an eager approach it means you can handle a miss in your cache so you will insert or update data on a regular basis, but it doesn’t matter if some data is missing in your cache. The best way to implement this approach is using a background process that compiles data and loads the data in your cache.

The lazy approach assumes that you cannot miss information in your cache so basically, your application should try to fetch data from your cache and if a miss occurs the app will go to a secondary data source (usually a relational database) to fetch the information and then insert it in the cache for future usages. To implement a lazy approach you need to create a logic to access your data in your application to handle missing data and use a fallback. Depending on your programming language or framework you will find different options to do it.
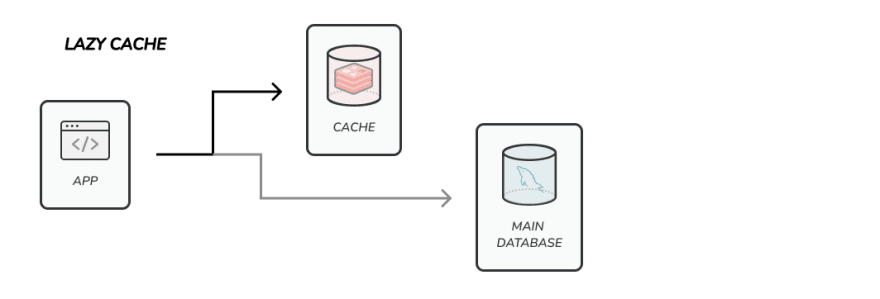
Ok but... what about a hybrid approach? Great question! For sure you can combine both strategies and, in most cases, it’s the best option if you want to get the most performance without missing any data.
Designing your keys
The most important aspect is that the keys should be searchable for your application so you need to pay attention and take your time to make the right decisions here.
Keeping this in mind, you should adapt your keys to the way your application is going to retrieve data. So, if your application is going to retrieve data based on let’s say “product_id”, you should create a key using this information, for example, a key could have this format:
product-info:123
If your application needs multiple parameters you can concatenate all necessary parameters to create your key. For example, you would want to store product information with translations per language, like product description, etc. In this case, a valid key could have the following format:
product-info:123:en
product-info:123:es
A common pitfall when choosing keys is storing huge amounts of data inside the same key. Because the cache systems are very fast indexing and managing information it doesn’t mean that they are not affected by network speed. So, if you are using a distributed cache you need to pay attention to the size of the data you store inside each key because it will be transferred through the network.
To avoid this problem you can split your cache into several keys with specific information depending on how your application will use it.
In the example we mentioned before, instead of storing all localized information in the same key you can split it in two. In one key you can store generic information like price, rating, packing size, etc. and use another key to store localized information like description, name, etc.
This way you are going to have two keys, like this:
product-info:123
product-lang:123:es
product-lang:123:en
Your application can use whatever is needed while retrieving the least data on each request.
Calculating the best TTL value
Another important parameter in your cache is TTL (time to live).
As said before, TTL is like the expiration date of your data and defines when the value of a particular key could be deleted or replaced, so it’s no longer available for your application. Choosing the correct TTL is important to maximize your cache hit ratio without having deprecated data.
A high TTL value will increase the hit ratio but could turn your cache into an unusable source of information because the data is not up to date. If the TTL value is low your hit ratio will be lower but the information will be refreshed very often.
You can configure a static TTL value, the same for all keys, or a dynamic one, a different value depending on any key parameter. It’s very useful to define dynamic TTL values so you can improve the hit ratio keeping important keys up to date. For example, you can assign different TTL values for each type of product, language, etc.
Configuring the correct eviction policy
The last important parameter to configure your cache is the eviction policy. It decides which key will be deleted or replaced to store new information.
The most common eviction policies are:
- random: removes any key
- LRU (least recently used): removes the key that was not used recently
- LFU (least frequently used): removes the key that was not accessed very often
- TTL-based: removes keys nearly to expire
Each strategy has pros and cons but as a quick reference, you could use them as follows.
You can use random eviction policy when you don’t expect a key to be used more than others, and it’s a good default strategy to start caching.
If your cache has some keys that are accessed very often you should use LRU or LFU eviction policies so you want to ensure to preserve the most popular keys.
If your cache uses different TTL values for each key a good option is to use a TTL-based eviction policy so you preserve keys with higher TTL which could be more important.
Choosing an eviction policy sounds a little tricky but in reality, is a matter of trial and error. Usually changing the eviction policy doesn’t break the cache so you can try one and change to another one to see if it’s better for your use case.
What is the best technology for my cache?
Finally, we should talk a little bit about specific technologies or engines you can use to implement your cache.
First of all, let’s talk about local caches. You can use your hard drive to implement a cache. Yeah, I know... it’s not a proper engine but, for some use cases of local cache, caching information in a local file it’s more than enough and for sure it’s the easiest way to do it.
The most used engines are in-memory databases, you can use them for local and remote caches. They are blazing fast and really easy to use because you don’t need to create indices and configure endless parameters. This kind of database could have some problems because some engines will clear all data if the process is restarted. Some examples of this technology are Redis and Memcached.
Of course, you can use any database engine with more traditional capabilities (indices, expressive queries, etc.) NoSQL databases are very interesting to implement a cache because they support a really huge amount of requests per second. These kinds of databases have one advantage which is that they support data persistence when restarting the process and allow you to query your data (filtering, projections, etc.). In this group, you can find some databases like MongoDB, Elasticsearch or Cassandra.
In case you decide to use a distributed cache, you need to check the horizontal scalability options the different technologies have and the additional costs. For example, if you deploy a cluster or HA architecture your setup will start with at least three instances, so the costs will at least triple if not quadruple.
As you can see there is no one technology that is better than the other, but any of them could be a good one for your cache.
Conclusions
As a brief summary, a cache is a way to store the most used data of your application to increase the performance of your application.
The most important features of a cache are:
type (local or distributed)
the filling strategy
how do you define the keys
the TTL you choose to improve the hit ratio
the eviction policy to delete data
The most important thing is to ensure you have a proper hit ratio to increase your application performance as much as possible.
You can use specific technology like Redis or Memcache which are in-memory databases specially designed to create the cache, or you can use other engines like NoSQL databases (MongoDB, Elasticsearch, etc.) which are designed to handle a high number of requests and allow you some advanced features like filtering, etc.
Implementing a cache for an application it’s easier than it seems and it’s a wonderful experience when you see the increase in performance you get and how configurable these kinds of technologies are.
Good luck and cache it all!

Top comments (0)