Last year I spent a complete year back home in Pakistan. With Intermittent lock-downs and COVID-19 clusters popping around majority of people were confined to their homes. During this period a boom in delivery services was on the rise and among these services was a company that pivoted from transportation to delivery, Airlift. I became a regular customer ordering almost daily using their service. As they sadly folded recently it is probably appropriate now to publish for new kids on the block to avoid making same architectural mistakes and hopefully I won't get indirect threat of action via FIA Cybercrime unit this time around (Yes, I did get that communicated, probably a story for another time :D)
Being an engineer out of curiosity I decided to see what their platform was built on and opened a browser to check what insights I could find. The web was using WooCommerce and all the assets were in S3 and this is how this adventure started.
Initially after looking at the url out of fun I decided to see if I could scrap the website and it wasn't much work. Looking at the call stack found that all asset urls were a single api call away and the api call was protected with a header value visible on the request, so not sure if that was meant to protect the endpoint somehow. A simple pipe chain of shell commands was all that was needed to download all assets. The asset url were of the format (Removing bucket url)/b6d86533-37bc-4815-bf7d-708861911f86_esomega.png
curl <url> | jq | jq -r '<expression>' | awk <expression to extract filename> | ..... | xargs <s3 command>
That was too easy so I decided to to play around with the s3 url and started with moving on from Get to List to try uploading which didn't work so thought let's do one more thing before I close it and sent a delete request and BOOM what do you know it returned a success. To verify I tried to fetch the item and got a 403. The image that got sacrificed was of esomega

Turns out S3 masks 404 as 403..
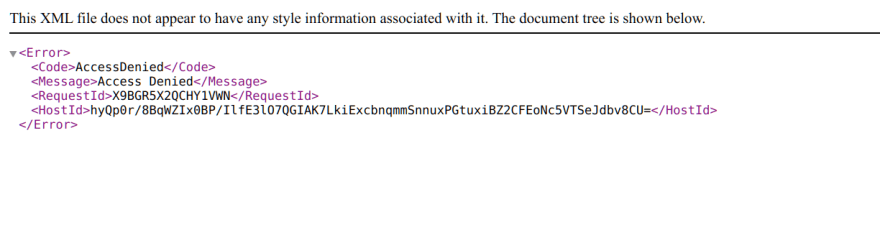
This meant if I replace the get in my original scrapping command with a delete their entire assets of inventory would be gone in a matter of minutes. All it needed was to set things in motion as such and bam adios everything in S3 would be gone if some malicious actor found it.

This was damning and decided to report this to Airlift but they had no option on their website to report any vulnerability so I took to LinkedIn and created a post and tagged them to get their attention. It took them close to a day to acknowledge and almost after 48hrs report that the vulnerability was fixed. It was apparently a happening weekend in the startup circle in Pakistan with lot of connection request to my LinkedIn and post analytics speak for themselves.
So that was the journey and experience of finding to reporting to having a fix reported back but how could this have been avoided ? AWS is a monster, its a massive cloud provider with a service for pretty much everything you would need. The most tough part in all of that is IAM permissions. Its the most vulnerable part and even the pros get it wrong or not right. S3 is widely used for serving static assets globally due to its elasticity and availability but requires correct permissions to have it secure as well. The thing that gave them off was using direct S3 URLs which expose the bucket name where the assets were hosted. Which makes it an easy target for malicious actors to exploit, ME NOT BEING ONE. You can front S3 with a Cloudfront distribution to hide your bucket details and protect it from being targeted in case of lax permissions as was the case in this scenario with bucket details available to extract. Later this was done on their end to hide exposing the buckets. Personally I would rather use a reverse proxy like Nginx over Cloudfront to serve asset and mask the bucket to avoid tight vendor lock-in. One can always front the reverse proxy with the Cloudfront as this then creates layers that are loosely coupled and serve a single purpose on each layer as the request flows.
Hope you enjoyed reading about it and always remember to not embed direct S3 URLs in your web or mobile apps.
No I didn't get anything from that $85 million for reporting this ethically. It would have been worth few grand at companies with bug bounty programs.

Top comments (0)