This article was originally published at www.pingcap.com on Apr 20, 2020

Chaos Mesh™, an easy-to-use, open-source, cloud-native chaos engineering platform for Kubernetes (K8s), has a new feature, TimeChaos, which simulates the clock skew phenomenon. Usually, when we modify clocks in a container, we want a minimized blast radius, and we don't want the change to affect the other containers on the node. In reality, however, implementing this can be harder than you think. How does Chaos Mesh solve this problem?
In this post, I'll describe how we hacked through different approaches of clock skew and how TimeChaos in Chaos Mesh enables time to swing freely in containers.
Simulating clock skew without affecting other containers on the node
Clock skew refers to the time difference between clocks on nodes within a network. It might cause reliability problems in a distributed system, and it's a concern for designers and developers of complex distributed systems. For example, in a distributed SQL database, it's vital to maintain a synchronized local clock across nodes to achieve a consistent global snapshot and ensure the ACID properties for transactions.
Currently, there are well-recognized solutions to synchronize clocks, but without proper testing, you can never be sure that your implementation is solid.
Then how can we test global snapshot consistency in a distributed system? The answer is obvious: we can simulate clock skew to test whether distributed systems can keep a consistent global snapshot under abnormal clock conditions. Some testing tools support simulating clock skew in containers, but they have an impact on physical nodes.
TimeChaos is a tool that simulates clock skew in containers to test how it impacts your application without affecting the whole node. This way, we can precisely identify the potential consequences of clock skew and take measures accordingly.
Various approaches for simulating clock skew we've explored
Reviewing the existing choices, we know clearly that they cannot be applied to Chaos Mesh, which runs on Kubernetes. Two common ways of simulating clock skew--changing the node clock directly and using the Jepsen framework--change the time for all processes on the node. These are not acceptable solutions for us. In a Kubernetes container, if we inject a clock skew error that affects the entire node, other containers on the same node will be disturbed. Such a clumsy approach is not tolerable.
Then how are we supposed to tackle this problem? Well, the first thing that comes into our mind is finding solutions in the kernel using Berkeley Packet Filter (BPF).
LD_PRELOAD
LD_PRELOAD is a Linux environment variable that lets you define which dynamic link library is loaded before the program execution.
This variable has two advantages:
- We can call our own functions without being aware of the source code.
- We can inject code into other programs to achieve specific purposes.
For some languages that use applications to call the time function in glibc, such as Rust and C, using LD_PRELOAD is enough to simulate clock skew. But things are trickier for Golang. Because languages such as Golang directly parse virtual Dynamic Shared Object (vDSO), a mechanism to speed up system calls. To obtain the time function address, we can't simply use LD_PRELOAD to intercept the glic interface. Therefore, LD_PRELOAD is not our solution.
Use BPF to modify the return value of clock_gettime system call
We also tried to filter the task process identification number (PID) with BPF. This way, we could simulate clock skew on a specified process and modify the return value of the clock_gettime system call.
This seemed like a good idea, but we also encountered a problem: in most cases, vDSO speeds up clock_gettime, but clock_gettime doesn't make a system call. This selection didn't work, either. Oops.
Thankfully, we determined that if the system kernel version is 4.18 or later, and if we use the HPET clock, clock_gettime() gets time by making normal system calls instead of vDSO. We implemented a version of clock skew using this approach, and it works fine for Rust and C. As for Golang, the program can get the time right, but if we perform sleep during the clock skew injection, the sleep operation is very likely to be blocked. Even after the injection is canceled, the system cannot recover. Thus, we have to give up this approach, too.
TimeChaos, our final hack
From the previous section, we know that programs usually get the system time by calling clock_gettime. In our case, clock_gettime uses vDSO to speed up the calling process, so we cannot use LD_PRELOAD to hack the clock_gettime system calls.
We figured out the cause; then what's the solution? Start from vDSO. If we can redirect the address that stores the clock_gettime return value in vDSO to an address we define, we can solve the problem.
Easier said than done. To achieve this goal, we must tackle the following problems:
- Know the user-mode address used by vDSO
- Know vDSO's kernel-mode address, if we want to modify the
clock_gettimefunction in vDSO by any address in the kernel mode - Know how to modify vDSO data
First, we need to peek inside vDSO. We can see the vDSO memory address in /proc/pid/maps.
$ cat /proc/pid/maps
...
7ffe53143000-7ffe53145000 r-xp 00000000 00:00 0 [vdso]
The last line is vDSO information. The privilege of this memory space is r-xp: readable and executable, but not writable. That means the user mode cannot modify this memory. We can use ptrace to avoid this restriction.
Next, we use gdb dump memory to export the vDSO and use objdump to see what's inside. Here is what we get:
(gdb) dump memory vdso.so 0x00007ffe53143000 0x00007ffe53145000
$ objdump -T vdso.so
vdso.so: file format elf64-x86-64
DYNAMIC SYMBOL TABLE:
ffffffffff700600 w DF .text 0000000000000545 LINUX_2.6 clock_gettime
We can see that the whole vDSO is like a .so file, so we can use an executable and linkable format (ELF) file to format it. With this information, a basic workflow for implementing TimeChaos starts to take shape:

The chart above is the process of TimeChaos, an implementation of clock skew in Chaos Mesh.
- Use ptrace to attach the specified PID process to stop the current process.
- Use ptrace to create a new mapping in the virtual address space of the calling process and use
process_vm_writevto write thefake_clock_gettimefunction we defined into the memory space. - Use
process_vm_writevto write the specified parameters intofake_clock_gettime. These parameters are the time we would like to inject, such as two hours backward or two days forward. - Use ptrace to modify the
clock_gettimefunction in vDSO and redirect to thefake_clock_gettimefunction. - Use ptrace to detach the PID process.
If you are interested in the details, see the Chaos Mesh GitHub repository.
Simulating clock skew on a distributed SQL database
Statistics speak volumes. Here we‘re going to try TimeChaos on TiDB, an open source, NewSQL, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads, to see if the chaos testing can really work.
TiDB uses a centralized service Timestamp Oracle (TSO) to obtain the globally consistent version number, and to ensure that the transaction version number increases monotonically. The TSO service is managed by the Placement Driver (PD) component. Therefore, we choose a random PD node and inject TimeChaos regularly, each with a 10-millisecond-backward clock skew. Let's see if TiDB can meet the challenge.
To better perform the testing, we use bank as the workload, which simulates the financial transfers in a banking system. It‘s often used to verify the correctness of database transactions.
This is our test configuration:
apiVersion: pingcap.com/v1alpha1
kind: TimeChaos
metadata:
name: time-skew-example
namespace: tidb-demo
spec:
mode: one
selector:
labelSelectors:
"app.kubernetes.io/component": "pd"
timeOffset:
sec: -600
clockIds:
- CLOCK_REALTIME
duration: "10s"
scheduler:
cron: "@every 1m"
During this test, Chaos Mesh injects TimeChaos into a chosen PD Pod every 1 millisecond for 10 seconds. Within the duration, the time acquired by PD will have a 600 second offset from the actual time. For further details, see Chaos Mesh Wiki.
Let's create a TimeChaos experiment using the kubectl apply command:
kubectl apply -f pd-time.yaml
Now, we can retrieve the PD log by the following command:
kubectl logs -n tidb-demo tidb-app-pd-0 | grep "system time jump backward"
Here's the log:
[2020/03/24 09:06:23.164 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585041383060109693]
[2020/03/24 09:16:32.260 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585041992160476622]
[2020/03/24 09:20:32.059 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585042231960027622]
[2020/03/24 09:23:32.059 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585042411960079655]
[2020/03/24 09:25:32.059 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585042531963640321]
[2020/03/24 09:28:32.060 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585042711960148191]
[2020/03/24 09:33:32.063 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043011960517655]
[2020/03/24 09:34:32.060 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043071959942937]
[2020/03/24 09:35:32.059 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043131978582964]
[2020/03/24 09:36:32.059 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043191960687755]
[2020/03/24 09:38:32.060 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043311959970737]
[2020/03/24 09:41:32.060 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043491959970502]
[2020/03/24 09:45:32.061 +00:00] [ERROR] [systime_mon.go:32] ["system time jump backward"] [last=1585043731961304629]
...
From the log above, we see that every now and then, PD detects that the system time rolls back. This means:
- TimeChaos successfully simulates clock skew.
- PD can deal with the clock skew situation.
That's encouraging. But does TimeChaos affect services other than PD? We can check it out in the Chaos Dashboard:
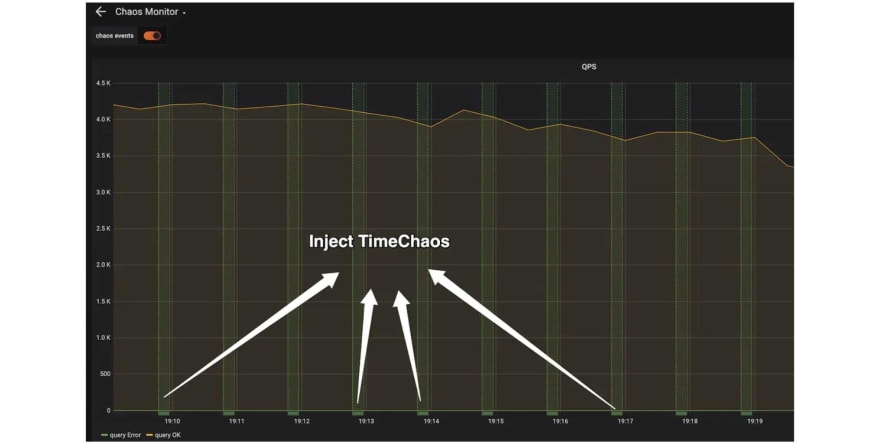
It's clear that in the monitor, TimeChaos was injected every 1 millisecond and the whole duration lasted 10 seconds. What's more, TiDB was not affected by that injection. The bank program ran normally, and performance was not affected.
Try out Chaos Mesh
As a cloud-native chaos engineering platform, Chaos Mesh features all-around fault injection methods for complex systems on Kubernetes, covering faults in Pods, the network, the file system, and even the kernel.
Wanna have some hands-on experience in chaos engineering? Welcome to Chaos Mesh. This 10-minute tutorial will help you quickly get started with chaos engineering and run your first chaos experiment with Chaos Mesh.

Top comments (0)