
Versions: Python 3.10
Introduction
A recommendation system, also known as a recommendation engine, is a model used for information filtering that attempts to predict a user's preferences and provides suggestions based on these preferences. These systems have grown in popularity and are now widely used in fields such as movies, music, books, videos, clothing, restaurants, food, places, and other utilities. These systems collect information about a user's preferences and behaviour and then use that data to improve future suggestions.
Movies are a natural part of life. There are various types of movies, such as those for entertainment, those for education, animated films for children, and horror or action films. Movies are easily distinguished by genres such as comedy, thriller, animation, action, and so on. Another way to differentiate between movies is by release year, language, director, and so on. When watching movies online, there are many movies to choose from in our most popular movies section. Movie Recommendation Systems assist us in searching for our preferred movies among all of these different types of movies, thereby saving us time spent searching for our preferred movies. As a result, the movie recommendation system must be very reliable and provide us with recommendations of movies that are exactly the same as or most closely match our preferences.
Many businesses use recommendation systems to increase user interaction and improve the shopping experience of their customers. Customer satisfaction and revenue are two of the most important advantages of recommendation systems. The movie recommendation system is an extremely powerful and vital system. However, because of the issues associated with the pure collaborative approach, movie recommendation systems suffer from poor recommendation quality and scalability issues.
Problem Statement
The project's objective is to suggest a movie to the user. providing customers of online service providers with related content culled from relevant and irrelevant collections of objects.
Objective of the Project
- Increasing the Recommendation System's Accuracy.
- Enhance the calibre of the movie suggestion system.
- Increasing Scalability.
- Improving user experience.
Scope of the Project
The goal of this project is to give people reliable movie suggestions. The project's objective is to make movie recommendation systems better than pure techniques in terms of accuracy, quality, and scalability. By combining content-based filtering and collaborative filtering, a hybrid strategy is used to accomplish this. In social networking sites, recommendation systems are employed as information filtering tools to reduce data overload. Therefore, there is a lot of room for research in this area to enhance the quality, accuracy, and scalability of movie recommendation systems. A very effective and crucial mechanism is the movie recommendation system. However, because of the limitations with a pure collaborative method, scalability concerns and poor recommendation quality also affect movie recommendation systems.
About
This Content Based Filtering Movie Recommender is built on a flask app that uses Python and JavaScript programming languages. The concept of CB was used to create two code snippets. The first is written in Python and uses the package "scikit-learn," while the second is written in JavaScript, which does not use packages and operates solely on logic. To generate recommendations, feature extraction methods and distance metrics are used.
Dataset: TMDB 5000

System Architecture of Proposed System:

Dataflow:

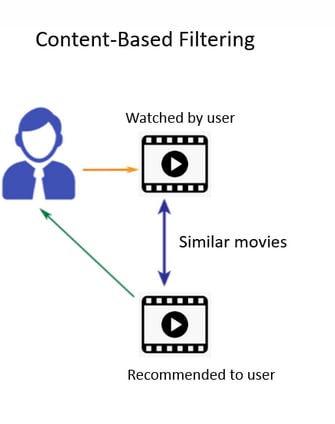
Content Based Filtering Methods
Text data is vectorized using feature extraction methods such as TF-IDF and distance metrics such as Cosine. The distance between each vector is used to calculate the similarity between each item.





Code For Creating The Application
import flask
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
app = flask.Flask(__name__, template_folder='templates')
df2 = pd.read_csv('./model/tmdb.csv')
tfidf = TfidfVectorizer(stop_words='english',analyzer='word')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(df2['soup'])
print(tfidf_matrix.shape)
#construct cosine similarity matrix
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print(cosine_sim.shape)
df2 = df2.reset_index()
indices = pd.Series(df2.index, index=df2['title']).drop_duplicates()
# create array with all movie titles
all_titles = [df2['title'][i] for i in range(len(df2['title']))]
def get_recommendations(title):
global sim_scores
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwise similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# print similarity scores
print("\n movieId score")
for i in sim_scores:
print(i)
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# return list of similar movies
return_df = pd.DataFrame(columns=['Title','Homepage'])
return_df['Title'] = df2['title'].iloc[movie_indices]
return_df['Homepage'] = df2['homepage'].iloc[movie_indices]
return_df['ReleaseDate'] = df2['release_date'].iloc[movie_indices]
return return_df
# Set up the main route
@app.route('/', methods=['GET', 'POST'])
def main():
if flask.request.method == 'GET':
return(flask.render_template('index.html'))
if flask.request.method == 'POST':
m_name = " ".join(flask.request.form['movie_name'].split())
# check = difflib.get_close_matches(m_name,all_titles,cutout=0.50,n=1)
if m_name not in all_titles:
return(flask.render_template('notFound.html',name=m_name))
else:
result_final = get_recommendations(m_name)
names = []
homepage = []
releaseDate = []
for i in range(len(result_final)):
names.append(result_final.iloc[i][0])
releaseDate.append(result_final.iloc[i][2])
if(len(str(result_final.iloc[i][1]))>3):
homepage.append(result_final.iloc[i][1])
else:
homepage.append("#")
return flask.render_template('found.html',movie_names=names,movie_homepage=homepage,search_name=m_name, movie_releaseDate=releaseDate, movie_simScore=sim_scores)
if __name__ == '__main__':
app.run(host="127.0.0.1", port=8080, debug=True)
#app.run()
Python Code
If the user enters a valid movie name, the python code in app.py will generate a list of movie recommendations. When the entered movie name matches a movie name in the dataset, recommendations are generated based on each movie's soup column (all details concatenated into one string). The TF-IDF Vectorizer and Cosine Similarity functions are imported from the "scikit-learn" package in this set of code.
Javascript Code
When the user enters an invalid movie name, the javascript code in notfound.html is executed. If applicable, this set of code will return movie titles that are similar to the user's input. To find the most similar movie names, the entered data will be compared to all existing movie names. Because this snippet of code does not make use of any packages, a dictionary was created to store the terms for vectorising purposes, as well as several functions to compute the TF-IDF and Cosine Similarity values.

Setup
activate environment and install requirements (windows):
python -m venv venv
.\venv\scripts\activate
python -m pip install -r requirements.txt
run flask app:
set FLASK_APP=app.py
set FLASK_ENV=development
flask run

Deploying To Azure:
Create App Service:


Go to Azure App Service after logging into the Azure portal. New App Service creation. Set the name of the resource group, the App Service, the runtime to Python 3.10, and the desired area.

Select the Linux-based plan for App Service and let instance SKU be the F1 (Free) tier one, you will find that in the Dev/Test section.
Then click Review and Create to finish creating the Web App. The Web App will take a few moments to load. When finished, make a note of the resource group name and the Web App's public endpoint URL.

Azure Deployment from GitHub:
Sign in with your Github account and set the organisation name as your Github username, as well as the repository and branch as master. Select available workflow if you have a workflow file in your repository; otherwise, select add a workflow. As you can see, Python is already selected for the build Runtime stack and version.
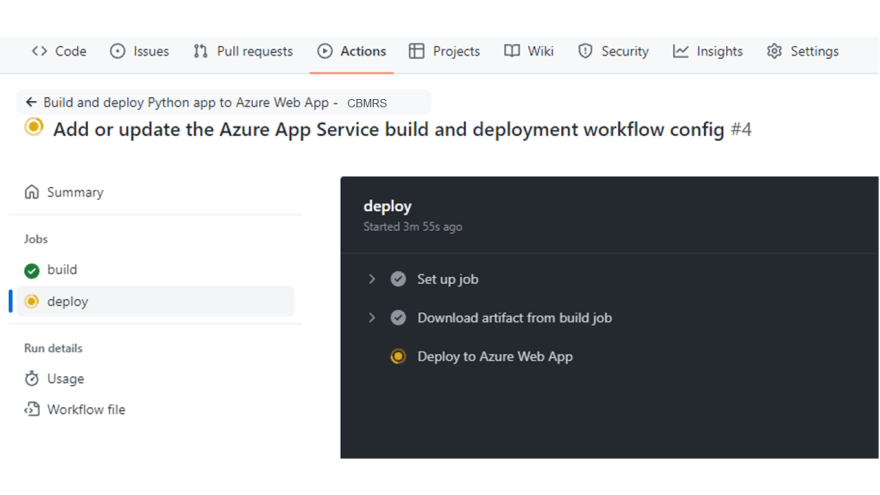
Then click Save to begin the deployment process. The deployment workflow will then begin. The deployment progress can be tracked in your repository's Actions section.
The libraries from requirements will be downloaded in a few minutes, and the deployment will be successful. Wait for the deployment to complete.
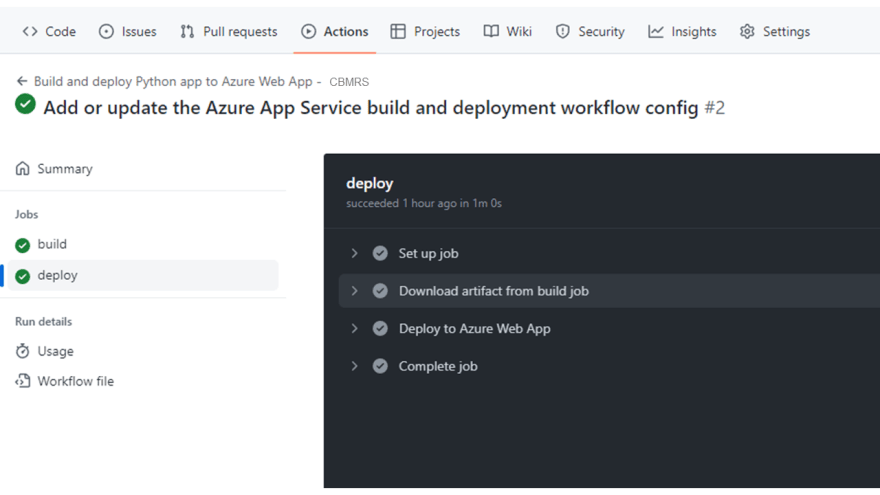
Your app is successfully deployed on Azure as soon as the workflow is completed.
# Docs for the Azure Web Apps Deploy action: https://github.com/Azure/webapps-deploy
# More GitHub Actions for Azure: https://github.com/Azure/actions
# More info on Python, GitHub Actions, and Azure App Service: https://aka.ms/python-webapps-actions
name: Build and deploy Python app to Azure Web App - cbmrs
on:
push:
branches:
- master
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python version
uses: actions/setup-python@v1
with:
python-version: '3.10'
- name: Create and start virtual environment
run: |
python -m venv venv
source venv/bin/activate
- name: Install dependencies
run: pip install -r requirements.txt
# Optional: Add step to run tests here (PyTest, Django test suites, etc.)
- name: Upload artifact for deployment jobs
uses: actions/upload-artifact@v2
with:
name: python-app
path: |
.
!venv/
deploy:
runs-on: ubuntu-latest
needs: build
environment:
name: 'production'
url: ${{ steps.deploy-to-webapp.outputs.webapp-url }}
steps:
- name: Download artifact from build job
uses: actions/download-artifact@v2
with:
name: python-app
path: .
- name: 'Deploy to Azure Web App'
uses: azure/webapps-deploy@v2
id: deploy-to-webapp
with:
app-name: 'cbmrs'
slot-name: 'production'
publish-profile: ${{ secrets.AzureAppService_PublishProfile_01e00190d8174a8490a3de88abd5b3ef }}

Latest comments (0)