What is scraping?
Web scraping is the act of inspecting the html code of a webpage and extracting information from HTML, CSS or JavaScript code, though scraping from Javascript is a more intricate process.
In my command line interface project, I chose to scrape a bookstore website, https://bookshop.org/books?keywords=permaculture, to extract the title, author, price, and URL. The URL was necessary to scrape into a second layer to extract the book’s description.
How to tell if a site is scrapeable?
One challenge I ran into was figuring out what qualifies a scrapeable website. After reading and listening to several resources, I’ve collected a list of qualifiers.
You will want to find a page that:
1) Has a repetitive format. You will want to use a site that has a list of items that follow the same format, making it easier to iterate, or filter through, each item to extract the information you want.
For instance, in the Figure 1 below, there is an unordered list of items. Great start. Figure 2 shows two items from the list in Figure 1 after they’ve been expanded. As you can see, the format repeats from one item to the next—each one contains same hierarchy of classes: h2, a href, h3, and div. These classes contain the information I want to scrape for my CLI.
Figure 1
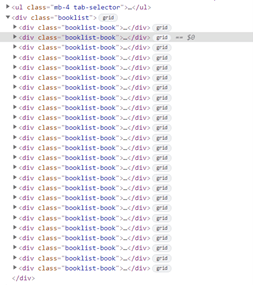
Figure 2
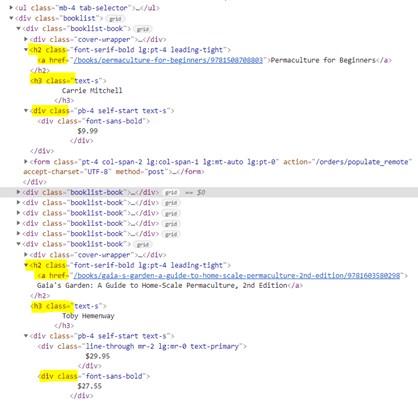
2) Does not have a lot of JavaScript in its code.
One way to confirm this is to right-click anywhere on the webpage and click “inspect.” A window will appear. At the top of the window, select the “Sources” tab. This will show you what coding language was used in the site, like in Figure 3.
Figure 3
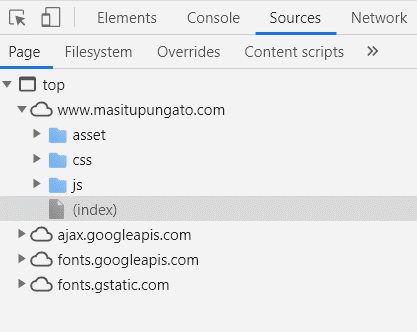
Another way to confirm this is to look for telltale signs of Javascript when you inspect the page—elements with js-, js class, toggle classes like ::, or endless scrolling in the site.
3) Won’t change often. If the programmers of the site you scraped decide to change the layout of their site, your scraped coding will break.
4) Has useful descriptor tags like class and ID names.
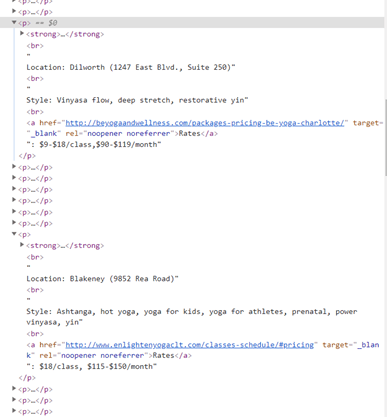
For example, take a look at Figure 4, a website that shows yoga studios in Charlotte. Although this site has a list of studios that you might be tempted to scrape, it does not have a lot of descriptors for each studio. If you look in Figure 5, for each studio’s “p” tag, all of the studio’s information is included within a single “p” tag. This means there’s no good way to access individual pieces of information such as location, style, or even the name of the studio.
Figure 4
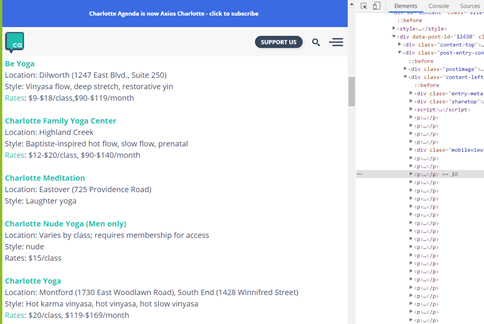
Figure 5
Instead, look for a site with descriptor classes and ID’s, preferably classes because IDs refer to one specific element (which makes iterable coding more difficult). Each of the highlighted items in Figure 6, below, show a hierarchy of data, with descriptor classes that can be drilled down into for scraping specific pieces of information in my CLI.
Figure 6

What in the *CODE!?!*
Figure 7
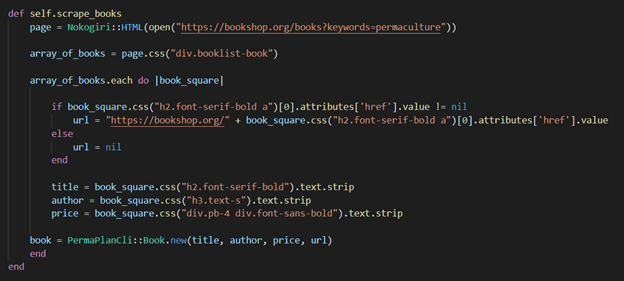
Figure 7 is an excerpt from my CLI project. Since I used scraping to extract information from the website, I required the gems called Nokogiri and open-uri.
When the program runs and comes to the open-uri code, this tells the program to go to the referenced website. Then the Nokogiri code tells the program to return the HTML code from the website.
After those gems are executed, you’ll want comb out the information you want to use.
https://www.youtube.com/watch?v=_rFCEXpP28E
In my video link above, I demonstrate how to scrape using Nokogiri and extract data.
When it came to scraping the URL, I had to use a work around method for it to work. The URL I scraped was incomplete and my code broke. This is because the site excluded the beginning "https://..." that is necessary for Nokogiri to run properly. I hard coded the "https://..." portion to where the URL turns into an individual web address for that item.
So the way my code reads is when the array_of_books is being iterated over and it searches for the URL code, if the return value is nil, then the program knows to add the hard coded line of code to complete the run.

Top comments (0)