ใน parts ก่อน ๆ เราก็ได้พูดถึงเรื่องการ scrape เว็บแบบง่าย ๆ ไปแล้วนะครับ ซึ่งผู้อ่านบางท่านอาจจะไปลองทำดูเองกับเว็บอื่น ๆ แล้วก็อาจจะพบว่ามันใช้ไม่ได้ ทำไม content สิ่งที่ scrape มา ถึงไม่เหมือนกับที่แสดงบน browser ล่ะ??? หรือบางทีพอจะดูดข้อมูลก็จะพบ error บอกว่า Forbidden บ้าง
สาเหตุก็เป็นไปได้หลายอย่างครับ อาจจะเป็นเพราะเราส่ง parameter บางอย่างไปไม่ครบ, กำหนด header ไม่ถูก, บนหน้าเว็บมีการใช้ javascript ในการ render, หรือเขาอาจจะหาวิธีกันไม่ให้เรา scrape จริง ๆ ก็ได้
ในบทความนี้จะขอแนะนำเทคนิคง่าย ๆ ที่อาจจะช่วยให้สามารถ scrape เว็บส่วนใหญ่ได้โดยไม่ติด error page นะครับ และก็จะสาธิตให้ดูโดยการ scrape เว็บต่าง ๆ ด้วยเทคนิคที่แนะนำไปนะครับ
โค้ดทั้งหมดที่ใช้ในบทความ แชร์ไว้ใน Google Colab link นี้ นะครับ สามารถลองรันและแก้โค้ดดูพร้อม ๆ กับอ่านบทความไปได้เลย วิธีการรันก็เขียนอยู่ใน link แล้วนะครับ
Scraping Techniques
1. ถ้าเว็บมีการใช้ javascript เพื่อ render ให้ลองหาตัว API ดู
เพราะว่าเว็บส่วนใหญ่นะครับ จะไม่ได้ฝังข้อมูลลงในหน้าเว็บตรง ๆ ครับ แต่จะใช้ html เป็นเหมือนแค่ template แล้วใช้ javascript ในการโหลดข้อมูลเข้ามาจาก API ที่ทำแยกไว้ต่างหากแทน ในกรณีนี้แทนที่เราจะโหลดหน้าเว็บหลักที่มีแค่โครง HTML เข้ามา ก็ให้เราโหลดเฉพาะตัวข้อมูลจาก API โดยตรงแทนเลยนั่นเองครับ
ตัวอย่างเช่น ในเว็บ www.skooldio.com/browse ถ้าเราเข้าไปด้วย browser ของเรา ก็จะเห็น course ต่าง ๆ ตามปกติครับ แต่ถ้าเราลอง requests ด้วย python แบบที่เราเคยทำใน parts ก่อน ๆ ดู ก็จะพบว่ามันไม่ได้มีข้อมูลของ course ต่าง ๆ อยู่นะครับ
url = 'https://www.skooldio.com/browse'
resp = requests.get(url)
print('SQL for Data Analytics' in resp.content.decode('utf-8'))
# Output: False
หรือถ้าเราอยากลองเช็คดูให้แน่ใจ ก็สั่งให้ print HTML ที่ได้มาดูด้วยตาก็ได้ครับ
print(resp.content.decode('utf-8'))
ถ้าลองรันดู ก็จะเห็นว่าเป็นแค่โค้ด HTML กับ css เท่านั้น ไม่ได้มีเนื้อหาอะไรที่เราต้องการอยู่เลย
เป็นเพราะว่าข้อมูลของ course ต่าง ๆ จะถูกโหลดมาทีหลัง ด้วย API api.skooldio.com/store/graphql นั่นเองครับ ดังนั้นเราจึงเปลี่ยนไปดึงข้อมูลจากตัว API แทน อย่างใน code ตัวอย่างด้านล่างผมดึง courses ในหมวดของ "คอร์สออนไลน์" จาก API มาครับ
url = 'https://api.skooldio.com/store/graphql'
payload = {"operationName": "products",
"variables": {"type": "COURSE", "searchParams": {}},
"extensions":{"persistedQuery": {"version": 1,
"sha256Hash": "2521f2486bdbf3e7d44a5ccb706699e2c8cca1aeaa8f42edd5b17f96a08b7b79"}}}
headers = {'content-type': 'application/json'}
resp = requests.post(url, data=json.dumps(payload), headers=headers)
data = resp.json()
ตรงนี้ผมใส่ header เข้าไปด้วย เพื่อบอกว่า content เป็นประเภท json นะครับ ถ้าไม่ใส่ตรงนี้ให้ถูกต้องก็จะ error ครับ
ถ้าเราลอง print ตัว data ออกมาดูก็จะเห็นเป็น dict ที่เก็บข้อมูลของ course ต่าง ๆ เอาไว้อย่างเป็นระเบียบเรียบร้อยแล้วนะครับ นี่ก็ถือเป็นข้อดีอีกอย่าง เวลาที่ web เป้าหมายมี API ให้เราใช้นะครับ 55
ทีนี้ผู้อ่านอาจจะสงสัยว่าผมทราบได้อย่างไรว่าต้องใส่ payload เป็นอย่างไร และต้องมี headers อะไรบ้างใช่ไหมครับ วิธีการก็คือผมใช้ DevTools ตัวหนึ่งของ Google Chrome ชื่อว่า Chrome Network Inspector ในการ monitor network ครับ ว่าตั้งแต่ที่โหลดหน้าเว็บ Skooldio มาเนี่ย มีการโหลดไฟล์อะไรบ้าง ซึ่งเราก็จะสามารถดูได้หมดเลยครับ ตั้งแต่ ไฟล์ชื่ออะไร content เป็นอย่างไร มี headers อะไร payload อะไร สิ่งที่ต้องทำก็แค่ "copy มาถูก" เท่านั้นครับ
ซึ่งในบทความนี้ ก็จะสอนว่าจะ "copy มาให้ถูก" ได้อย่างไรก่อน แล้วในบทความหน้า ๆ เราจะได้เล่นเจ้า Network Inspector แน่นอนครับ
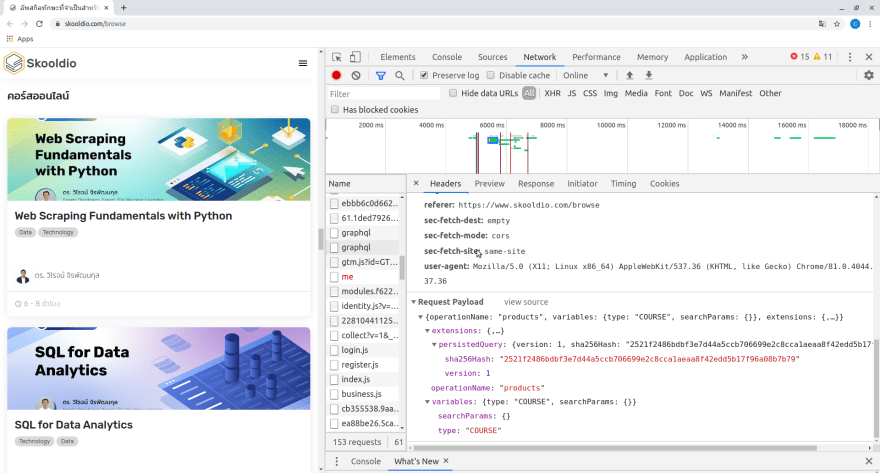
ภาพ Network Inspector (แทบทางขวา) โชว์ payload ของตัว API
2. ลองใส่ user-agent ปลอม
ในบาง website ก็อาจจะมีกลไกที่ป้องกัน bot ไม่ให้มา scrape ข้อมูลแตกต่างกันไปนะครับ แบบที่ง่ายที่สุดก็คือ block user-agent ครับ
user-agent เนี่ยเอาไว้บอกกับ server ว่า browser ที่เราใช้อยู่เนี่ยเป็น browser ตัวไหน เช่นเป็น Chrome หรือ Firefox หรือเป็น Safari ใน IOS เป็นต้น ซึ่งมีประโยชน์คือเผื่อบางทีทาง server อาจจะอยาก render หน้าเว็บให้ IOS แตกต่างจาก Android เป็นต้น
แล้วถ้าเรา requests จาก Python ล่ะ??? คำตอบก็คือ server ก็จะรู้นั่นแหละครับว่าเราเป็น Python user-agent ก็จะเป็นคล้าย ๆ แบบนี้
{
'user-agent': 'python-requests/2.23.0'
}
เพราะฉะนั้นบาง website อนุญาตให้เข้าถึงได้แค่เฉพาะพวก browser จริง ๆ เท่านั้น
แต่เราก็มีวิธีหลอก server อยู่ครับ ง่ายมาก ก็แค่แก้ header ตรงนั้นให้เป็น Google Chrome นั่นเอง
{
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'
}
มาดูตัวอย่างเว็บกันดีกว่าครับ
อย่างเช่น API การ search ของ Shopee (shopee.co.th/api/v2/search_items) เป็นต้น
ก็คือถ้าเรา requests เข้าไปตรง ๆ แบบนี้จะใช้ไม่ได้ครับ
url = 'https://shopee.co.th/api/v2/search_items/?by=relevancy&keyword=ไฟฉาย&limit=50&newest=0&order=desc&page_type=search&version=2'
resp = requests.get(url)
ถ้าเป็นในเว็บส่วนใหญ่ก็จะแจ้งเป็น error code ออกมา เช่น 400 Bad Request เป็นต้น
แต่สำหรับกรณีของ Shopee จะพิเศษหน่อยครับ คือ เราจะยังได้ status code เป็น 200 อยู่ คือไม่มี error นะ แต่ข้อมูลที่ส่งมาจะเป็น None หมดครับ
print('status code:', resp.status_code)
print('count of results:', resp.json()['total_count'])
# Output: status code: 200
# count of results: None
resp.json()
# Output: {'adjust': None,
# 'algorithm': None,
# 'error': None,
# 'hint_keywords': None,
# 'items': None,
# 'json_data': None,
# 'nomore': None,
# 'price_adjust': None,
# 'query_rewrite': None,
# 'reserved_keyword': None,
# 'show_disclaimer': None,
# 'suggestion_algorithm': None,
# 'total_ads_count': None,
# 'total_count': None,
# 'version': 'b1c94828d525e526ff969f451cc3ac33'}
เพราะว่า server กัน user-agent ของเรานั่นเองครับ ในกรณีนี้แค่ใส่ user-agent ใหม่ก็เรียบร้อยครับ
headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
resp = requests.get(url, headers=headers)
print('status code:', resp.status_code)
print('count of results:', resp.json()['total_count'])
# Output: status code: 200
# count of results: 81724
3. ลองตรวจสอบ headers อื่น ๆ เพิ่มเติม
ถ้าทำข้อด้านบน ๆ ไปแล้วยังไม่ได้ผลก็ให้ลองตรวจสอบวิธีการ requests อีกครั้งนะครับ ว่าลืมใส่ headers อะไรไปหรือเปล่า โดยวิธีการตรวจสอบก็คือใช้ Network Inspector ที่พูดถึงไปด้านบนนั่นแหละครับ ดูว่ามี headers ไหนที่อาจจะจำเป็นอีกบ้าง ตรงนี้อาจจะต้องใช้ความรู้เรื่องการทำเว็บเล็กน้อยนะครับ หรือไม่ก็ skill การเดาขั้นเทพนิดนึง 5555
อย่างเช่นเว็บ pantip ที่เคย scrape ให้ดูในบทความก่อนนะครับ
ทีแรกผมก็ลอง requests ไปที่ตัว API ตรง ๆ ดูก่อน
url = 'https://pantip.com/api/forum-service/forum/tag_topic?tag_name=ปัญหาความรัก&limit=50'
resp = requests.get(url)
print('status code:', resp.status_code)
# Output: status code: 401
ก็พบว่ามันไม่ได้นะครับ
ก็เลยลองเช็คที่ Network Inspector ดูอีกที ก็เจอว่าใน header มี field ชื่อ authorization อยู่ด้วย ซึ่งเก็บ credential สำหรับการ access API ไว้อยู่ครับ
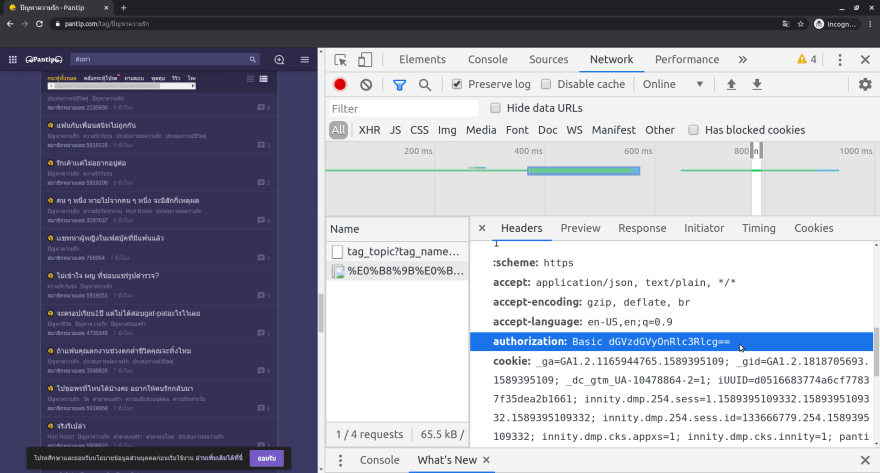
พอใส่ authorization ไปใน headers ด้วย ก็ใช้ได้เลยครับ
headers = {'authorization': 'Basic dGVzdGVyOnRlc3Rlcg=='}
resp = requests.get(url, headers=headers)
print('status code:', resp.status_code)
# Output: status code: 200
ซึ่งจริง ๆ ในหลาย ๆ ครั้ง header authorization เนี่ย ไม่ได้เป็นค่าคงตัวแบบนี้นะครับ บางทีมันอาจจะถูก generate ใหม่เรื่อย ๆ หรืออาจจะต้อง requests ไปขอ token จากอีก endpoint หนึ่งก่อน แล้วอาจจะมีเวลาหมดอายุอีก ต้องคอยขออันใหม่เรื่อย ๆ ก็มี แล้วแต่เว็บเลยครับ เพราะฉะนั้นการ monitor network เพื่อดูว่า data มัน flow อย่างไรนี่สำคัญมาก แล้วก็ไม่ง่ายเท่าไหร่นะครับ เดี๋ยวจะพูดถึงเพิ่มเติมในบทความเกี่ยวกับ Network นะครับ
4. สร้าง Session เพื่อเข้าถึงข้อมูลสำหรับสมาชิก
ในบางเว็บ ข้อมูลบางอย่าง page บาง page จะสามารถเรียกดูได้เฉพาะสมาชิกเท่านั้นครับ ถ้าเรา requests ไปโดยที่ยังไม่ได้ login ก็จะไม่สามารถดูข้อมูลนั้นได้ครับ
วิธีการก็คือ อย่างแรก แน่นอน เราต้องเป็นสมาชิกก่อนครับ ถึงจะดูได้ ไม่ได้จะสอนให้ hack เว็บเขานะครับ
ต่อไปเราก็จะใช้ Session ครับ สำหรับการเก็บ state การสร้าง Session ขึ้นมาอันหนึ่งเนี่ย เหมือนเราเปิด web browser ขึ้นมาหน้าหนึ่งแหละครับ มันจะสามารถจำ cookies จำ settings ต่าง ๆ ไว้ให้เราได้ และถ้าทำการ login เสร็จครั้งหนึ่งแล้ว การ request ครั้งต่อ ๆ ไป เว็บเป้าหมายก็จะเห็นว่าเราเป็นสมาชิกแล้วนั่นเองครับ
ดูตัวอย่างจากเว็บ skilllane นะครับ ที่ใช้เว็บนี้เพราะเราสามารถสมัครสมาชิกได้ง่ายดีครับ สามารถลองสมัครสมาชิกดูแล้วทำตามได้เลยครับ (เขาไม่ได้มาจ้างให้ผมเพิ่มยอดสมาชิกให้นะครับ555)
โดยเป้าหมายคือหน้า mycourses นะครับ ซึ่งดูได้เฉพาะสมาชิกเท่านั้น
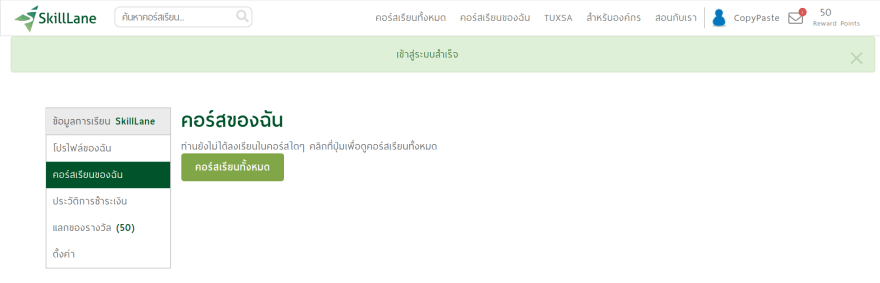
ถ้า requests เข้าไปตรง ๆ ก็จะได้ status code เป็น 200 นั่นแหละครับ แต่เราไม่สามารถเข้าถึงหน้านั้นได้จริง ๆ สังเกตุได้จาก content ที่ได้มา ไม่มีคำว่า "คอร์สของฉัน" นะครับ
url = 'https://www.skilllane.com/user/mycourses'
resp = requests.get(url)
print('status code:', resp.status_code)
print('accessable:', 'คอร์สของฉัน' in resp.text)
# Output: status code: 200
# accessable: False
ดังนั้นเราจึงต้องสร้าง Session ขึ้นมา โดยใช้คำสั่ง requests.Session() และทำการ login เข้าไปก่อน โดยส่ง requests ผ่าน session ของเราไปที่ endpoint sign_id ครับ
email = ... # ใส่ email ที่สมัครไว้
password = ... # ใส่ password
data = {
'utf8': '✓',
'user[email]': email,
'user[password]': password,
'user[last_visit_url]': '',
'user[redirect_method]': '',
'button': '',
}
url = 'https://www.skilllane.com/user/sign_in'
session = requests.Session()
resp = session.post(url, data=data) # ใช้ session.post แทน requests.post
print('login ok:', resp.status_code == 200)
# Output: login ok: True
พอ login สำเร็จแล้ว ตอนนี้ถ้า requests ด้วย session เดิมไป เว็บ skilllane ก็จะจำได้แล้วครับว่าเป็นเรา เพราะฉะนั้นก็จะดูหน้า mycourses ได้
# ลองอีกครั้ง
url = 'https://www.skilllane.com/user/mycourses'
resp = session.get(url) # ใช้ session.get แทน requests.get
print('status code:', resp.status_code)
print('accessable:', 'คอร์สของฉัน' in resp.text)
# Output: status code: 200
# accessable: True
5. Official API
เอามาเขียนไว้ข้อ 5 แต่จริง ๆ ก่อนจะเริ่ม scrape เว็บใด ๆ นะครับ ควรเช็คดูก่อนว่าเว็บนั้นมี official API ให้เราใช้หรือเปล่า ถ้ามีก็แค่เอาของเขามาใช้ง่ายกว่าเยอะครับ555
ซึ่งเว็บดัง ๆ ส่วนใหญ่ก็มีให้ใช้ทั้งสิ้นครับ เช่น Facebook Twitter Instagram Google ไม่ต้องเสียเวลางมหาวิธี scrape เลยครับ
ข้อเสียก็คือต้องยอมรับ constraints ต่าง ๆ ของ API เขาครับ เช่น Twitter อาจจะ limit ไว้ว่า ใน 15 นาที ห้าม requests มาเกิน "เท่านี้" ครั้งนะ หรืออย่าง Facebook ก็จะไม่อนุญาตให้เก็บข้อมูลในส่วนที่เป็น private เป็นต้น
6. เปลี่ยน IP ด้วย Proxy
บนเว็บทั่ว ๆ ไปอาจจะไม่ค่อยเจอนะครับ แต่บางเว็บเนี่ย ถ้าเราไป requests มาก ๆ ทำพฤติกรรมผิดปกติ ๆ ฉี่ ๆ เขาถึงขั้นจำ IP เราไว้ว่า IP นี้น่าสงสัย หรืออาจจะดูด้วยบริการของ Google ที่ detect พฤติกรรมการท่องเว็บที่น่าสงสัย แล้วก็ทำการ block ไม่ให้เราใช้งานได้เลยก็ได้นะครับ
วิธีหนึ่งที่อาจจะช่วยได้บางทีก็คือใช้ Proxy ครับ Proxy นี่เป็นเหมือนคอมพ์อีกเครื่อง ที่มี IP และประวัติการใช้ internet ของตัวเองนะครับ วิธีการใช้ Proxy ก็คือ แทนที่เราจะ requests ไปที่เว็บเป้าหมายโดยตรงนะครับ เราส่ง requests ไปให้ Proxy แทน แล้วให้ Proxy ข่วย requests ไปที่เป้าหมายแทนเราครับ เพราะฉะนั้นทางเว็บเป้าหมายก็จะไม่รู้ว่าจริง ๆ เป็นเครื่องเรา requests ไป
ซึ่งตัว Proxy นี่จริง ๆ ก็มีของฟรีให้ใช้อยู่นะครับ แต่มันก็จะช้าเพราะต้องแชร์กับคนอื่น ๆ จำนวนมาก แล้วก็อาจจะไม่ได้มีประโยชน์เท่าไหร่ด้วย เพราะคนอื่น ๆ ที่ใช้เนี่ย ส่วนใหญ่ก็คงเป็น bot scrape เหมือนกับเราแหละครับ เพราะงั้น Proxy ฟรี ก็คงโดนแบนไปก่อนตั้งแต่เรายังไม่ได้ใช้ด้วยซ้ำ
แนะนำว่า ถ้าคิดว่ามันจะช่วยได้จริง ๆ ก็ซื้อของเสียเงินมาใช้ดีกว่าครับ ซื้อมาลองดูก่อนสักเดือนก็คงไม่ได้แพงเกินไป
ส่วนวิธีการใช้ สมมุติว่าซื้อมาแล้วและ setup บนเครื่องเราเรียบร้อยแล้ว เราก็จะได้ IP ของ Proxy มานะครับ วิธี requests จาก Python ก็แค่ส่ง proxies เข้าไปตอน requests เท่านั้นเองครับ
proxies = {
“http”: “http://11.11.11.11:1234”,
“https”: “https://11.11.11.11:1234”,
}
resp = requests.get(“http://target-website.com”, proxies=proxies)
ซึ่งปกติเราก็จะซื้อเอาไว้หลาย ๆ IP นะครับ แล้วก็วนลูปเปลี่ยนสลับกันไปเรื่อย ๆ ครับ
7. Automated Web Browser
สุดท้ายถ้าหลาย ๆ เทคนิคก็ยังไม่ได้ผลอีก ก็มีอีกตัวเลือกหนึ่งครับ คือใช้ web browser นี่แหละทำ แต่แทนที่เรานั่งกดเอง เราเขียน script บอกเอาครับ ว่าจะให้เลื่อน mouse ไปที่ element ไหน รอเป็นเวลากี่วินาที คลิกที่ปุ่มไหน จะให้กดอะไร ให้พิมพ์อะไร ก็เขียน script ให้มันทำให้ได้เลยครับ ถ้าเขียน script ได้เนียนพอ ก็อาจจะสามารถหลอกบางเว็บได้เหมือนกันนะครับ
สำหรับใน Python ตัวที่ผมใช้ก็คือ Selenium สามารถลองไปศึกษาต่อดูได้ เนื่องจากต้อง setup เยอะ และมีเนื้อหาพอสมควรจะขอยังไม่พูดถึงในบทความนี้นะครับ
Summary
ขอติดเรื่อง Network Inspector กับ Selenium เอาไว้ก่อนนะครับ บทความนี้เอาแค่ให้เห็นภาพเฉย ๆ
จริง ๆ นอกเหนือจาก 7 ข้อด้านบนแล้ว การ scrape ก็มี techniques อีกมากที่สามารถทำได้นะครับ (มากพอ ๆ techniques การป้องกัน scrape นั่นแหละครับ 555) แต่ผู้เขียนก็ขอย้ำว่าการขอข้อมูลกับเจ้าของอย่างถูกต้องน่าจะดีที่สุดนะครับ แล้วก็เวลาที่ scrape ก็ควรเคารพเจ้าของเว็บไซต์ ไม่ยิง traffic มากเกินไปจนสร้างปัญหาให้เขา หรือเอาข้อมูลไปใช้ในทางที่ไม่ดีนะครับ
และถ้ามีเรื่องไหนที่สนใจเพิ่มเติมสามารถ comment เอาไว้ได้นะครับ
FB Page: Copy Paste Engineer
part อื่น ๆ ใน series
- part 1: การดูดข้อมูลเบื้องต้น ด้วย Python
- part 2: Chrome's Code Inspector
- part 3: เทคนิคการ extract ข้อมูลด้วย XPath
- part 4: ทำไมถึง scrape บางเว็บไม่ได้??? 7 เทคนิคง่าย ๆ ให้ scrape เว็บส่วนใหญ่ได้ลื่นปรื๊ด
- part 5: วิธีเลียนแบบการรับส่งข้อมูลของเว็บเป้าหมาย





Top comments (2)
น่าสนใจมากๆครับ กำลังศึกษา python scrapping อยู่พอดี ขอบคุณครับ ขอติดตามครับ
Oh god, why you didn't write in english so everone could use it?