ต่อเนื่องจาก บทความในตอนที่แล้ว part 1 เราได้ลองดึงข้อมูลจาก Wikipedia ด้วย Python แบบง่าย ๆ ดูแล้ว ถ้ายังจำได้ หลังจากที่เรา scrape ข้อมูลดิบ เป็นโค้ด HTML ยาว ๆ ลงมาใน Python แล้ว ในส่วนของการ extract ข้อมูล เราใช้ XPath เพื่อ select elements ที่ต้องการออกมา
ซึ่งผู้เขียนได้แอบบอกไว้แล้วว่า XPath ที่ได้มานั้น มาจากการแกะโค้ด HTML ของเว็บต้นทาง โดยใช้เครื่องมือ Code Inspector บน Google Chrome Browser
บทความนี้จะมาพูดถึงเครื่องมือตัวนี้กันครับ ว่ามันจะช่วยให้เราดูดข้อมูลได้ง่ายขึ้นอย่างไรบ้าง
จริง ๆ แล้วตัว Code Inspector นี่มันเป็นแค่หนึ่งในหลาย ๆ tools ที่ Google Chrome มีให้ใน Google Chrome DevTools เท่านั้นนะครับ โดยจุดประสงค์หลัก ๆ ของ tools ทั้งหลายก็คือใช้เพื่อ debug เว็บที่เราเขียนขึ้นเอง โดยผู้ใช้สามารถเรียกดูได้ทั้งโครงสร้าง การทำงาน และ data ของเว็บที่รันอยู่แบบ real-time เลย ซึ่งล้วนแล้วแต่เป็น information ที่มีประโยชน์ต่อการ scrape ข้อมูลทั้งสิ้นครับ
โดยในครั้งนี้จะมาแนะนำ Code Inspector ให้รู้จักกันคร่าว ๆ ว่ามันทำอะไรได้บ้าง แล้วจะใช้เพื่อแกะ XPath ออกมาจากโค้ดได้อย่างไรนะครับ แล้วในบทความถัด ๆ ไป จะสอน tool อีกตัวที่ช่วยให้เราเข้าใจการทำงานของเว็บนั้น ๆ มากขึ้น เช่น กดปุ่มนี้แล้วเว็บจะโหลดข้อมูลอะไรมาจากที่ไหน ด้วย tool ที่ชื่อว่า Network Inspector บน Google Chrome เช่นกันครับ
Get Started!
ตัว Code Inspector นี่ สำหรับ developer จะเอาไว้ใช้ตรวจสอบว่าหน้าเว็บที่เราเขียนนั้น render ออกมาเป็น code HTML ได้ถูกต้องหรือไม่ ทั้งโครงสร้างของ HTML และ attributes ต่าง ๆ
note: อธิบายสำหรับท่านที่ไม่ได้เป็น web developer นะครับ บางที web page ที่เราเห็นนั้นอาจจะไม่ได้เขียนด้วย HTML ไฟล์เดียวทั้งหมดนะครับ อาจจะมาจาก HTML หลายไฟล์มารวมกัน หรือถูก render ลงมาเป็น HTML จาก server ต้นทางอีกที ทำให้ในการ develop ฝั่ง server อาจจะต้องดูผลลัพธ์ไปพร้อม ๆ กัน ว่า HTML code ถูก rendered ออกมาตามที่ต้องการหรือไม่
ซึ่งประโยชน์หลัก ๆ ที่เราจะได้จาก Code Inspector ก็คือใช้หา XPath หรือหาวิธีการ extract ข้อมูลจากหน้าเว็บนั้น ๆ เช่น ดู id ของ elements ที่เราสนใจ
วิธีการเรียก Code Inspect คือให้เข้าไปที่ website ที่ต้องการ ด้วย Google Chrome Browser แล้วกด F12 ก็จะมีแถบด้านขวา (หรือด้านล่าง) ที่แสดง HTML elements ของ page ปัจจุบัน ปรากฎออกมาตามภาพ

Highlight ตำแหน่งของ Component จาก Element
โดยเราสามารถ คลิกเพื่อ expand elements ย่อย ๆ ออก แล้วเข้าไปดูโครงสร้างที่ซ่อนไว้ได้ หรือถ้าหากลองเอาเมาส์ไปชี้ที่ element ในนั้นดู Chrome ก็จะข่วย highlight บอกเราให้ด้วย ว่า element นั้น อยู่ตรงไหนบนหน้าเว็บ
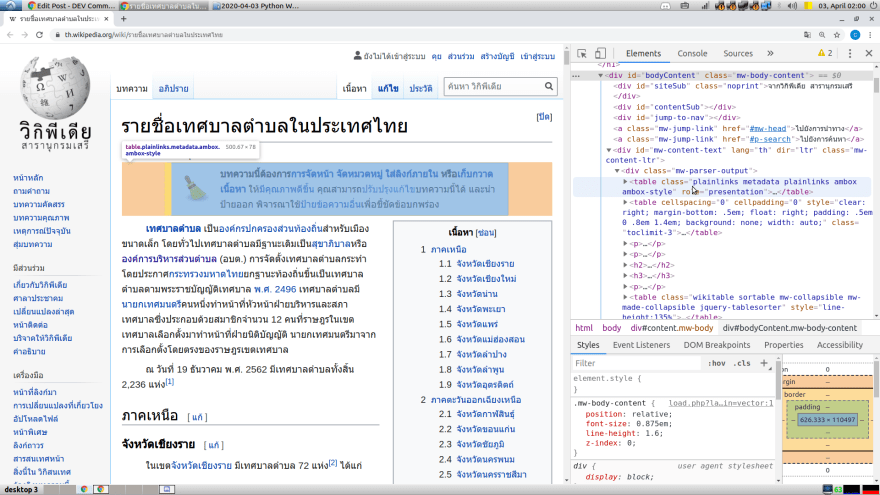
Highlight Element จาก Component
หรือในกรณีที่เราอยากทราบว่าตัว component บนหน้าเว็บ เช่น ตารางที่เราเห็นอยู่นี้ มันคือ element ในโค้ด HTML ก็สามารถทำได้ โดยการ คลิกขวาที่ component นั้น ๆ แล้วเลือก Inspect จากนั้นตัว Code Inspector ก็จะไป highlight HTML element ของ component ให้ทันทีครับ
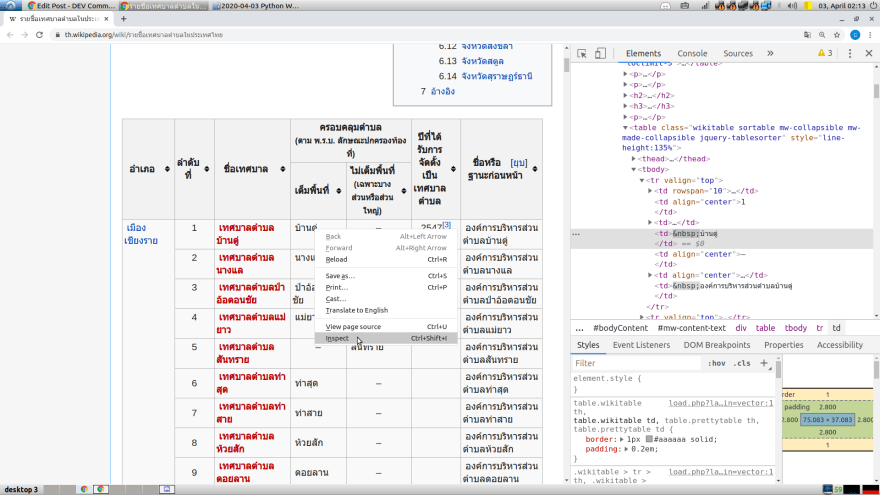
แกะ XPath ของ Component แบบเบสิก
เมื่อเราคลิกเลือก element ที่เราสนใจได้แล้ว หากเราอยากจะได้ XPath ของ element นั้น ๆ มา Inspector ก็สามารถหาให้เราแบบง่าย ๆ ได้ (แต่อาจจะไม่ค่อยตรงใจเราสักเท่าไหร่555)
เช่น สมมุติว่าเราอยากจะได้ XPath ของ เทศบาลตำบลบ้านดู่ ก็ให้หา element ของมันให้ได้ก่อนตามที่อธิบายไว้ด้านบน คือคลิกขวาที่ เทศบาลตำบลบ้านดู่ แล้วเลือก Inspect Inspector ก็จะ highlight element ของ เทศบาลตำบลบ้านดู่ ไว้ให้
จากนั้นก็หา XPath โดยการ คลิกขวาที่ element นั้น แล้วเลือก Copy แล้วก็ Copy XPath

ถ้าลอง paste ดูก็จะได้ XPath ของ เทศบาลตำบลบ้านดู่ แบบนี้ครับ
//*[@id="mw-content-text"]/div/table[3]/tbody/tr[1]/td[3]/b/a
แต่ XPath นี้เป็นแค่ของ เทศบาลตำบลบ้านดู่ เท่านั้นครับ แต่สิ่งที่ต้องการจริง ๆ คือ ชื่อเทศบาลทั้งหมด ถามว่าจะหามาได้อย่างไร?
ถ้ามีประสบการณ์การทำเว็บมาบ้าง พอเห็นข้างบนก็อาจจะเดาได้แล้วว่า XPath ที่เหมาะสมควรจะเป็นอะไรนะครับ แต่ถ้ายังเดาไม่ออกก็ไม่เป็นไรครับ เพราะอย่างบาง website ที่ซับซ้อนขึ้นหน่อย ถึงจะพอมีประสบการณ์ก็คงเดาไม่ออกในทีแรกเช่นกัน
วิธีหนึ่งที่ผมทำก็คือใช้ตัว Chrome Inspector นี่แหละ เอาตัวอย่างของ XPath จากเทศบาลตำบลอันอื่น ๆ ออกมาดูเพิ่มอีกเยอะ ๆ ก็จะช่วยให้เห็นภาพมากขึ้นครับ
(1) //*[@id="mw-content-text"]/div/table[3]/tbody/tr[1]/td[3]/b/a (ตาราง 1 บรรทัด 1)
(2) //*[@id="mw-content-text"]/div/table[3]/tbody/tr[2]/td[3]/b/a (ตาราง 1 บรรทัด 2)
(3) //*[@id="mw-content-text"]/div/table[3]/tbody/tr[10]/td[3]/b/a (ตาราง 1 บรรทัด 10)
(4) //*[@id="mw-content-text"]/div/table[4]/tbody/tr[3]/td[3]/b/a (ตาราง 2 บรรทัด 1)
(5) //*[@id="mw-content-text"]/div/table[4]/tbody/tr[30]/td[2]/b/a (ตาราง 2 บรรทัด 28)
(6) //*[@id="mw-content-text"]/div/table[7]/tbody/tr[25]/td[2]/b/a/b (ตาราง 5 บรรทัด 23)
(7) //*[@id="mw-content-text"]/div/table[10]/tbody/tr[41]/td[2]/b/a (ตาราง 8 บรรทัดสุดท้าย)
(8) //*[@id="mw-content-text"]/div/table[24]/tbody/tr[3]/td[3]/a/b (ตาราง 22 บรรทัด 1)
(9) //*[@id="mw-content-text"]/div/table[76]/tbody/tr[3]/td[3]/b/a (ตารางสุดท้าย บรรทัด 1)
(10) //*[@id="mw-content-text"]/div/table[76]/tbody/tr[37]/td[2]/b/a (ตารางสุดท้าย บรรทัดสุดท้าย)
...แล้วยังไงต่อ... ใช่ไหมครับ 555
ต่อไปเราก็จะสร้าง XPath 1 อัน ที่สามารถครอบคลุมทุกกรณีที่เราเจอมาโดยการใส่ condition เพื่อช่วยเลือก โดยผลลัพธ์สุดท้ายก็จะได้เป็น XPath ที่เราใช้จริง ใน part ที่ 1 นั่นเองครับ ซึ่งจะอธิบายวิธีการโดยละเอียดต่อใน part 3 นะครับ
Summary
สำหรับ part ที่ 2 นี้ จุดประสงค์หลัก ก็คือแนะนำ tool ที่ชื่อ Code Inspector ใน Google Chrome ครับ ซึ่งเป็น tool ที่ช่วยให้สามารถ extract ข้อมูลได้ง่ายขึ้นมาก และผู้เขียนได้ใช้หา XPath ไปจริง ๆ ใน บทความ part 1 ครับ
บทความนี้เราจะค้างเอาไว้ตรงที่เรา sample XPath ออกมาเยอะ ๆ นะครับ แล้วใน part ที่ 3 ก็จะมาอธิบายให้ฟังว่าจะทำยังไงต่อ เพื่อให้ได้ XPath ที่เราใช้ไปใน part ที่ 1 นะครับ
หรือถ้ามีเรื่องไหนที่สนใจเพิ่มเติมสามารถ comment เอาไว้ได้นะครับ
FB Page: Copy Paste Engineer
part อื่น ๆ ใน series
- part 1: การดูดข้อมูลเบื้องต้น ด้วย Python
- part 2: Chrome's Code Inspector
- part 3: เทคนิคการ extract ข้อมูลด้วย XPath
- part 4: ทำไมถึง scrape บางเว็บไม่ได้??? 7 เทคนิคง่าย ๆ ให้ scrape เว็บส่วนใหญ่ได้ลื่นปรื๊ด
- part 5: วิธีเลียนแบบการรับส่งข้อมูลของเว็บเป้าหมาย




Top comments (0)