I repeatedly see both business stakeholders and software engineers continue to struggle to see eye-to-eye on matters of technical debt despite the fact that both are impacted by it. I attribute this to the fact that both camps speak different languages and over the last 15 some odd years I haven’t found a silver bullet that can get a 100% alignment. Engineers are driven by:
- Code complexity, maintainability and understandability
- Making architecture more fault tolerant, resilient and quickly recoverable from outages
- Keeping up with technological changes/staying on the cutting edge
- Innate desire to improve software systems and not letting them rot
Business folks are driven by :
- Investment vs return on that investment
- Financial savings/profit
- Time to market
- Legal liability/other risk
- Short term thinking and focus on features as opposed to long term outcomes
Its like two people arguing with each other where each speaks a language the other doesn’t understand! Never going to work! This InfoQ article tries to look under the hood of this communication gap between the two parties in more detail and makes some good recommendations, worth checking out.
The other problem that I think hinders alignment is a holistic understanding for how technical debt affects or is affected by, business drivers and having some way of visualising it. You can often sense a lack of this understanding when a manager says, “I don’t really see the business value in addressing this technical debt, right now we have critical functional work to do, can we do this tech thingy later?”. In this post I will try to use simplified Systems Thinking modelling language to put technical debt in the larger organisational context with the hope that it will make some sense to everyone.
Using Systems Thinking to Put Technical Debt in Context
I am going to take a crack at it by drawing a systems model using digital post-its connected by arrows (what else?). The post-its represent variables that can increase or decrease, green arrows mean a change in one variable results in corresponding increase in another variable and later on red arrows that mean a decrease in one variable triggered by a change in another variable.
 DISCLAIMER: these models are abstractions of real life systems, so they are not meant to be 100% accurate but a useful approximation to help make sense of the complexities involved and connect them to the other parts of the organisational system.
DISCLAIMER: these models are abstractions of real life systems, so they are not meant to be 100% accurate but a useful approximation to help make sense of the complexities involved and connect them to the other parts of the organisational system.
For these models, I am going to use the following variables:
- Number of business problems to solve/solved
- Amount of business value created (somewhat abstract but let’s say its the measure of usefulness of the solutions that help improve the business outcomes)
- Business success (EBITDA/revenue, new investment and expansions, new customer journeys, number of customers signed up, number of repeat customers, NPS what have you)
- Business pressures (slow down in business success metrics creates pressure to do more)
- Market forces (pandemic, war, supply chain issues, competitor action, economic turbulence etc)
- Internal dynamics (org politics, reorganisation and restructuring, cost cutting, lawsuits, etc). Along with market forces, this generally tends to push down an organisation’s success.
- Engineering velocity (roughly speaking, number of value add ideas productionised per cycle)
- Engineering compromises (the number of shortcuts we take whilst productionising ideas)
- Technical debt (well, I guess I don’t need to explain this, or do I?
 )
) - Engineer motivation and trust (mostly abstract but I guess WTFs per minute can be a good metric
 . In seriousness though, this erodes over time and can often be sensed when people abruptly leave or stop caring or become a very frustrated and a challenging member of the team.)
. In seriousness though, this erodes over time and can often be sensed when people abruptly leave or stop caring or become a very frustrated and a challenging member of the team.)

For the first diagram I am going to assume a perfect world where an organisation keeps going from strength to strength forever, and the engineering velocity keeps growing in tandem as well:
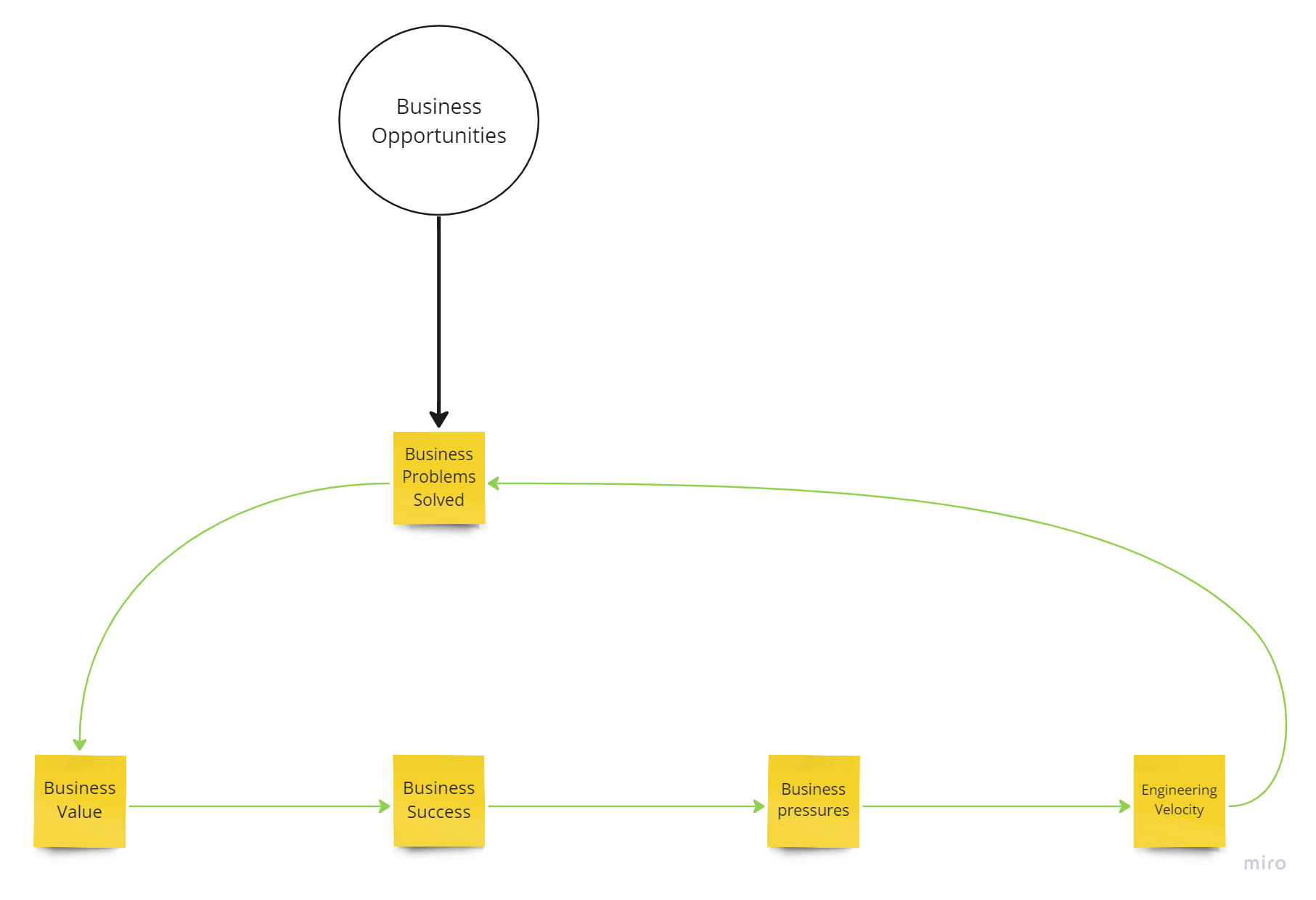
In a perfect world, business success and engineering velocity will continue to increase infinitely
Business opportunities generate business problems to be solved, the more problems we solve, the more business value we generate, the more the business will succeed, this means the pressure to succeed will increase in the form new revenue streams, new opportunities, new value streams, and the more demand this will force upon the engineering velocity which will respond by solving these challenges and generating more business value in turn. And the cycle will just continue resulting in an infinitely successful business and infinitely high engineering velocity with no technical debt whatsoever, its essentially a run-away positive feedback loop in systems thinking terminology. Of course, this is living in Harry Potter land, no relation to reality whatsoever!! So let’s descend down to reality, shall we?
In her book Thinking in Systems, Donella Meadows observes that:
no physical system can grow forever in a finite environment.
Meadows, Donella H.. Thinking in Systems
This is because an uncontrollably growing system eventually will tend towards instability and crash (the 2008 financial crisis is a glowing example of this runaway positive feedback loop, or, ever tried to bend an thin metal strip back and forth repeatedly until it snaps? Obvious, right?). In the light of this constraint, we can see that our model is missing other variables that serve to constrain the system so it doesn’t become a victim of its runaway success (or failure). So what would the picture look like with all these variables plugged in?

In a more realistic world, we need other variables that constrain the system
Suddenly the complexity explodes!
As we solve more business problems, the more value we add, the more the business succeeds which increases the pressure for sustained success, because…let’s not get complacent, yes? Internal dynamics such as reorganisation, politics etc and market forces such as pandemic, competitor actions, societal upheavals like wars, high inflation etc, push against the business success, this creates even more business pressure to succeed and pressure to increase engineering velocity to reduce time to market and gain competitive advantage.
Up to a certain point the velocity will grow very organically, but now that we know that no system can grow forever, eventually, the high demand on engineering velocity will result in more and more engineering compromises and shortcuts to be made. This will in turn increase the technical debt accumulated which initially will increase the velocity but with enough of these kinds of iterations, it will start to wear down the engineer motivation and trust in the system and the team as they struggle with the past engineering compromises and in the race to deliver faster will end up adding new compromises and debt on top of the existing ones. This also increases the maintenance costs of the software and eventually it will start to slow down the engineering velocity. This means a reduction in the number of business problems solved, more of the org’s investment in engineering goes towards just struggling with the technical debt and not adding new value. This in turn results in that much less value being created over all which will eventually start to reduce business success.
If left unchecked (in some cases this does happen), this cycle could also go in a runaway negative feedback loop where an org’s engineering capabilities are actively hindering its success as opposed to enhancing it. This erosion of value creation doesn’t happen over night, it can take a long time (often years) to build up but in the end its like the org is paying the engineering teams to actively sabotage itself, that’s horrifying! But since no system can grow or shrink forever, interventions will be made eventually to salvage the situation which will inevitably lead to Big Bang Rewrites of all the “legacy” systems. This will create its own problems (not represented in the diagram), for e.g. the time and money cost of rewrite will further erode the business value proposition of the system because value won’t be created until the first version of the “new” system goes live, leading to less business success, increasing costs, increasing management pressure to deliver successfully this time around. But since we want to go fast, we’d take shortcuts and compromises which starts the vicious cycle all over again just in the “new” system.
Can this be considered a smart business strategy?
In systems of comparable complexity, refactoring a system gradually towards health and improved design is generally a lower risk and rapid return investment than rewriting it from scratch (though in some cases, the opposite is also true). This is because much of the original investment (and knowledge) can still be valid and preserved and you are not rushed to finish the work for the fear of blocking the creation of new value. Old and new (if refactored carefully), can happily co-exist with every iteration not only creating new value now but also reducing the technical debt that we’ve accumulated along the way. The old can then be decommissioned eventually.
But I digress a bit, so what’s the solution to minimise the run away negative feedback loop then? We don’t want to pack down our business just because there are constraining forces at work, yes? How do we try to create a harmonious balance of short term debt advantage and long term stability and resilience of the system? In finance, the bank’s enforcement agents or government penalties, will solve that problem for you real quick, but unfortunately for most enterprise software engineering, we don’t have that level of “encouragement”.
…
How about Engineering Discipline? Sounds obvious but how will it fit in the model? Let’s see:

Introducing a little bit of discipline (top right corner-ish), can bring back some stability over time
When the velocity starts to drop and more engineering compromises are made to increase the velocity (see the irony here?), engineering discipline can act as a compensating driver that can make sure that we are able to reduce the previous compromises first before we add new value every cycle. This gradually results in increased engineer motivation and trust as they don’t need to struggle with bad decisions as much and this will serve to increase engineering velocity and value creation over time. The increase in the engineering velocity may not be by leaps and bounds and not right away, but at least it’s likely to not fall too low in the face of ever increasing business pressures, and the system won’t spiral into madness.
Like I said before the model is not perfect, no model is, but I think (and hope) it helps put the complexities involved, in perspective for both engineers and business stakeholders and clarifies the affect long term accumulation of technical debt can have on the business outcomes.
Engineering Discipline is critical to bringing the system back into equilibrium and this is why its important for engineering teams to take control and ownership of this discipline and be proactively on the lookout for variable changes that tend to push the system towards instability. We don’t need permission to do the right thing, we have the engineering expertise and experience to know when and how the right thing should be done because we also understand the long term implications of neglect. Though we do need to communicate about these implications to the business in the language they understand to the extent its feasible and possible_._
If you have tried similar tools to communicate the value of addressing technical debt or if you think this model could be made more convincing or more “correct”, please drop a comment! Cheers!

Top comments (0)