
Atualmente existem ferramentas que nos ajudam a executar containers em produção e a maioria delas trazem funcionalidades preciosas como "Health Checks", "Limite de recursos" e até mesmo prometem um deploy "Zero Down Time", o foco deste post é nesse último Item. Na Convenia utilizamos o Docker Swarm para gerenciar alguns containers em produção e o Docker Swarm entrega esse tipo de deploy "Zero Down Time" através de uma simples configuração, porém após alguns testes em uma API sob stress constatamos que sempre ocorriam alguns erros no momento do deploy. Aprofundando a análise do que poderia causar esses erros, percebemos que podemos cometer alguns "equívocos" que nos impedem de ter um deploy verdadeiramente sem Down Time e ainda podemos constatar que esses "equívocos" são comuns em outras ferramentas como Kubernetes também, dai saiu a motivação para escrever esse post.
Graceful ShutDown
A grosso modo podemos definir "Graceful shutdown" como a maneira "natural" em que um processo é desligado. Muitos processos abrem sockets e trabalham com estado em memória então para esses processos desligarem naturalmente muito provavelmente eles vão fechar as conexões abertas e persistirem o estado, que está na memória, no HD para que não haja perda de dados e para poder retomarem as atividades sem maiores problemas quando forem reiniciados, em uma queda de energia por exemplo, os processos não tem esse privilégio, nesse caso podemos nos deparar com erros durante a próxima inicialização do processo, isso é conhecido como "Hard Shutdown".
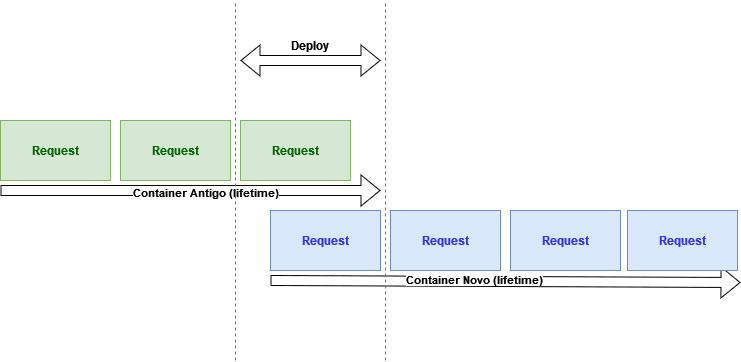
A boa notícia é que todos os softwares mais difundidos fazem isso por padrão, o nginx quando recebe o "sinal" de desligamento espera a resposta de todos os requests que estão em execução no momento, antes de desligar de fato. Esse "Graceful Shutdown" é importante porque o deploy consiste na "troca" de um processo com a versão antiga do software pelo mesmo processo contendo a versão nova, ao desligar o processo contendo a versão antiga, os requests que estiverem em execução não podem falhar, pois eles ainda estão sendo respondidos pelo processo antigo enquanto os novos requests já estão sendo servidos pelo processo novo como mostrado na imagem abaixo.
Na Convenia temos muitos listeners feitos com o Pigeon, nesse caso não estamos falando de um webserver e sim de um consumer que "ouve" uma fila do RabbitMQ, você já deve imaginar que para "ouvir" essa fila temos que ter uma conexão aberta com o RabbitMQ então nada mais justo que fechar as conexões no momento em que o processo for desligado, é justamente isso que o Pigeon faz no código a seguir:
protected function listenSignals(): void
{
defined('AMQP_WITHOUT_SIGNALS') ?: define('AMQP_WITHOUT_SIGNALS', false);
pcntl_async_signals(true);
pcntl_signal(SIGTERM, [$this, 'signalHandler']);
pcntl_signal(SIGINT, [$this, 'signalHandler']);
pcntl_signal(SIGQUIT, [$this, 'signalHandler']);
}
public function signalHandler($signalNumber)
{
switch ($signalNumber) {
case SIGTERM: // 15 : supervisor default stop
$this->quitHard();
break;
case SIGQUIT: // 3 : kill -s QUIT
$this->quitHard();
break;
case SIGINT: // 2 : ctrl+c
$this->quit();
break;
}
}
Nesse código definimos handlers para os sinais de desligamento que o processo pode receber e chamamos os métodos quit() e quitHard() que têm como objetivo fechar a conexão com o RabbitMQ. Até agora falamos muito sobre esses sinais que os processos podem receber de outro processos, ou até mesmo do kernel, mas caso você não estaja familiarizado ou se não souber exatamente a diferença entre eles, você pode ficar um pouco mais por dentro nesse artigo.
PID 1
Quando utilizamos docker para executar nossa aplicação em produção e fazemos um deploy, um container com a nova versão da aplicação é iniciado,o container com a versão antiga da aplicação recebe o sinal "SIGTERM" que é um pedido formal de desligamento, caso o container demore mais que 10 segundos para desligar ele será morto, logo o processo dentro do container tem 10 segundos para fazer o seu "Graceful Shutdown". A grande pegadinha é que dentro do container apenas o processo de ID 1 vai receber esse sinal, se dentro do container iniciarmos um outro processo antes da nossa aplicação, esse processo vai portar o id 1 e não a nossa aplicação. Agora que temos outro processo recebendo os sinais de desligamento no lugar da nossa aplicação, nunca vamos ter a oportunidade de fazer um Graceful Shutdown porque nunca saberemos o momento de desligar, por mais que esse pareça um erro bobo na verdade isso acaba acontecendo com uma certa frequência como por exemplo nos Dockerfiles a seguir:
FROM nginx:latest
ENTRYPOINT ["nginx", "-g", "daemon off;"]
O Dockerfile acima está com o ENTRYPOINT no formato de array, se você entrar dentro do container gerado por esse Dockerfie e executar o comando pstree verá o seguinte output:
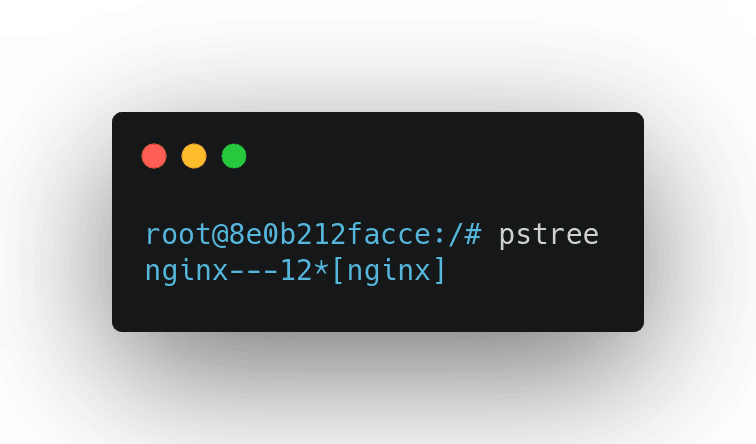
Perceba que o "nginx" é o primeiro processo mais a esquerda, isso significa que atingiremos o objetivo de ter um Graceful Shutdown visto que o nginx vai receber os sinais pessoalmente e ele sabe muito bem como lidar, para tirar a dúvida podemos executar um docker stop no container em execução e provavelmente veremos o container sendo desligado quase instantaneamente.
FROM nginx:latest
ENTRYPOINT nginx -g 'daemon off;'
A Mudança no dockerfile acima foi sutil, mas faz toda a diferença, com a sintaxe corrida do ENTRYPOINT o comando em questão é executato pelo shell dentro do container, segue o output do pstree:
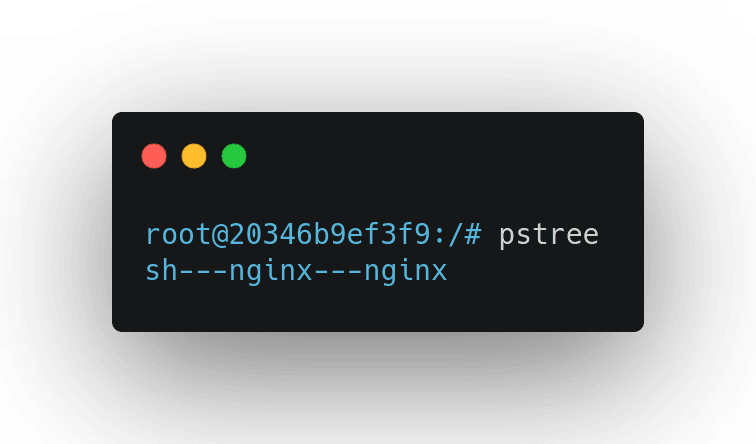
Agora o processo mais a esquerda é o sh, ele quem receberá os sinais de desligamento e por acaso não sabe muito bem o que fazer com esses sinais, se você executar um docker stop nesse container verá que demora 10 segundos para parar, dessa forma não faremos o "Graceful Shutdown" e nunca teremos um verdadeiro deploy "Zero Down Time" porque sempre que o container com a versão antiga do código morrer, vai levar os requests que estão em execução para a vala junto. Logo devemos nos assegurar que nosso processo está recebendo o sinal de desligamento corretamente.
Vários processos no mesmo container
É conceitualmente correto que o container contenha apenas um processo(PID 1), mas é relativamente comum aparecer a necessidade de executar mais de um processo no mesmo container. Tomando como exemplo uma aplicação PHP, que não é capaz de responder como uma aplicação completa(HTTP) apenas com o processo do PHP-FPM, pois necessita de um reverse proxy como apache ou nginx para isso, como poderíamos fazer um único container contendo tanto nginx como php-fmp e que funcione como uma aplicação completa capaz de entender o protocolo HTTP? A própria documentação do docker nos traz algumas recomendações sendo que dentre elas a melhor seria utilizar o supervisord como processo principal no container, cuidando dos outros processos. O supervisord é capaz de propagar os sinais de desligamento que recebe para os processos filhos, sendo assim tanto o nginx quanto o PHP-FPM terão a possibilidade de fazer um "Graceful Shutdown" assim que o supervisord receber o sinal SIGTERM.
Prioridade dos processos dentro do container
Bom temos uma aplicação PHP sendo executada em produção e seguimos tudo que foi falado até agora, estamos executando tanto o php-fpm quanto o nginx, ambos rodando sobre o supervisord, porém por incrível que pareça estamos notando o erro 502 durante o deploy. Isso acontece porque durante o deploy um novo container é criado e o supervisord simplesmente não sabe qual processo deve iniciar primeiro, se por acaso o nginx estiver pronto para receber um request, mas o php-fpm ainda não foi corretamente iniciado então temos um 502. Resolver esse problema de prioridade entre os processos é relativamente simples, o supervisord tem uma flag priority que tem o proposito de dizer quem é o processo de maior prioridade, entre outras palavras esse processo deve ser criado primeiro e morrer por último, a seguir segue uma configuração real de uma aplicação da Convenia em produção:
[supervisord]
nodaemon=true
[program:nginx]
command = nginx -c /etc/nginx/nginx.conf -g 'daemon off;'
user = app
autostart = true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
redirect_stderr=true
[program:php-fpm]
command = /usr/sbin/php-fpm7 -F
priority = 1
user = app
autostart = true
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
redirect_stderr=true
Esse é um arquivo de configuração do supervisord, perceba a configuração do php-fpm priority = 1, essa configuração vai instruir o supervisord a criar o php-fpm primeiro e a desligar ele por último, agora sim temos um deploy perfeito, sem downtime.
Conclusão
Para alcançar um deploy perfeito não adianta simplesmente utilizar os orquestradores mais poderosos do mercado, precisamos tomar alguns cuidados com o nosso container e aplicação também:
- Garantir que a aplicação é capaz de fazer um Graceful Shutdown
- Garantir que a aplicação está recebendo os sinais de desligamento corretamente, ou mantendo a aplicação como sendo o primeiro processo dentro do container, ou utilizando alguma ferramenta como o supervisord que propaga os sinais que ela recebe.
- Garantir que os processos estão sendo iniciados e desligados na ordem correta, caso o container rode mais de um processo.
Tomado esses cuidados estamos prontos para ter um deploy sem Downtime.

Top comments (0)