Programmers are often interested in the Tree vs Graph comparison. To begin with, know that trees and graphs both are non-linear, non-primitive types of data structure.
Both use nodes to represent many structures that are used to solve real-world problems albeit differently. The tree uses the hierarchical model to represent its structure, whereas a graph uses the network model to represent its structure.

There are two types of non-linear data structure:
- Tree
- Graph
Tree
A tree is a progressive model information design and it is an assortment of a limited number of information components. Here information components are hubs. In the tree information structure, the fundamental hub is the root hub, the highest hub of the construction, and the wide range of various hubs are its kids, grandkids, etc hubs.
There are many kinds of tree information structures. How components are put away in the tree information structure relies on the particular kind of equivalent.
Tree Properties
- Root Node
- Edge
- Parent Node
- Child Node
- Leaf Node
- Subtree
- Level
Graph
A graph is likewise a non-straight information structure. It is an assortment of two sets; vertices and edges, where vertices are the hubs and edges are the arrangements of components that interface the two vertices.
The graph information structure follows an organization model to address its construction and the organization model can frame a shut circle. There are many sorts of graphs and how the vertices are associated with edges relies on the particular kind of graphs.
Properties of a Graph
- Edges
- Vertices
- Cycle
Difference between tree and graph:
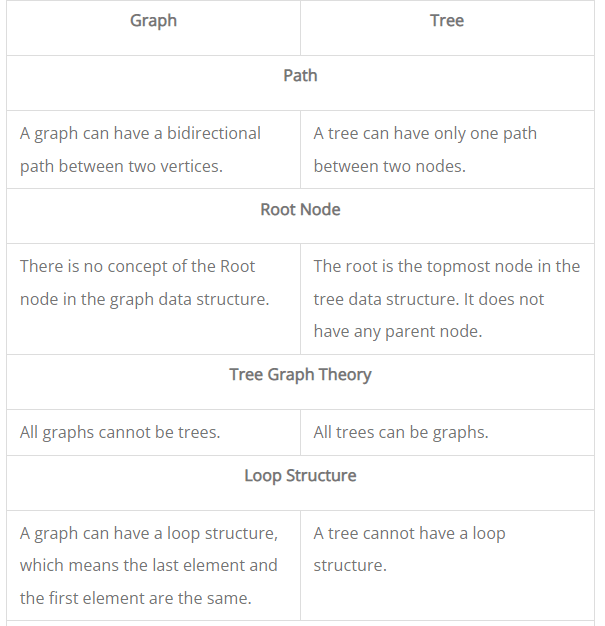

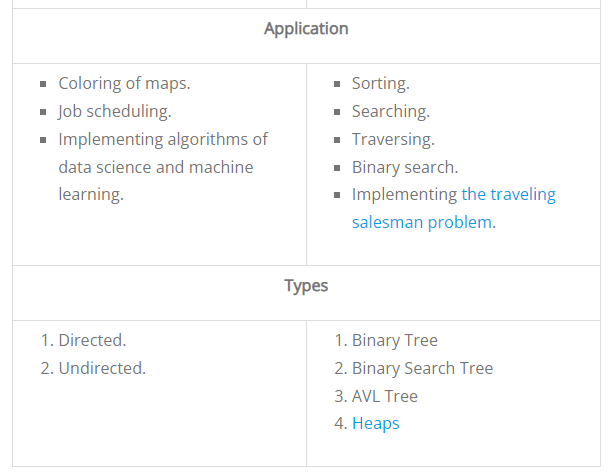
Conclusion
That is the finish of the Tree vs Graph discussion; Also the distinction between tree and graph. To summarize, although the two trees and graphs are non-direct kinds of information structures, the tree information structure follows a legitimate construction while there is no particular design followed by a graph.

Top comments (0)