
I have very no weaknesses at all.
Besides my weakness for sugar.
And beer.
And junk food.
Okay maybe I have a few weaknesses. But if I had a main one that affects a lot of aspects of my waking life, it'd be that I tend not to handle stress very well. I get grumpy, or shut off, or sad. Sometimes all of them. Truly I am a man of many talents. Anyway, my point is it's already the beginning of week 2 of semester 5 and I feel like I may have bitten off more than I could chew with my courseload. Let's see what happens.
Anyway, after a big initial "sprint" followed by nothing until today, I have finally gotten my stuff together for my release 0.1 appropriate titled: He's Dead, Jim. You can find it there under Releases. Please don't sue me, CBS.
My github also documents how the project works and how it was made but this post will act as a historian for the development of the release, along with a few examples of its usage.

I started out the project with a bit of knowledge in Python. I self-taught it in-between Semester 3 and 4 to write some projects to help me land a co-op position and increase my marketability. It worked and I actually landed a co-op position at Ontario's Ministry of Transportation involving Maching Learning specifically using Python.
I'm by no means at all a Python Expert, in fact my Python knowledge is about as developed as I am (see: not very). It is, however, more than enough for a smol project like this though, but more importantly I had a lot of fun doing it. I really wanted to learn something new like Rust or GO, but after reading some documentation (and realizing how rusty my experience in strongly typed languages are) I got discouraged and rebounded to my comfort zone.
Anyway, the first step was to parse a specified url. So my first step was to figure out how to parse arguments using the Argparser library. I wish I had started this step using a library like Click but by the time I discovered it I was already nearly done the project. Working with Argparse was not fun but i got it to work after a while of playing with it.
Once arguments were successfully taken in and stored I began to develop the actual link scraper, which wasn't too hard using Beautiful Soup. It's fantastically documented and easy to use. Beautiful Soup's usage depends on which argument is specified by the user. It parses the html file and stores each link it finds.
For each it finds the requests library sends a request to see if the link is still alive. If the link returns a good result, the link works. If not, well, it's dead jim.
The project features link parsing for both local HTML files and URLs specified to the python file. The project must also have two optional features. For release 0.1 I chose:
- colourize your output. Good URLs should be printed in green, bad URLs in red, and unknown URLs in gray
- running the tool with the v or version argument should print the name of the tool and its version
How to use it
Python must be installed on your machine. Once it's installed simply download hdj.py and run it from your command-line with python hdj.py.
Here's a few screenshots of it running on my Windows desktop:
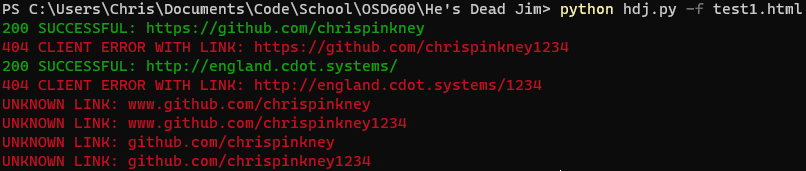

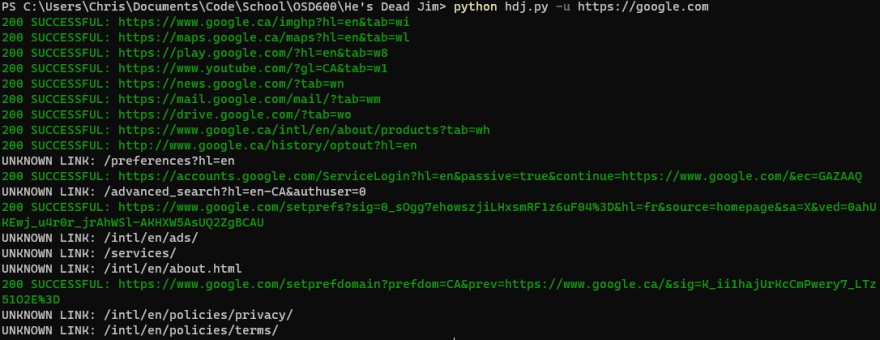
Haha in hindsight I noticed the last part of the first optional feature says and unknown URLs in gray. Whoops. I just made the change now but the library I'm using doesn't support grey so I used white. If my prof asks, I'm colour blind.
You know, in hindsight a requirement of our project probably should have included a timer to specify a fifth of a second in between requests. Ah well, how much is bandwidth these days, anyway?





Top comments (0)