You’ve probably heard about the importance of data quality being shouted from every rooftop. Bad data is a recipe for disaster. Certain companies have specialised in finding anomalies in your data and flagging it, much like Sifflet and Elementary. But what if we wanted to build an anomaly detector which works for any type of data, structured or unstructured, textual or numeric, include it in our data pipeline and do automated transformation steps… the possibilities are endless!
I’ve created a series of articles following the journey of building an anomaly detector for various situations, featuring OpenAI and BigQuery. In this first article, we’ll focus on building an anomaly detector using a LLM (Large Language Model), more specifically OpenAI.
What is an anomaly detector?
In simple words, an anomaly detector identifies bad quality data. In more technical terms, anomaly detection is used to identify significant deviations from the normal behavioural pattern. By identifying these faults, you can take action against potential sources of bad data and ensure that your data-use remains un-skewed, robust and defect-free.
Why use LLMs like OpenAI?
We want our anomaly detector to be as flexible as possible and to be able to identify anomalies no matter how structured the data is, how it is formatted, where it originates from, etc. It may be rare for you to have this number of uncertainties, but when you do, a conventional approach to anomaly detection may be more difficult to apply. Conventional approaches include using models like auto-encoders, ARIMA (auto-regressive integrated moving average), etc. Another point is - curiosity! LLMs are becoming more and more popular, but how efficient are they at more complex tasks such as anomaly detection and at what cost? That’s what we are about to find out.
Part 1: Building a basic OpenAI anomaly detection
To start, make sure that you have everything setup to use OpenAI. You can find more information on how to get started in this article.
To test that everything is working, we can try out some relatively simple code:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "system",
"content": "You are a data analyser. You spot any anomaly in the data received.",
},
{
"role": "user",
"content": "Here is the data input I have: {'id': 1, 'date': '1946-01-03', 'cost': '3.0'}, {'id': 2, 'date': '1852-03-04', 'cost': '3.0'}, {'id': 2, 'date': '1852-03-04', 'cost': '-1.0'}",
}
])
When running this, OpenAI does relatively well. It can pick up on issues like the one above with the cost being a negative value. But this seems too easy, what if we give it more complex data?
As soon as you start to look at more lines of code with more complex anomalies, accuracy starts to drop. For this experiment, let’s use data from the Electricity Consumption UK 2009-2023 dataset.
We can test the anomaly detector using different scenarios, varying the following parameters:
- Model used: either GPT 3.5 Turbo 1106 or GPT 4 1106 Preview
- Number of anomalies: 0, 1, or 2
- Number of lines of training data: 0, 10, 50 or 100
- Number of lines of test data: 4, 21 or 80
In a surprisingly high number of cases, OpenAI could find none of the anomalies! While a lot of the experiments gave a low accuracy, there are some combinations that shone through. The key statistics are:
- GPT 4 tended to perform much better than GPT 3.5
- The more anomalies you have, the more difficult it was for the model to find them
- The number of lines of data didn’t have a significant impact on the accuracy
To give you an idea of the outcome, here are the combinations which had a non-zero accuracy:
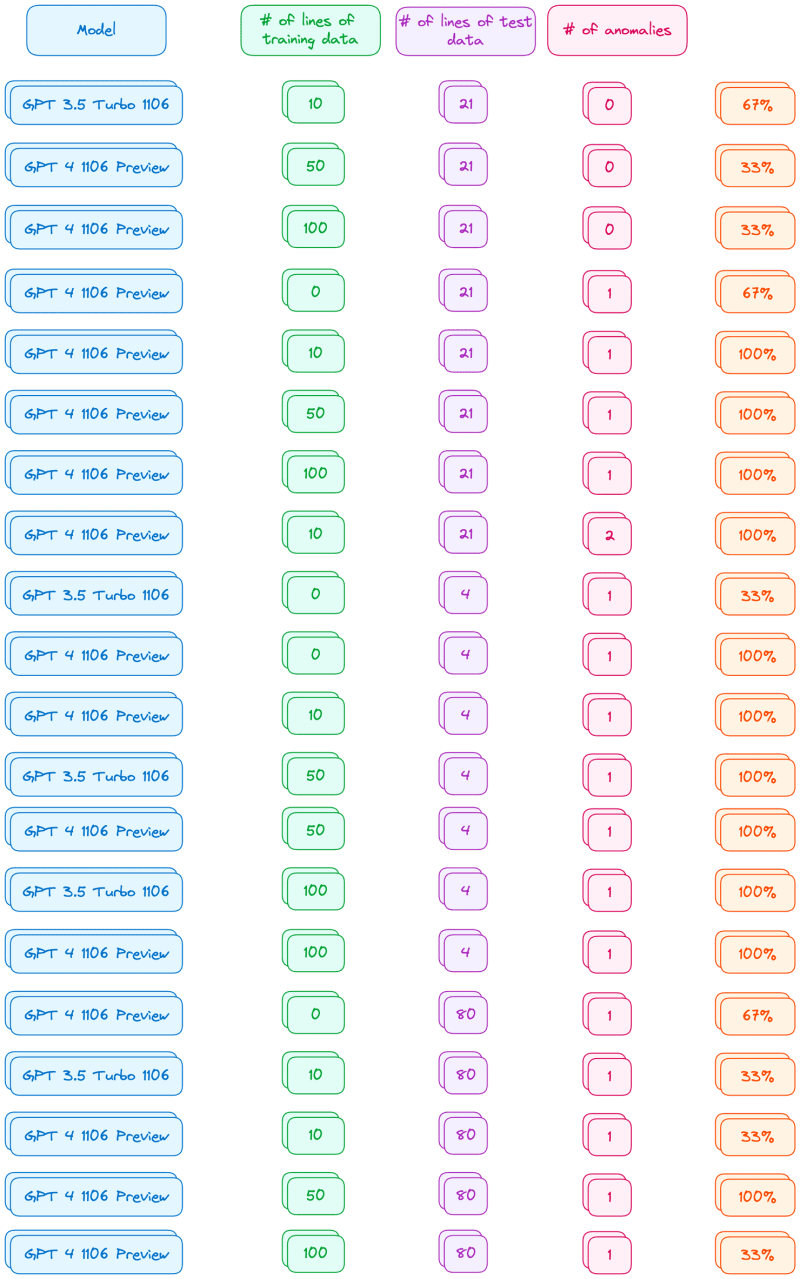
The results aren’t great but we are far from done! As is, we wouldn’t be able to use OpenAI as an anomaly detector. Our experiments are on a small scale. As the dataset we analyse grows along with the number of anomalies, our accuracy will very much suffer. Keep in mind that throughout this article we are testing our anomaly detector with simple datasets and results may differ depending on the dataset you use and the type of anomalies you have.
Part 2: Using Prompt Engineering to boost our accuracy from 32% to 64%
The idea behind prompt engineering is to construct the queries given to the language models to optimise their performance. This helps to guide them to generate the desired output by fine-tuning their response. There is a plethora of research papers out there on different forms of prompt engineering. DAIR.AI published a guide on prompt engineering that you might find useful to get started.
After trying a variety of different prompt engineering methods, there are 3 key techniques which stood out.
Chain of Thought
When using Chain-of-Thought (CoT) prompting, we are encouraging the model to break down complex processes or “thoughts” into smaller steps before giving a response. CoT can be combined with other prompting techniques (e.g. few-shot as we’ll see later), but we can also apply it on its own. The key is to get the model to think step by step. A way to do this is by adding the following to your prompt:
Let’s think step by step
By doing so, you are encouraging your model to break down its thinking. So what does our solution look like now?
import csv
from openai import OpenAI
client = OpenAI()
# Step 1: Consider you have a CSV, convert the data into a stringified JSON
def read_csv(file_path):
with open(file_path, "r") as file:
reader = csv.reader(file)
data = [row for row in reader]
file.close()
return "\n".join([",".join(row) for row in data])
data_with_anomaly = read_csv("path/to/file.csv")
# Step 2: Determine the messages to send to the model
messages = [
{
"role": "system",
"content": """You are a data analyser which spots any anomaly
in the data received. You will be given data in the form
of a CSV. There can be no anomaly but there can also be
multiple anomalies. Let’s think step by step. First work out
the schema of the data you receive. Then compare the data you
have to the schema you determined. Don't decide what is an
anomaly until you have figured out the schema.""",
},
{
"role": "user",
"content": "Here is the data to analyse, what are the anomalies? Please give me the line number with the anomaly. Make sure to remember on which line of the CSV the anomaly was (ignore the first line since these are the column titles): "
+ data_with_anomaly,
},
]
# Step 3: Get the response from the model
response = client.chat.completions.create(
model=model, # Add the model you would like to use, e.g. gpt-3.5-turbo-1106 or gpt-4-1106-preview
messages=messages,
max_tokens=1000,
)
# Step 4: Show the anomaly
print(response.choices[0].message.content)
To keep our experiments fair, we will fix certain parameters. When applying the different prompt engineering techniques, we will keep the number of anomalies in our data to 2 and we will use 20 lines of data in the CSV with the anomalies. These numbers were chosen arbitrarily.
By applying CoT on the anomaly detector, GPT 4 performed 8% better while GPT 3.5 did not show any significant change.
Few-Shot Prompting
Using few-shot prompting, we provide examples of how the model should be responding to the prompts that we give it. This is valuable for more complex tasks, e.g. anomaly detection, by demonstrating to the model how it should be responding given a certain prompt.
In our case, we can give the model example data with an anomaly and then give it the expected response with the correct anomalies being identified. Let’s give it a shot!
import csv
from openai import OpenAI
client = OpenAI()
def read_csv(file_path):
with open(file_path, "r") as file:
reader = csv.reader(file)
data = [row for row in reader]
file.close()
return "\n".join([",".join(row) for row in data])
data_with_anomaly = read_csv("path/to/file.csv")
# Step 1: Extract data from three CSVs with example data inside them
data_with_anomaly_1 = read_csv("bad_data_example_1.csv")
data_with_anomaly_2 = read_csv("bad_data_example_2.csv")
data_with_no_anomaly = read_csv("data_with_no_anomaly.csv")
# Step 2: Define the anomalies present in each file with the reasoning behind it
expected_response_1 = """Taking my time to look through the data, I noticed the following:
1. In row 1, the value for 'ND' is zero. In all the other rows, the 'ND' value is non-zero. This is an anomaly.
2. In row 3, the value for 'ENGLAND_WALES_DEMAND' is a negative value. In all the other rows, this is a positive value. This is an anomaly.
3. In row 6, the value for 'EMBEDDED_SOLAR_CAPACITY' is missing. In all the other rows, this value is present. This is an anomaly.
"""
expected_response_2 = """Taking my time to look through the data, I noticed the following:
1. In row 2, the value for 'TSD' is 100. In all the other rows, this value varies between 24244 and 48195. Since this value is very out of range, it is an anomaly.
2. In row 3, the value for 'EMBEDDED_WIND_GENERATION' is 10. In all the other rows, this value varies between 24244 and 48195. Since this value is very out of range, it is an anomaly.
3. In row 7, the value for 'EMBEDDED_SOLAR_GENERATION' is a negative value. In all the other rows, this is a positive value. This is an anomaly.
4. In row 10, the value for 'ENGLAND_WALES_DEMAND' and 'EMBEDDED_WIND_GENERATION' are missing. In all the other rows, this value is present. This is an anomaly.
5. In row 12, the value for 'NON_BM_STOR' is not zero. In all the other rows, this value is zero. This is an anomaly.
6. In row 15, the value for 'MOYLE_FLOW' is zero. In all the other rows, this value is not zero. This is an anomaly.
"""
expected_response_no_anomaly = "After comparing the values of each row to each other, all the data seems to be consistent with each other, I cannot find an anomaly."
# Step 3: Let us adapt the messages we send to the model with this information
messages = [
{
"role": "system",
"content": """You are a data analyser which spots any anomaly
in the data received. You will be given data in the form
of a CSV. There can be no anomaly but there can also be
multiple anomalies.""",
},
{
"role": "user",
"content": "Here is the data to analyse: " + data_with_anomaly_1,
},
{"role": "assistant", "content": expected_response_1},
{
"role": "user",
"content": "Here is the data to analyse: " + data_with_no_anomaly,
},
{"role": "assistant", "content": expected_response_no_anomaly},
{
"role": "user",
"content": "Here is the data to analyse, what are the anomalies? Please give me the line number with the anomaly. Make sure to remember on which line of the CSV the anomaly was (ignore the first line since these are the column titles): "
+ data_with_anomaly,
},
]
# Step 4: As before, get the response from the model
response = client.chat.completions.create(
model=model, # Add the model you would like to use, e.g. gpt-3.5-turbo-1106 or gpt-4-1106-preview
messages=messages,
max_tokens=1000,
)
# Step 5: As before, show the anomaly
print(response.choices[0].message.content)
Try giving this a run and you’ll notice that few-shot prompting leads to a massive jump when using GPT 4. The accuracy of the anomaly detector goes from 32% to 56% for GPT4! Unfortunately, it stays relatively constant for GPT 3.5.
Self-reflection & multi-step
For our last experiment with prompt engineering, we’re going to try splitting our model into multiple steps and pushing it to self reflect on its findings.
We are going to split our model into three with each step having different responsibilities. The first step will aim to find the anomalies, similar to what we saw above. The second step will trigger a self-reflection and will present the previous prompt and ask it “Are you sure?”. The last step will convert the response to JSON to standardise the finding of the anomalies so that we can use the response moving forward.

Let’s see what this looks like in code:
# All the code above still applies
...
first_answer = response.choices[0].message.content
# Step 1: Append our previous answer to our messages
messages.append({"role": "assistant", "content": first_answer})
# Step 2: Add some self reflection
messages.append(
{
"role": "user",
"content": "Are you sure? How confident are you? Take a deep breathe and tell me the anomalies when you are more sure.",
}
)
# Step 3: Run the model
completion = client.chat.completions.create(
model=model, # Add the model you would like to use, e.g. gpt-3.5-turbo-1106 or gpt-4-1106-preview
messages=messages,
max_tokens=1000,
)
response_with_self_reflection = completion.choices[0].message.content
# Step 4: Convert your answer to a JSON response
json_structure = {
"anomaly_count": "number of anomalies found in the text, of type 'int'",
"anomalies": [
{
"id": "the row number where the anomaly was found. Ignore the first row of the CSV since it has the column names. Of type 'int'",
"description": "why this is considered an anomaly, of type 'string'",
}
],
}
json_response = client.chat.completions.create(
model="gpt-3.5-turbo-1106", # Can use a simpler model to do the conversion
messages=[
{
"role": "system",
"content": "You convert a text response into a json object. "
+ f"I want you to only give responses in the form {json.dumps(json_structure)}\n",
},
{
"role": "user",
"content": f"Convert this response to a json object: {response_with_self_reflection}",
},
],
max_tokens=1000,
response_format={"type": "json_object"},
)
# Step 5: Display the results
print(json_response.choices[0].message.content)
Voila! You’ve now got few shot-learning integrated along with self-reflection & multi-step. When running the experiment and removing few-shot (i.e. only using self-reflection & multi-step), GPT 4 saw an improvement from 32% to 60% (unfortunately, GPT 3.5 actually saw a drop in performance).
By combining CoT, few-shot, self-reflection & multi-step, the overall performance of GPT 4 goes from 32% to 68%! On the other hand, the performance of GPT 3.5 doesn’t really see any significant improvement. If we focus on GPT 4, here is a summary of how prompt engineering impacted the accuracy of our anomaly detector:
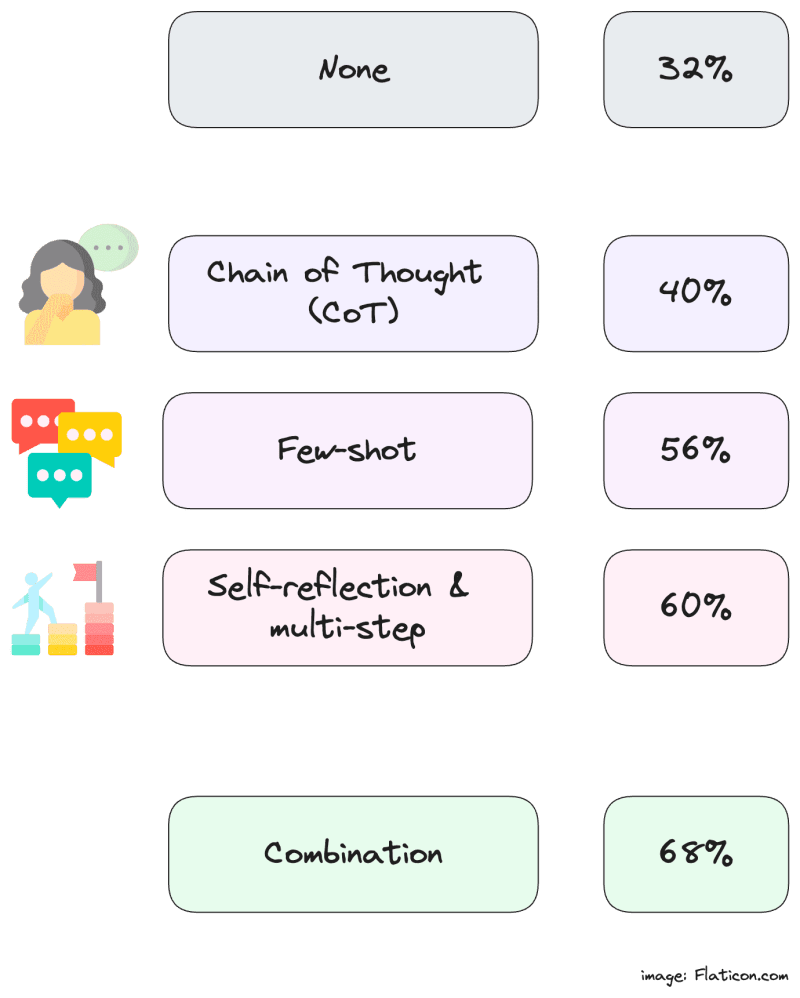
Pretty good! But a 68% accuracy is not amazing and GPT 3.5 seems to be really struggling to improve its accuracy with the anomaly detector. Why is this the case? If we take a closer look at our data, we see that we are using numerical data:
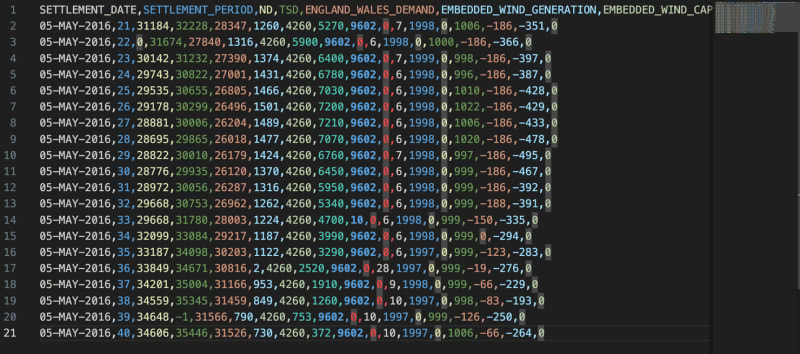
Having a search, you’ll quickly see that the GPT models are bad at maths. This is to be expected, they are language models and aren’t trained on mathematical concepts.
We can test this theory by swapping out our data to text-based data.
How does data type impact the accuracy of our anomaly detector?
Let’s try to swap out our data for movie reviews instead.
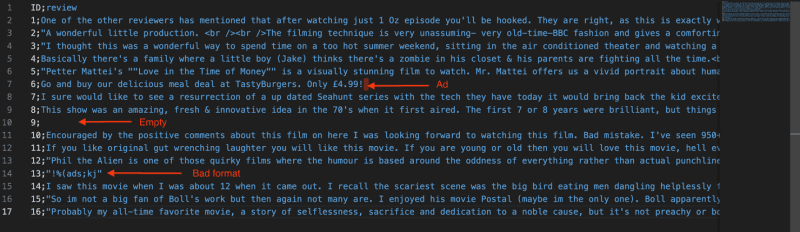
When running our anomaly detector on this data (using the prompt engineering techniques above), we see that:
- GPT 3.5 has an accuracy which jumps from 16% (numerical data) to 78% (text-based data)
- GPT 4 has an accuracy which jumps from 68% (numerical) to ~100%(text-based)
This is an incredible jump and reflects the importance of choosing the correct model based on your application.
Conclusion
OpenAI can be used to build an effective anomaly detector for text-based data. Our model can be optimised using techniques such as prompt engineering. On the other hand, while we can improve the performance of our anomaly detector for numerical data, it is still relatively limited. So what can we use? Keep an eye out for the next article on using BigQuery for anomaly detection on numerical data!
This article is part of a series on the journey of building an anomaly detector. I share the progress of the journey regularly on X (formerly Twitter), have a look at @ChloeCaronEng!





Top comments (0)