
Ever thought, if a database gives you capabilities of both SQL and noSQL databases. You will be able to perform the traditional SQL operations(joins, group by, order by, etc.) as well as leverage the noSQL capabilities like document store, schemaless data modeling, API based query execution etc.
You should have used various databases as per your use cases. MySQL, PostgreSQL etc. are the big players in the SQL world but as your data goes unstructured and bigger, SQL will not help as much. One will find a better alternative for dealing with big data, that's when noSQL comes into picture. MongoDB, Cassandra, DynamoDB etc. are the widely used noSQL databases.
It’s not that one database is better than the other, it’s that one is a better fit for a specific use case due to numerous factors.
If you want to learn more about database use cases then check out this article Database Architectures & Use Cases - Explained by Margo McCabe
What the heck is NewSQL?
Wikipedia defines NewSQL as:
“ NewSQL is a class of relational database management systems that seek to provide the scalability of NoSQL systems for online transaction processing (OLTP) workloads while maintaining the ACID guarantees of a traditional database system.
Many enterprise systems that handle high-profile data (e.g., financial and order processing systems) are too large for conventional relational databases, but have transactional and consistency requirements that are not practical for NoSQL systems.[5][6] The only options previously available for these organizations were to either purchase more powerful computers or to develop custom middleware that distributes requests over conventional DBMS. Both approaches feature high infrastructure costs and/or development costs. NewSQL systems attempt to reconcile the conflicts.”
So, What is HarperDB?
HarperDB is a SQL/noSQL data management solution. It is fully indexed, doesn't duplicate data, and runs on any device - from the edge to the cloud. It has been built natively as a set of micro-services, making development and integration easy and seamless.
Both SQL and noSQL are contributing to the industry for their uses cases. HarperDB was built to serves both the use cases, taking advantage of the capabilities of both technologies.
What makes it different from other databases?
Its storage engine makes it different from other players. It follows Exploded Data Model, when it ingests a record it immediately splits that record up into individual attributes, storing the attributes and their values discreetly on disk. It uses the required hash value to link the attributes together. That is what exploded means.
Check this article HarperDB’s Exploded Data Model for more info
How HarperDB is a game changer in the data world?
Its SQL/noSQL capabilities make it a game changer. Most noSQL databases adopted multimodel architecture to support complex SQL queries. Multimodel under the hood is basically like running two different databases. HarperDB is designed to handle both SQL and noSQL use cases. When data is inserted into HarperDB either via SQL statements or noSQL objects, it maps this data to a single model. Data is never replicated and nothing ever needs to be transformed after insert.
Following are some features of HarperDB that make it an out of the box solution..
Exploded Model:
The storage engine follows an outside the box storage model they call it an "Exploded Model". when it ingests a record it immediately splits that record up into individual attributes, storing the attributes and their values discreetly on disk. It uses the required hash value to link the attributes together. This is what gives it the capability to behave as a NewSQL database.
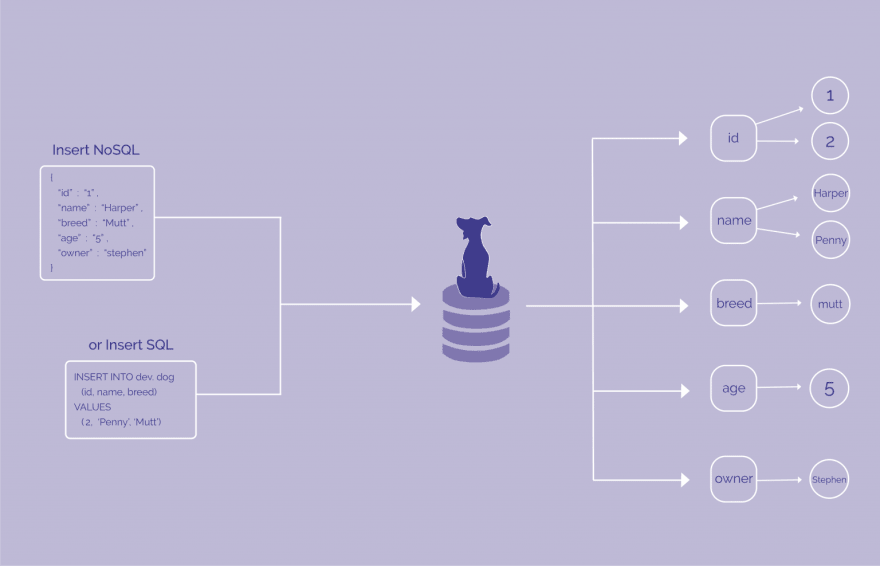
image source: harperdb.io
Fully Indexed:
The way its storage engine behaves is by storing the attributes individually following an exploded model, the attributes(or columns) immediately become an index on write. All attributes as indexed in the write time.
No Data Duplication:
Full indexing capability on the write time makes it a no data duplication DB. Its storage engine removes the on-demand indexing as table is fully indexed due to its exploded model.
Dynamic Schema:
It neither stores your data as a document nor in a tabular format, rather it atomizes every record into its individual attributes(or columns) and saves them discreetly on disk.
And with every new writes if the query contains new attributes then the attributes are automatically defined for every records of the table with a null value. That's what Dynamic Schema means.
Developer friendly:
One of the advantages of using HarperDB is that it is developer friendly. It has been built natively as micro-services, you can perform various database operations as an API call. Also its architecture gives you options to work with SQL and noSQL queries. Due to its REST architecture for interacting with DB, this makes easier for any developer to adapt with HarperDB. Also there are various adapters/drivers/client available for different languages, one can start working with very easily.
One such HarperDB's NodeJS client Harperive has been published as an npm package by myself. Give it try.
Following is an example of how insert operation can be performed as SQL and noSQL way.
To execute a query you need to define operation type and the parameters needed to perform the operation.
Refer HarperDB's API docs for various DB operation and examples on most programming language.
- SQL
curl --location --request POST 'http://localhost:9925' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic SERCX0FETUlOOjE0MDA=' \
--data-raw '{
"operation":"sql",
"sql": "INSERT INTO dev.dog (id, name) VALUES(2, '\''Simon'\'')"
}'
- noSQL
curl --location --request POST 'http://localhost:9925' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic SERCX0FETUlOOnBhc3N3b3Jk' \
--data-raw '{
"operation":"insert",
"schema":"dev",
"table":"dog",
"records": [
{
"name":"Harper",
"breed":"Mutt",
"id":"1",
"age":5
},
{
"name":"Penny",
"breed":"Mutt",
"id":"3",
"age":5
}
]
}'
Conclusion
I personally feels that the new Storage Engine, the HarperDB team has built is definitely a game changer in the technology industry. Its capability to serve both SQL and noSQL features is revolutionary.
A database must also have a good logging system, so that every executed query can tracked and debugged. Currently HarperDB's logging system is amateur which just do basic logging. I submitted my thoughts about logging to HarperDB on their feedback board and they are actively working on adding a robust logging system to meet audit requirements. I'm told that this will be included in the next HarperDB release.





Top comments (1)
Cool thing is that HarperDB is 37.9 times faster than MongoDB 🔥