In this beginner's friendly tutorial we will be coding a simple Python script to track the prices of your most wanted products 🤑 (this way you'll never miss those sweet deals 😉) in 5 simple steps:
- 1-creating a CSV file to store your wishlist and each item's target prices;
- 2-getting the price of an item using an URL;
- 3-checking if the price is below a target value;
- 4-checking all items of a wishlist;
- 5-automatic script running (Windows and Linux).
In the end you'll have a script that builds a wishlist in a file by adding new items and checks the price of all items in it, warning you if it's the perfect time to spend your money (no more infinite tabs to check every once in a while).
You'll feel like a hacker after this! 🕵️ 👩💻
Let's go!
Python libraries we need:
For this project you'll need some Python libraries 🐍, I'll go through them briefly so you get a general idea about them (more exploration is encouraged 🔍).
Make sure you have these installed, if not you can pay a visit to our best friend "The" shell (or terminal).
-requests: allows you to make HTTP requests, meaning getting the content of a webpage;
-BeautifulSoup4: parses the content extracted from a webpage;
-csv: library to read and write CSV (Comma-Separated Values) format files;
-re: package to use regular expression matching operations. Very powerful to filter strings by matching a specific pattern;
-os: provides ways to interact with your operating system (removing files, changing current directory, etc.).
Step 1: Creating a CSV wishlist
First we need to store our wanted items in a wishlist. This way our script will be able to check the prices of every item without us moving a finger (laziness intensifies 😏).
But what information should the wishlist hold?
Short answer, whatever you want and/or need. In this tutorial we'll be using 3 features to describe each item: the name of the item as in the web page; its web address; and the maximum price we are willing to pay for it (let's call it target price).
To avoid creating a CSV file by hand with our wishlist with the following information,
item's name , in store url , target price
we can make the script create and add new items to the list for us.
So, what's the strategy? 🤔
We are going to start implementing our price tracker function. To make it create and modify the wishlist for us we need to give it some information as input: the path where we want to store the wishlist; the url of the item we want to add; the maximum price we want to pay for that item.
import requests
import bs4
import csv
import re
from os.path import exists
def tracker(filepath , item='' , target=0):
Wait a second... 😑
Did we just forget to define the item's name as an input? Well, if you want you can add it but with the URL we can retrieve that information easily.
Our function is named tracker and receives a mandatory argument, the path to store the CSV (filepath), and 2 optional arguments, the item to be added and the target price.
The first optional input argument of our function, item, receives a string which corresponds to the url of the item we want to add to our wishlist. To add the item, first we need to check if there is a wishlist in the path given by the user or a new one will be created:
if len(item) != 0:
if not exists(filepath):
f = open(filepath , 'w' , encoding='UTF8')
else:
f = open(filepath , 'a')
writer = csv.writer(f)
Remember that we want to have 3 features for each item. The function took as input 2 of them, the URL and the target price (0 if not specified by the user). We are missing the item's name... The process of getting it from the URL is the same as retrieving it's current price so let's get to the powerful part of the tutorial! 🐱🏍
Step 2: Getting information of an item using an URL
Who has ever randomly pressed a keyboard key while browsing and something really weird (and scary 😬) came up on the side of the webpage? 🙋♀️
 |
|---|
| Figure 1. Weird scary stuff that pops up on the browser. |
The F12 key opens the browser's Developer Tools and, to make it simple, it allows everyone to see the code that is behind a webpage. This includes every piece of text that is being displayed (which is what we are looking for). So, what we want is Python to have access to the code shown in the Developer Tools and get the information we want.
First, we need Python to mimic us when we open an URL and copy the code behind it. This can be done with the requests library:
rq = requests.get(item , headers=({'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36', 'Accept-Language': 'en-US, en;q=0.5'}))
where item is the url. You don't need to worry much about the headers argument of the get() but if you are curious on why we are passing that information read the note below, else just skip it. ⏩
NOTE: When we use a browser to access a webpage, the servers hosting the page know which browser the user is using so it can send the page optimized to that specific browser. If this information is not available then we may run into some problems: the code gotten from the request is not the same as the one we see in our browser; the server can block unrecognized traffic so it prevents Python to get the info. In this tutorial we are pretending to be using Mozilla Firefox 😉. In addition to this, we want to get the webpage in English despite of our system's preferences.
This code line outputs a Response object, to easily access the information it contains we use BeautifulSoup so everything stays nice and pretty in a nested structure which makes it a breeze to navigate. 🧭
info = bs4.BeautifulSoup(rq.content , features='lxml')
and if we print the variable (or store in a file) we will get something like this:
 |
|---|
| Figure 2. Retrieved information in a nested structure. |
Now that we have all the code behind the webpage let's extract what we want. First we are going to find out how to retrieve the item's name, to do this you need to find the id tag that holds that piece of information.
Open the url on your browser and press F12 to unveil the secrets of the universe! (not really... but it's something 😅).
Use the find command (ctrl+f) to search for the item's name, the one you can see in the webpage, and check the id, that's what we are going to use.
Remember the code we extracted from the webpage right before this? With the id that holds the item's name we can search the retrieved information using the following line of code (the strip() makes sure to remove all extra spaces):
name = info.find(id = "productTitle").get_text().strip()
Similarly, to get the item's price you just have to follow the same steps.
price = info.find(id = "price_inside_buybox").get_text().strip()
If you print the price variable you'll notice that it comes not only with numeric info but also the currency identifier (example: 'USD9.99'). This makes it impossible to compare it with a target price or do any kind of statistical approach, boring...🥱.
Let's get rid of it! To do that, we can split the price variable by a regular expression and keep the last bit ('9.99'). The goal is to split the string on the first number that appears. Adding this to the code line above comes:
price = re.split(r'(^[^\d]+)', info.find(id = "price_inside_buybox").get_text().strip())[-1]
Now we have all information needed to add the item into the CSV wishlist so let's do it.
writer.writerow([name , item , target , price])
In addition to the features of the item (name, url, target price), we'll also write the price we just retrieved. This way you can keep the price history (this can be used for lot's of cool stuff like a Machine Learning model to predict future price drops 🤩).
Step 3: Checking if it's time to buy
We added the item to our wishlist, now it's time for difficult decisions. Are we ready to drop the money? 🙄
If we declared the maximum amount of money we want to spend then, the target input variable will hold it and store a value different from 0 or negative (sorry to ruin the party but no one is going to pay you to get something 🤯 or is it... 😶) . Our Python script should let us know when the current price is under our buying limit.
if target > 0 and price <= target:
print("BUY IT NOW!!!!!!!!!!!!!!!!!!!")
Step 4: Checking all items of a wishlist
We are almost done, hang in there! 💪
Imagine we added 5 items into our wishlist and we want to check if any gets in our price range. To do this we have to: open the CSV file; extract every item's URL and target price; use the same code of Step 2 and Step 3; (bonus) store the current price on the CSV file.
fread = open(filepath , 'r')
items = list(csv.reader(fread))
fread.close()
fwrite = open(filepath , 'w')
wr = csv.writer(fwrite)
for i in range(len(items)):
rq = requests.get(items[i][1] , headers=({'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36', 'Accept-Language': 'en-US, en;q=0.5'}))
info = bs4.BeautifulSoup(rq.content , features='lxml')
price = re.split(r'(^[^\d]+)', info.find(id = "price_inside_buybox").get_text().strip())[-1]
items[i].append(price)
if items[i][2] > 0 and price <= items[i][2]:
print("BUY IT NOW!!!!!!!!!!!!!!!!!!!")
wr.writerows(items)
fwrite.close()
⚠ WARNING ⚠
If you run this script a considerable amount of times you can get an error stating that the id couldn't be found don't worry, this happens because the server hosting an URL has blocked you 🙁 . Each time you run this script a request is sent from your IP address to the target server, if the server gets several requests from you in a very short period of time it will classify your traffic as not normal and block your access. In this case just wait till the next day 😉.
To prevent the script from crashing if a URL is blocked, and still check the others, we can add some try and except blocks. Check the full code below.
import requests
import bs4
import csv
import re
from os.path import exists
def tracker(filepath , item='' , target=0):
if len(item) != 0:
if not exists(filepath):
f = open(filepath , 'w' , encoding='UTF8')
else:
f = open(filepath , 'a')
writer = csv.writer(f)
rq = requests.get(item , headers=({'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36', 'Accept-Language': 'en-US, en;q=0.5'}))
info = bs4.BeautifulSoup(rq.content , features='lxml')
try:
name = info.find(id = "productTitle").get_text().strip()
price = re.split(r'(^[^\d]+)', info.find(id = "price_inside_buybox").get_text().strip())[-1]
if target > 0 and price <= target:
print("BUY IT NOW!!!!!!!!!!!!!!!!!!!")
writer.writerow([name , item , target , price])
except:
raise Exception("Couldn't retrieve product's info")
else:
fread = open(filepath , 'r')
items = list(csv.reader(fread))
fread.close()
fwrite = open(filepath , 'w')
wr = csv.writer(fwrite)
for i in range(len(items)):
rq = requests.get(items[i][1] , headers=({'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36', 'Accept-Language': 'en-US, en;q=0.5'}))
info = bs4.BeautifulSoup(rq.content , features='lxml')
try:
price = re.split(r'(^[^\d]+)', info.find(id = "price_inside_buybox").get_text().strip())[-1]
items[i].append(price)
if items[i][2] > 0 and price <= items[i][2]:
print("BUY IT NOW!!!!!!!!!!!!!!!!!!!" + items[i][1])
except:
raise Exception("Couldn't retrieve product's info")
wr.writerows(items)
fwrite.close()
tracker("items.csv")
Step 5: Automatic script running
To have our script running everyday, without us worrying about it, we can schedule it to run at specific times.
Windows users
- First you need to create an executable which will run the script. To do that create a text file and change it's extention to .bat ;
- Inside the file, add the path to the Python executable in your computer and the path to the script in the following format: ```
pause
The *pause* prevents the terminal from closing after completion, you can remove it if you want. If you click the *.bat* file it will now run the script! To automatize the clicking action we will use the Windows Task Scheduler.
- Use the searcher to find Task Scheduler and click "Create Basic Task" ;
- Choose the task's name, occurrence frequency and trigger time;
- Give the path to the *.bat* file we just created;
- Finish!
|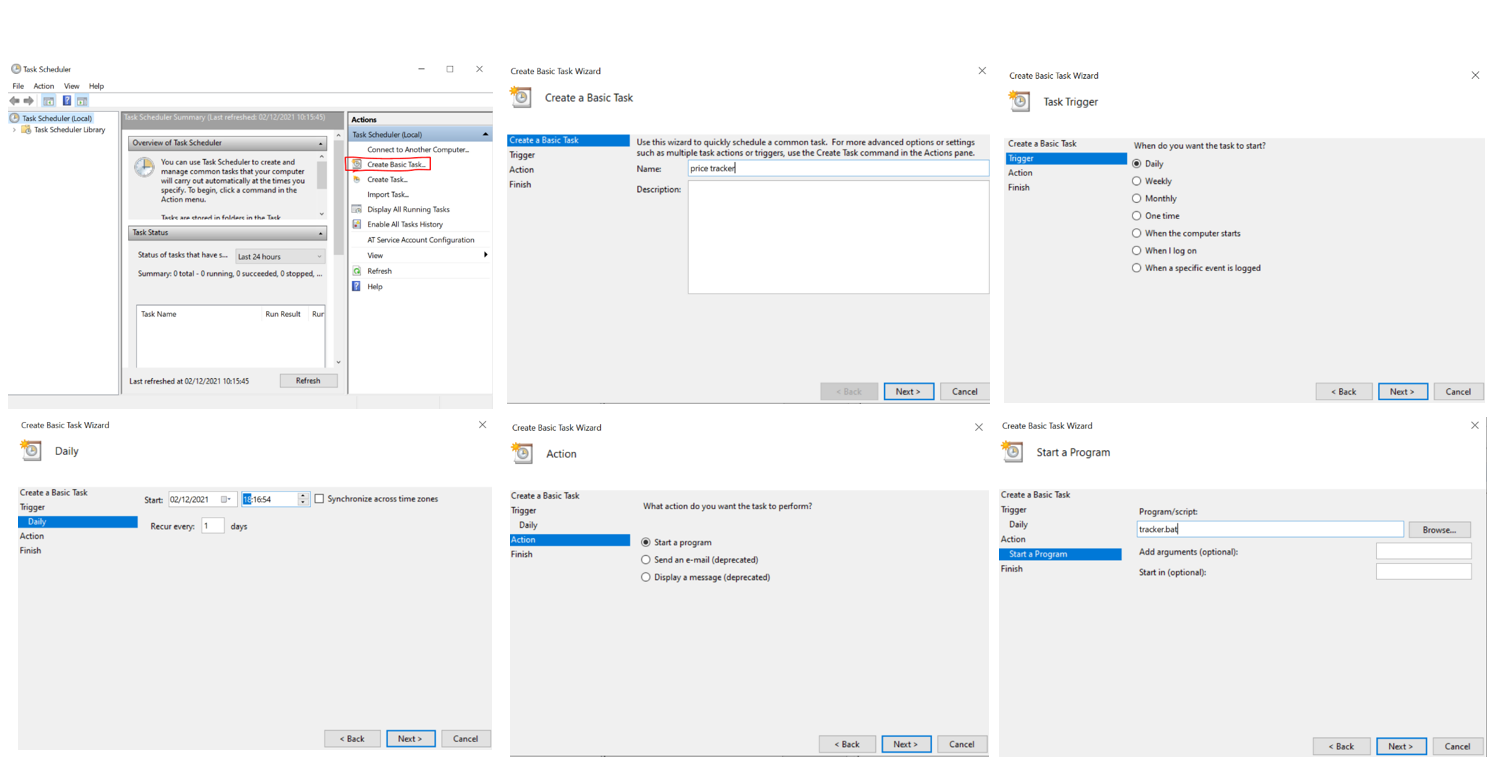|
|:--:|
| **Figure 3.** Steps to schedule a task on Windows.|
#### 🐧 **Linux users**
First we you need to make sure you have *cron* installed and enable to start on boot. If not, for fedora, do:
dnf install cronie cronie-anacron
systemctl enable crond
chkconfig crond on
Now we need to schedule the task using *cron*.
- Go to the terminal and do ```crontab
-e
``` to open the file where all scheduled tasks are, if any;
- Add a line with the following ```0
10 * * * python/path price/tracker/path
```. This means the script will run every day at 10a.m. To mess with the scheduling time you can use https://crontab.guru/ ;
- Save and exit. You should see this output on the terminal ```crontab:
installing new crontab
- Finish!
All set! Goodbye missed deals! 👏😁
❗BONUS TIP ❗
With this script you can do awesome things, just let your imagination run wild! I'll list some below, have fun! 🤗
-price predicter;
-price variation analysis;
-restock alerts;
-price comparison between several stores.

Top comments (0)