
Multi cloud has been touted as the magic pill for many cloud pain points: getting locked into the services of a single vendor, ensuring business continuity in the case of an outage, and having your cloud bill spiral out of control.
But more often than not, the effort of using multi cloud brings engineers more complexities to deal with - and a cost increase.
|
Multi cloud (CAST AI) |
Cluster federation (other services) |
|
A multi cloud cluster is a single cluster - the connection between clouds is at network level. Kubernetes doesn’t know that there are multiple cloud services or locations at play - it just sees a single network of nodes. |
A cluster federation is made of multiple clusters where the connection is at the level of Kubernetes. Great for coordinating the configuration of multiple clusters from a single set of APIs in a hosting cluster. |
|
Benefits:
|
Benefits:
|
So how do you actually run a multi cloud application that gives you the freedom to choose among the best-in-class services from various providers, prevents disasters, and helps you save, not increase, on the cloud?
This may sound too good to be true, but that’s the promise of multi cloud. And we guarantee that it works.
Take a look at this guide to see how multi cloud works in practice:
- What is multi cloud all about?
- What’s there to gain with multi cloud?
- How multi cloud works in CAST AI
- Case study: How multi cloud works in CAST AI
What is multi cloud all about?
In a multi cloud setup, teams can deploy applications and other assets across several cloud environments at the same time. A typical multi cloud architecture uses two or more public clouds, sometimes in combination with private clouds. In a Gartner survey, 81% of respondents admitted using two or more providers already.
Check out this video to learn more: Hybrid Cloud and MultiCloud | Why are companies adopting it?
Here’s how we understand multi cloud at the level of:
- Data - having a single source of data shared among different workloads, regardless of which public cloud service they’re in.
- Service - making services built in one cloud available for reuse in other cloud services. If you use Amazon RDS and have a process that uses the Machine Learning engine from Google Cloud, you should be able to make these things work together to use the best of both worlds.
- Workload - applications and data work together using abstract processes that may be installed in different VMs - some owned by AWS, others by Google Cloud or Azure.
Translated into the Kubernetes world, multi cloud means the ability to create and manage a Kubernetes cluster in any number of clouds. To the point where the number of cloud services becomes irrelevant.
Developers should be able to deploy their applications to clusters easier and then have these clusters optimized all the time. This is what true multi-cloud is for us.
This approach is on its way to becoming the core of the future multi cloud initiatives as more and more companies realize the limitations of monocloud setups and start looking for a better cost vs. performance balance.
What’s there to gain with multi cloud?
1. Cost optimization
A multi cloud environment gives you the freedom to compare different cloud providers and secure the best offers depending on your changing needs. You can choose services that offer exactly what you need - from flexible payments to customizable capacity. And a better price.
Here’s an example from our research:
Let's say that you have two instances with 4 CPU and 16 GB RAM from Google Cloud and AWS. Compare them and you’ll see that the instance from Google is 10% cheaper and offers 7% more compute capacity in the EU Central Frankfurt region.


2. Access to best-in-class services
To make the most of the public cloud services, engineers should be able to use the best services and features. In a multi cloud setting, a team can select a primary cloud provider and a secondary one for for extra value or carrying out a specific task (like machine learning training) and then bring the results over to the first cloud solution to build and deploy applications.
Say your team uses Amazon RDS but wants to use the Machine Learning engine from Azure - making these two things work together is possible if you go multi cloud.
3. Performance optimization
Optimizing performance across various cloud services is another perk of a multi cloud setup.
Say you have an application that experiences a sudden increase of requests per second. Your team can check which cloud service eligible for multi cloud (in a so-called Goldilocks Zone) has the available resources at the lowest possible price - and then start deploying additional capacity immediately.
4. Security
Multi cloud opens the doors to finding the best security solutions that might come in handy as your infrastructure and applications evolve. In this scenario, you’re free to switch providers anytime and find a good match for ensuring the security level you need or achieve compliance.
5. Disaster prevention
Even the most well-known cloud service vendors experience outages. Since downtime may have serious financial and reputational consequences for your business, you should do your best to avoid this risk.
One way to prevent this from happening is by replicating large parts of your infrastructure and workloads in two places. But it's a costly solution.
Here’s one that doesn’t increase your cloud bill: multi cloud. When one cloud service goes down, your business isn’t hurt in any way because your workloads and data are moved to other clouds.
How multi cloud works in CAST AI
CAST AI uses the Cloud Service Provider (CSP) accounts of its users to create the required cloud resources (VPCs, Resource Groups, and networking layer) and set up multi cloud clusters. It then selects the right regions with cross-cloud latency of no more than 10 ms in normal operation.
Here are a few multi cloud features we included to :
Active-Active Multi Cloud
Using the active-active approach, CAST AI replicated applications along with data across multiple cloud services. If one of them fails, others keep your workloads afloat and guarantee business continuity.
Global Server Load Balancing
Traffic is distributed evenly across all the participating clouds, choosing the cloud endpoints that are up and healthy.
Automated Data Movement
When working across cloud boundaries, it's essential that you can move data seamlessly. CAST AI provides automated block storage migration with advanced replication through our partners.
Multi-Region Mono-Cloud
A Kubernetes cluster in CAST AI works on a single cloud service stretched across multiple regions. Thanks to this, you can connect nearby regions with low latency and still secure the active-active approach to disaster prevention.
Cross-Node Live Migration
Moving pods from one node to another can cause disruptions, especially when the pods in question handle long-running transactions or network connections. Thanks to live migrations, pods can move and stay intact without breaking any connections.
Case study: How multi cloud works in CAST AI
TL;DR
Let’s put the CAST AI multi cloud feature to the test. Imagine that you have a cluster that consists of one worker node. We then deploy an app and find our that there’s not enough space for all the pods on the cluster. This is when CAST AI automatically scales up our setup with additional machines.
Sounds good so far? Then get this: CAST AI decided to add VMs from a different cloud provider because it judged them to be most cost-effective (including the use of spot instances for even more cost savings!). This is how multi cloud Kubernetes works in CAST AI.
Step 1: Create a multi cloud cluster
Let’s start by creating a cluster that has multi cloud capabilities. In the CAST AI platform, we can easily create a cluster in the US-East region spread between AWS and Google - in US-East-1 (Virginia). CAST AI automatically connects the cluster via Wireguard VPN - but we have a choice of the cloud VPN-as-a-service as well.
This is what the cluster creation dashboard looks like:
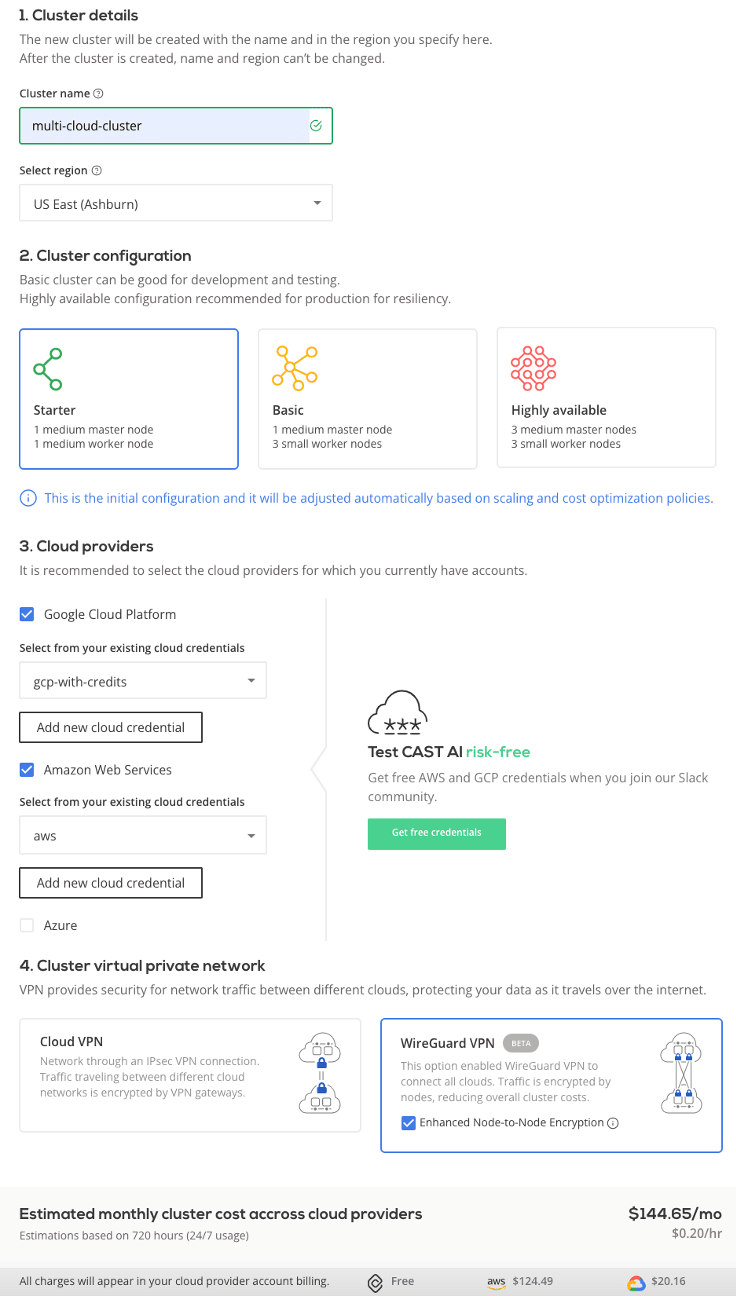
Our cluster is ready! It took me just 5 minutes.
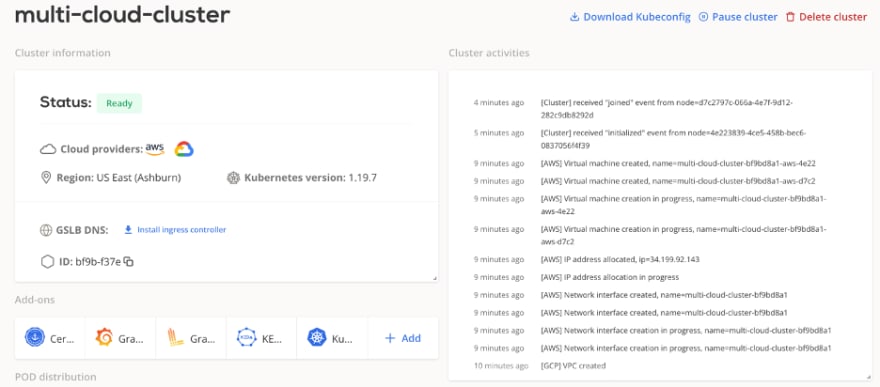
Let’s take a closer look at our cluster. It has one worker node and one master node. Both are hosted on AWS by default:

Next we download the Kubeconfig file and import it to Lens:

Here’s a visualization of our cluster composed of one master and one worker node.
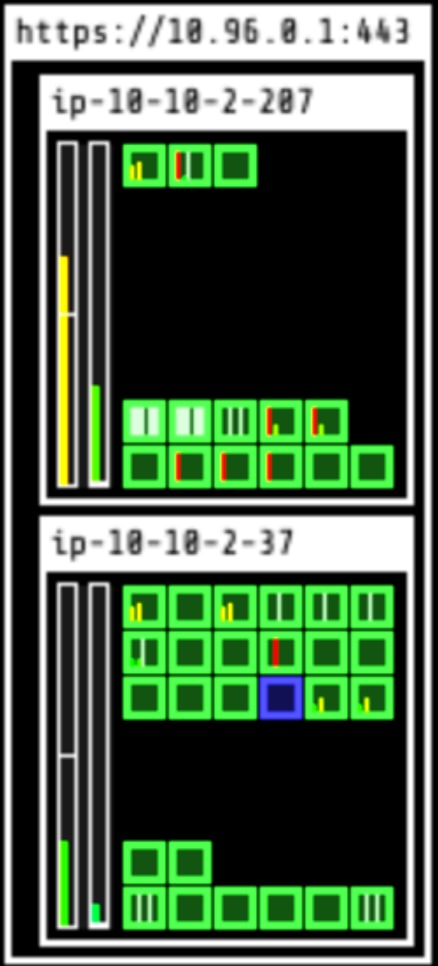
Step 2: Deploy an application on the cluster
Now, let’s deploy our Kubernetes application! This is what is happening now in my setup:

Our worker node is now full with CPU of more than 89%. We also have a lot of pods that are unscheduled (marked in yellow) - they simply have no room to run on our existing node.
Step 3: Let the autoscaling begin
CAST AI autoscales our setup by adding nodes to the application. As you can see, it added two additional VMs on Google Cloud: e2-standard-4 with 4 CPUs/16 GB and e2-standard-2 with 2 CPUs/8 GB.

Let’s take a look at our setup now. Do you see how optimized our CPU is on the first two worker node machines (the VM on top is the master node).

Why did the solution select two instances on Google and not on AWS? Because they were the most cost-effective at this time.
Let’s confirm this. Here are the prices of Google and Amazon.
Cost savings
On Google Cloud, the e2-standard-4 costs $0.134012 per hour:

And here’s an equivalent on AWS. We can see that every single 4 CPUs/16 GB are more expensive, even the t4g instance equipped with the Arm processor. Note: We didn’t consider this since we were looking at x86 CPUs.

On Google Cloud, the e2-standard-2 is $0.067006 per hour:

The AWS equivalent costs $0.0832 per hour (excluding the Arm processor-based instances):

As you can see, CAST AI made the right decision. It intelligently selected the most cost-effective additional instances choosing Google Cloud instead of sticking to AWS.
Step 4: Testing the pod autoscaler further
Let’s simulate a pod autoscaler by adding more replicas to one pod. We’re going from 5 replicas to 50:
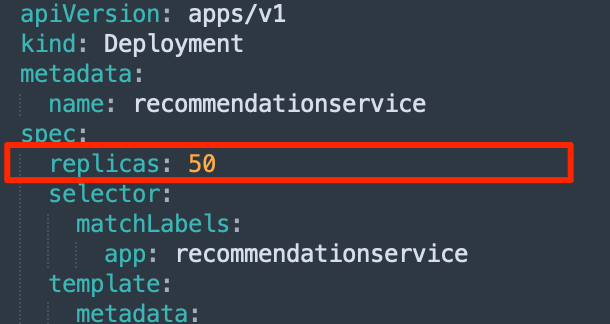
As expected, some pods filled up the spot instance and the rest became unscheduled. This triggered an autoscaling event and after a minute, CAST AI added new nodes.

A few minutes later, the solution reshuffled all the nodes automatically. Since many of the new pods were friendly to spot instances, it decided to add one spot instance and was able to consolidate both the unscheduled pods and pods from the former e2-standard-2 into an all new spot n1-standard-4. This brought the total cost even lower than before scaling up the pods.
So this is the final look of the nodes for our cluster:


Cost savings
The e2-standard-2 (2 CPUs/8GB) on demand was replaced by a larger n1-standard-4 (4 CPUs/16GB) spot instance.
Google Cloud’s n1-standard-4 pricing 4 CPUs/16 GB is $0.04280 per hour:

The equivalent on AWS would be at $0.0687 per hour:

CAST AI decided to eliminate the expensive On Demand e2 instance, and consolidate its pods (and the new unscheduled pods) on a highly discounted spot instance (called Preemptible Instance on Google Cloud).

Top comments (0)