Camunda Cloud Architecture Blog Post Series — Part 3
Part one of this blog post series (Connecting The Workflow Engine With Your World) described that custom glue code is often used to invoke services (or to write customized logic). Service tasks within Camunda Cloud require you to set a task type and implement job workers who perform whatever needs to be performed. This post looks at how to write good job workers — and explains what “good” might mean in this context.
Therefore, this post will look into these topics:
- Organizing glue code and workers — aka how many task types should one worker handle?
- Thinking about idempotency and data minimization.
- Scaling workers with blocking or non-blocking (reactive) code with examples in Java, NodeJS, and C#.
You might also be interested in part 2 of this blog post series: Service Integration Patterns With BPMN And Camunda Cloud.
Naming conventions
Boring — I know — but let’s quickly start by mentioning that I use the term “worker” here in sync with theCamunda Cloud glossary:
- Worker : Synonym for “job worker”.
- Job Worker : Active software component that subscribes to Zeebe to execute available jobs (typically when a process instance reaches a service task).
Related terms:
- Bridge : Synonym for “connector”.
- Connector : A piece of software that connects Zeebe with some other system or infrastructure. Might be uni or bidirectional and possibly includes a job worker. The boundary between connector and job worker can be fuzzy, in general connectors connect to other active pieces of software. For example, a ‘DMN connector’ might connect Zeebe to a managed DMN Engine, a ‘DMN worker’ will use a DMN library to execute decisions.
- Glue Code : Any piece of programming code that is connected to the process model (e.g. the handler part of a job worker).
Organizing glue code and workers
Assume the following simple order fulfillment process:

As described in Service Integration Patterns With BPMN And Camunda Cloud this could mean that all service tasks invoice services either synchronously or asynchronously. Let’s quickly assume we need three synchronous REST calls to the responsible systems (payment, inventory, and shipping). As a quick reminder, Connecting The Workflow Engine With Your World described why custom glue code might work better than connectors for this case.
So should you create three different applications with a worker for one task type each, or would it be better to process all task types within one application?
As a rule of thumb, I recommend implementing all glue code in one application , which for me is the so-called process solution (as described in Practical Process Automation). This process solution might also include the BPMN process model itself, deployed during startup. Thus, you create a self-contained application that is easy to version, test, integrate and deploy.
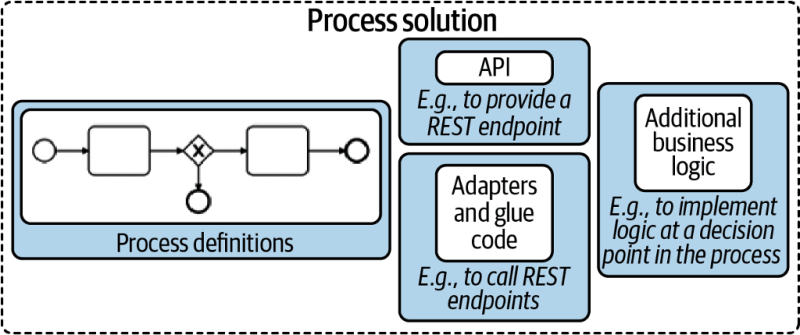
Thinking of Java, the three REST invocations might live in three classes within the same package (showing only two for brevity):
https://medium.com/media/abf117c5df049d89b724aab8704d606a/hrefhttps://medium.com/media/0a97464c85d86509b808e77b7f49e971/href
Of course, you can also pull the glue code for all task types into one class. Technically it does not make any difference and some people find that structure in their code easier. This is fine. If in doubt, my default is to create one class per task type.
There are exceptions when you might not want to have all glue code within one application:
- You need to specifically control the load for one task type, like scaling it out or throttling it. For example, if one service task is doing PDF generation, which is compute-intensive, you might need to scale it much more than all other glue code. On the other hand, it could also mean limiting the number of parallel generation jobs due to licensing limitations of your third-party PDF generation library.
- You want to write glue code in different programming languages, for example, because writing specific logic in a specific language is much easier (like using Python for certain AI calculations or Java for certain mainframe integrations).
Understanding workers conceptually
Now, let’s briefly understand how job execution with a job worker really works — so I can give you some more tips based on this knowledge.

Whenever a process instance arrives at a service task, a new job is created and pushed to an internal persistent queue within Camunda Cloud. A client application can subscribe to these jobs with the workflow engine by the task type name (which is comparable to a queue name).
If there is no worker subscribed when a job is created, the job is simply put in a queue. If multiple workers are subscribed, they are competing consumers, and jobs are distributed among them.
Whenever the worker has finished whatever it needs to do (like invoking the REST endpoint), it completes the job, which is another call to the workflow engine.
Thinking about idempotency of workers
Executing the glue code is external to the workflow engine and there is no technical transaction spanning both components. In other words: things can get out of sync if either the job handler or the workflow engine fails.
Camunda Cloud uses the “at-least-once” strategy for job handlers, which is a typical choice in distributed systems. This means that the process instance only advances in the happy case (the job was completed, the workflow engine received the complete job request and committed it). A typical failure case occurs when the worker who polled the job crashes and cannot complete the job anymore. In this case, the workflow engine gives the job to another worker after a configured timeout. This ensures that the job handler is executed at least once.
But this can mean that the handler is executed more than once! You need to consider this in your handler code, as the handler might be called more than one time. The technical term describing this is idempotency. I described typical strategies in 3 common pitfalls in microservice integration — and how to avoid them: One possibility is to ask the service provider if it has already seen the same request. A more common approach is to implement the service provider in a way that allows for duplicate calls. There are two easy ways of mastering this:
- Natural idempotency. Some methods can be executed as often as you want because they just flip some state. Example: confirmCustomer()
- Business idempotency. Sometimes you have business identifiers that allow you to detect duplicate calls (e.g. by keeping a database of records that you can check). Example: createCustomer(email)
If these approaches do not work, you will need to add your own idempotency handling by using unique IDs or hashes. For example, you can generate a unique identifier and add it to the call. This way a duplicate call can be easily spotted if you store that ID on the service provider side. If you leverage a workflow engine you probably can let it do the heavy lifting. Example: charge(transactionId, amount)
Whatever strategy you use, make sure that you’ve thought about idempotency consciously.
Data minimization in workers
Talking about idempotency, I also want to give you two rules of thumb about data in your workers.
First, if performance matters, minimize what data you read for your job. In your job client, you can define which process variables you will need in your worker, and only these will be read and transferred, saving resources on the broker as well as network bandwidth.
Second, minimize what data you write on job completion. You should explicitly not transmit the input variables of a job upon completion, which might happen easily if you simply “reuse” the map of variables you received as input for submitting the result.
Not transmitting all variables saves resources and bandwidth, but serves another purpose as well: upon job completion, these variables are written to the process and might overwrite existing variables. If you have parallel paths in your process (e.g. parallel gateway, multiple instance) this can lead to race conditions that you need to think about. The less data you write, the smaller the problem.
Scaling workers
Let’s talk about processing a lot of jobs.
Workers can control the number of jobs retrieved at once. In a busy system it makes sense to not only request one job, but probably 20 or even up to 50 jobs in one remote request to the workflow engine, and then start working on them locally. In a lesser utilized system long polling is used to avoid delays when a job comes in. Long polling means the client’s request to fetch jobs is blocked until a job is received (or some timeout hits). So the client does not constantly need to ask.
Anyway, you will have jobs in your local application that need to be processed. The worst-case in terms of scalability is that you process the jobs sequentially one after the other. While this sounds bad, it is valid for many use cases. Most projects I know do not need any parallel processing in the worker code as they simply do not care whether a job is executed a second earlier or later. Think of a business process that is executed only some hundred times per day and includes mostly human tasks — a sequential worker is totally sufficient (congratulations, this means you can safely skip this section of the blog post).
However, you might need to do better and process jobs in parallel and utilize the full power of your worker’s CPUs. In such a case, you should read on and understand the difference between writing blocking and non-blocking code.
Blocking (also known as synchronous) code and thread pools
With blocking code a thread needs to wait (is blocked) until something finishes before it can move on. In the above example, making a REST call requires the client to wait for IO — the response. The CPU cannot compute anything during this time period, however, the thread cannot do anything else.
Assume that your worker shall invoke 20 REST requests, each taking around 100ms, this will take 2s in total to process. Your throughput can’t go beyond 10 jobs per second with one thread.
A common approach to scaling throughput beyond this limit is to leverage a thread pool. This works as blocked threads are not actively consuming CPU cores, so you can run more threads than CPU cores — since they are only waiting for I/O most of the time. In the above example with 100ms latency of REST calls, having a thread pool of 10 threads increases throughput to 100 jobs/second.
The downside of using thread pools is that you need to have a good understanding of your code, thread pools in general, and the concrete libraries being used. Typically, I would not recommend configuring thread pools yourself. If you need to scale beyond the linear execution of jobs, leverage reactive programming.
Non-blocking (also known as reactive or asynchronous) code
Reactive programming uses a different approach to achieve parallel work: extract the waiting part from your code.
With a reactive HTTP client you will write code to issue the REST request, but then not block for the response. Instead, you define a callback as to what happens if the request returns. Most of you know this from JavaScript programming. Thus, the runtime can optimize the utilization of threads itself, without you the developer, even knowing.
In general, using reactive programming is favorable in most situations where parallel processing is important. However, I still see a lack of understanding and adoption in developer communities, which might hinder adoption in your environment.
Client library examples
Let’s go through a few code examples using Java, NodeJS, and C#, using the corresponding client libraries. All code is available on Github:
berndruecker/camunda-cloud-clients-parallel-job-execution
A walk through recording is available on YouTube:
https://medium.com/media/b3fd9ea5927f9b524ae56cbdd50d6cd1/href
Java
Using the Java Client you can write worker code like this:
https://medium.com/media/e5bebce34490e69c5b9513791963f438/href
This is abstracted by the Spring integration, which itself uses a normal worker from the Java client underneath. So your code might look more like this:
https://medium.com/media/e3421cf4f6e331befe345ea6184c60b3/href
In the background, a worker starts a polling component and a thread pool to handle the polled jobs. The default thread pool size is one. If you need more, you can enable a thread pool:
https://medium.com/media/32cb9bfa124a0fedd34679687da35614/href
Now, you can leverage blocking code for your REST call, like for example the RestTemplate inside Spring:
https://medium.com/media/38c70a7250b42ce37cfb2637af8f5cf0/href
Doing so limits the degree of parallelism to the number of threads you have configured. You can observe in the logs that jobs are executed sequentially when running with one thread (the code is available on GitHub):
10:57:00.258 [pool-4-thread-1] Invoke REST call…
10:57:00.258 [ault-executor-0] Activated 32 jobs for worker default and job type rest
10:57:00.398 [pool-4-thread-1] …finished. Complete Job…
10:57:00.446 [pool-4-thread-1] …completed (1). Current throughput (jobs/s ): 1
10:57:00.446 [pool-4-thread-1] Invoke REST call…
10:57:00.562 [pool-4-thread-1] …finished. Complete Job…
10:57:00.648 [pool-4-thread-1] …completed (2). Current throughput (jobs/s ): 2
10:57:00.648 [pool-4-thread-1] Invoke REST call…
10:57:00.764 [pool-4-thread-1] …finished. Complete Job…
10:57:00.805 [pool-4-thread-1] …completed (3). Current throughput (jobs/s ): 3
If you experience a large number of jobs, and these jobs are waiting for IO the whole time — as REST calls do — you should think about using reactive programming. For the REST call this means for example the Spring WebClient:
https://medium.com/media/92881891adce6e29adc674273ac16816/href
This code also uses the reactive approach to use the Zeebe API:
https://medium.com/media/55cdb0c37ed9d393923312af32105a59/href
With this reactive glue code, you don’t need to worry about thread pools in the workers anymore, as this is handled under the hood from the frameworks or the Java runtime. You can see in the logsthat many jobs are now executed in parallel — and even by the same thread in a loop within milliseconds.
10:54:07.105 [pool-4-thread-1] Invoke REST call…
[…] 30–40 times!
10:54:07.421 [pool-4-thread-1] Invoke REST call…
10:54:07.451 [ctor-http-nio-3] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-7] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-2] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-5] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-1] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-6] …finished. Complete Job…
10:54:07.451 [ctor-http-nio-4] …finished. Complete Job…
[…]
10:54:08.090 [pool-4-thread-1] Invoke REST call…
10:54:08.091 [pool-4-thread-1] Invoke REST call…
[…]
10:54:08.167 [ault-executor-2] …completed (56). Current throughput (jobs/s ): 56, Max: 56
10:54:08.167 [ault-executor-1] …completed (54). Current throughput (jobs/s ): 54, Max: 54
10:54:08.167 [ault-executor-0] …completed (55). Current throughput (jobs/s ): 55, Max: 55
These observations yield in the following recommendations:

NodeJs client
Using the NodeJS client you will write worker code like this, assuming that you use Axios to do rest calls (but of course any other library is fine as well):
https://medium.com/media/27b38cb3b83c01ad547d5b63685f7995/href
This is reactive code. And a really interesting observation is that reactive programming is so deep in the JavaScript language that it is impossible to write blocking code, even code that looks blocking is still executed in a non-blocking fashion.
NodeJs code scales pretty well and there is no specific thread pool defined or necessary. The Camunda Cloud NodeJS client library also uses reactive programming internally.
This makes the recommendation very straight-forward:

C
Using the C# client you can write worker code like this:
https://medium.com/media/7f0a15fa8dea6c91137720e55342fb6b/href
You can see that you can set a number of handler threads. Interestingly, this is a naming legacy. The C# client uses the Dataflow Task Parallel Library (TPL) to implement parallelism, so the thread count configures the degree of parallelism allowed to TPL in reality. Internally this is implemented as a mixture of event loop and threading, which is an implementation detail of TPL. This is a great foundation to scale the worker.
You need to provide a Handler. For this handler you have to make sure to write non-blocking code, the following example shows this for a REST call using the HttpClient library:
https://medium.com/media/a042a4c61ab01f8fc8d7e0fd8c98c844/href
The code is executed in parallel,as you can see in the logs. Interestingly, the following code runs even faster for me, but that’s a topic for another discussion:
https://medium.com/media/78ffb9f6002e65910674758e91d532f5/href
In contrast to NodeJS you can also write blocking code in C# if you want to (or more probable: it happens by accident):
https://medium.com/media/75a1c6170fccb98b88dd33c80648d167/href
The degree of parallelism is down to one again, according to the logs. So C# is comparable to Java, just that the typically used C# libraries are reactive by default, whereas Java still knows just too many blocking libraries. The recommendations for C#:

Conclusion
This blog covered some rules on how to write good workers:
- Write all glue code in one application, separating different classes or functions for the different task types.
- Think about idempotency and read or write as little data as possible from/to the process.
- Write non-blocking (reactive, async) code for your workers if you need to parallelize work. Use blocking code only for use cases where all work can be executed in a serialized manner. Don’t think about configuring thread pools yourself.
I hope you find this useful and I definitely look forward to any questions or discussions in our Camunda Cloud forum.
Subscribe to me on Twitter to ensure you see part four of this series, which will discuss backpressure in the context of Camunda Cloud.
Bernd Ruecker is co-founder and chief technologist of Camunda as well as the author ofPractical Process Automation with O’Reilly. He likes speaking about himself in the third person. He is passionate about developer-friendly process automation technology. Connect viaLinkedIn or follow him onTwitter. As always, he loves getting your feedback. Comment below orsend him an email.





Top comments (0)