
Have you ever thought about how our computers allocate memory to processes so efficiently? Why is switching between tasks so seamless? This is how
How did it work before paging? 📃
Let's take a look at how the earliest computers handled loading programs into memory. The operating system used by IBM OS/360 called MFT used a very simple approach to allocating memory to programs:
Memory was divided into several fixed-size partitions.
Each partition may contain exactly one process
When a partition is free, a process is selected from the pending queue and loaded into the free partition.
When the process is terminated, the memory is deallocated and it becomes free again.
A more advanced version called the MVT was later introduced. It worked as follows:
The operating system kept a table indicating which parts of the memory are available and which are occupied.
Initially, the whole memory was empty and it was considered one large block of available memory, called a hole.
When a process needs memory, we search for a hole that is large enough to fit the process. When we find one such hole, we only allocated as much memory as the process requires. The leftover memory creates another hole to be used by some other process.
At any given time, the operating system has a list of available holes and their sizes and it also keeps track of the pending process queue. If there is no hole large enough to fit a process, the operating system will have to wait until memory is deallocated or skip that process and go down the queue.
There are three commonly used strategies to allocate memory in fixed partition systems. They are first-fit, best-fit and worst-fit. I won't cover them in this article but you can read more here
Why is this approach bad? 🦥
As more and more processes are added and removed from memory, the memory space gets broken into small pieces. The operating system is unable to allocate memory to a process even though the required memory is available because the memory spaces are not contiguous. This is called external fragmentation.
External fragmentation exists when there is enough total memory space to satisfy the requirements of a process but the available memory space is not contigious.
The other problem faced by the operating system is of internal fragmentation.
Suppose that a process requires 9998 bytes of memory and a hole of 10000 bytes is available.
If we allocate it the exact amount of memory it requires, it will leave a hole of 2 bytes.
The overhead to keep track of these 2 bytes is greater than the 2 bytes itself.
It makes more sense to allocate the process some extra memory. The extra memory which is unused by the process contributes to internal fragmentation - memory allocated to a partition but unused
Here comes paging 🚄
Paging is a memory management scheme that enables the memory addresses allocated to a process to be non-contiguous on the physical memory
The basic method for implementing paging is to maintain two address spaces - logical address space and physical address space.
The logical memory is divided into fixed-size blocks called pages. The physical memory is divided into blocks of the same size called frames.
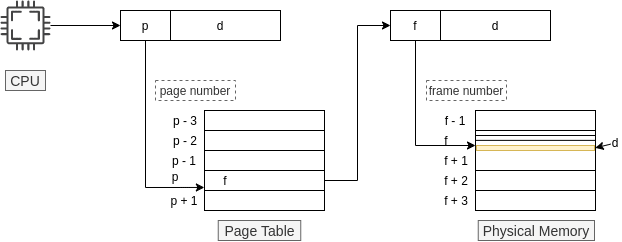
Every address generated by the CPU is divided into two parts: page number (p) and page offset (d).
The page number is used as an index in the page table. The page table contains the base address (p) of each page inside the physical memory. This base address (f) is combined with the page offset (d) to get the physical memory address that is sent to the memory unit.
Fragmentation problem
When using paging, we do not have the problem of external fragmentation. However, internal fragmentation might still be there. If the memory requirements of a process do not coincide with the page size, the last frame might not be completely used.
If process size is independent of the page size, internal fragmentation is expected to be a half-page per process which is not very huge if the page size is small.
Analysis of speed
The intermediate step introduced may produce extra latency for each operation. For this reason, a translation lookaside buffer is used which is a special cache table which stores the most frequently used addresses.
Connect with me 🤝
You can connect with me on Twitter and Linkedin
You can also follow me or subscribe to my newsletter to get updates on my latest articles
More stuff from me
Hi, let me know in the comments below if you want me to convert this article into a series and what other stuff you'd like to learn about





Top comments (0)