
What are they?
Well in the simplest terms they are a tree data structure, they have nodes and children like all other trees, but they are a very special kind of tree. One's first thought might be "Oh, B-Tree, yeah a binary tree right?" well, that's true and not so let's dive in to why.
As many kids as you want
To be exact, B-Trees are a generalization of a Binary Search Tree (BST) that is also self balancing. To start unpacking that internet definition, B-Trees have two distinct features that differentiate them from other trees. First their nodes can store more than one data point in them, and second they can have more than two children. That's basically what is meant by generalization of a BST in that when creating a B-Tree one can specify how many data points and children each node can have. What's interesting about this property is that each child node contains values that are in between two of the parent node's values. Since a picture is worth a thousand words, here's one to go along with this definition.
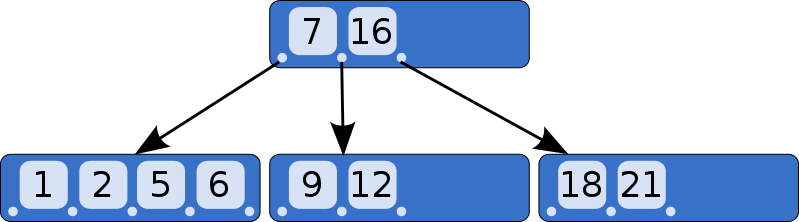
In the displayed example the values stored in the left most child node are all less than the seven in the parent node. So far this is similar to a binary tree, a part from the number of values in the child node. Now the middle child node contains all the values in between the seven and sixteen stored in the parent node and the right child contains the values greater than sixteen. This added level of separation and organization is the key feature of B-Trees and what differentiates them from other trees.
Now looking at that example, one might think "hmm it seems like that left child is completely full, so if I add a value less than seven I would add another child to that child right?" one would be completely correct in that observation if it weren't for the next coolest feature of B-Trees.
Self Balancing
Although not unique to B-Trees, self balancing is an integral part to making B-Trees work and not just be a special kind of of tree with multiple data points per node. Remember that thought one had last paragraph? Well the self balancing aspect of the B-Tree would resolve it so that the tree would not end up with a new child node of a child node unless absolutely necessary. If one were to add a value less than seven in our handy dandy example, the value would be passed down to the left child node, which at that point would realize that it's holding too many values. The midpoint of that child would then be promoted up to the parent node and the child would be divided into two around it. Lets add let's say zero and see how our tree gets updated.

Our two got promoted! Wonderful, that two has been working really hard and deserved it. Notice how the zero and one were placed in as the two's left child and the five and six as it's right child. This is how the self balancing in B-Trees differs slightly from other methods. This self balancing is what allows B-Trees to stay organized and be as efficient as possible.
Ok, now why should I care?
To spice up our B-Tree information lets add some technical jargon. The most important probably is that a B-Tree has a time complexity that is always O(log(n)). In it's search, insert and deletion, it will always be O(log(n)). Have I stressed that enough? O(log(n)). That's pretty good if you ask me. To give an example of this, if we set up our B-Tree to have 1000 children per node (big data) when we go down into a child node we are effectively narrowing down our search to ignore 999 thousandths of our data. Let me tell you that adds up. This makes the B-Tree perfect for dealing with data that is too large to fit on our main memory and for large storage systems, and as such it is commonly used in databases.
Final little tidbit
To end our little adventure with B-Trees I will show you this little toy to play with if you like watching things fall neatly into place, enjoy :) https://www.cs.usfca.edu/~galles/visualization/BTree.html

Top comments (0)