Disclaimer: this is an article of a project that uses the Google Language Sentiment Analysis API, it doesn't train any machine learning model.
Introduction
As a side project, I decided to develop a project to do sentiment analysis of headlines of some of the most important Brazilian news agencies. On the one hand I would like to test Google's API and on the other hand I would like to check if I could see significant differences on sentiments of the headlines of each news agency.
Architecture
The decisions on the architecture of this project were taken based on two decision criteria:
- Lowest Prices
- Less work
Database
For a database I decided to use Google's Firestore (non relational database) - no special reason for that other than "I'm already using GCP (Google Cloud Platform) for the sentiment analysis".
The database has three collections: websites, keywords and sentiments.
The documents in the collections have the following fields:
-
websites
- name: the website's name
- regex: regex used for scraping the website's headlines
- url: the websites's url
-
keywords (that we want to scrape):
- value: the string that we are looking for on the news agencies websites
-
sentiments:
- headline: the original headline analyzed
- headlineEnglish: headline translated to English (we'll talk about that later)
- isOnline: boolean that indicates if the headline is still being displayed on the website
- keywords: array with the keywords found in the headine
- onlineStartDate: timestamp of the first time the headline has been seen on the website
- onlineEndDate: timestamp of the last time the headline has been seen on the website
- onlineTotalTimeMS: the difference between the end and start dates (in milliseconds)
- sentimentScore: score of the sentiment analyzed (-1 to -0.25 means a negative sentiment, -0.25 to 0.25 a neutral sentiment and 0.25 to 1 a positive sentiment)
- sentimentMagnitude: the magnitude of the sentiment analyzed
- website: the website's name (from where the headline has been scraped)
Node.js Job
The responsible for actually doing all the work is a Node.js script (https://github.com/Brudhu/politicians_analysis). The script does the following:
- Get all the info it needs (like websites info, keywords etc.) from Firestore
- Scrape the websites to get the headlines (using puppeteer and the regex stored on Firestore)
- Pick headlines that have at least one of the keywords
- Check which of the scraped headlines have not been analyzed yet
- Translate headlines to English (using an API from Azure) - there we go: the reason for that is that in a quick test of the sentiment analysis API I realized it works a lot better with English sentences than Portuguese sentiments
- Analyze the sentiment of the headline translated to English (GCP Language API)
- Insert new sentiments in the "sentiments" collection
- Update sentiments that are not online anymore
I decided to run this job periodically every 30 minutes (not faster because I don't want to spend to much on Cloud resources).
I had two options to host the job: GCP (again) and Heroku - I know there are thousands of options but these are the ones I've had more experience
with. I decided to go with Heroku and Heroku Scheduler Addon (the scheduler is the responsible for running the script periodically). It's free for now.
Pricing
While the job on Heroku is free, the project on GCP is costing me 0.01 BRL per day.
First Results
To get the data from Firestore and analyze it, I wrote a Python script (will release it later).
For the first tests I set up two news agencies:
The keywords are:
- Bolsonaro (Brazilian president)
- Moro (Former Brazilian minister of justice - removed from the ministry a in April)
- Lula (Former Brazilian president)
- Dória (Governor of São Paulo state in Brazil)
In less than 14 days I got 571 headlines analyzed: 366 from UOL (the first one I started collecting data from) and 205 from G1.
The only keyword that has enough data for some analysis is "Bolsonaro", which makes sense since he is the current president.
Top Positive and Negative Sentiment Headlines
Most positive sentiment headline on UOL (Portuguese and the translated version in English):
Opinião: Com a PF, Bolsonaro cumpre a profecia de Jucá
Opinion: With PF, Bolsonaro fulfills the prophecy of Jucá
Most positive sentiment headline on G1:
Bolsonaro amplia lista de atividades consideradas essenciais na pandemia
Bolsonaro expands list of activities considered essential in the pandemic
Most negative sentiment headline on UOL:
Bolsonaro culpa governadores: 'Essa conta não é minha'
Bolsonaro blames governors: 'This account is not mine'
In this case we can see an error on the translation. I would say the best translation would be "Bolsonaro blames governors: 'This bill is not mine'"
Most negative sentiment headline on G1:
Procuradora diz que Bolsonaro violou a Constituição ao determinar revogação de portarias sobre armas
Prosecutor says Bolsonaro violated the Constitution by determining repeal of ordinances on weapons
Word Clouds
- The word clouds are displaying only words with 3 or more occurrences. The only keyword analyzed so far is "Bolsonaro".
The word cloud of every single headline analyzed is the following (it's in Portuguese, don't kill me):
Word cloud of positive sentiments:
Word cloud of negative sentiments:

Word cloud of neutral sentiments:

Word cloud of positive sentiments on UOL:

Word cloud of negative sentiments on UOL:

Word cloud of neutral sentiments on UOL:

Word cloud of positive sentiments on G1:

Word cloud of negative sentiments on G1:

Word cloud of neutral sentiments on G1:

Plots
Now that we have an idea of what the word clouds look like for many conditions, let's take a look on some plots. The first one is a box plot of the sentiments grouped by website:
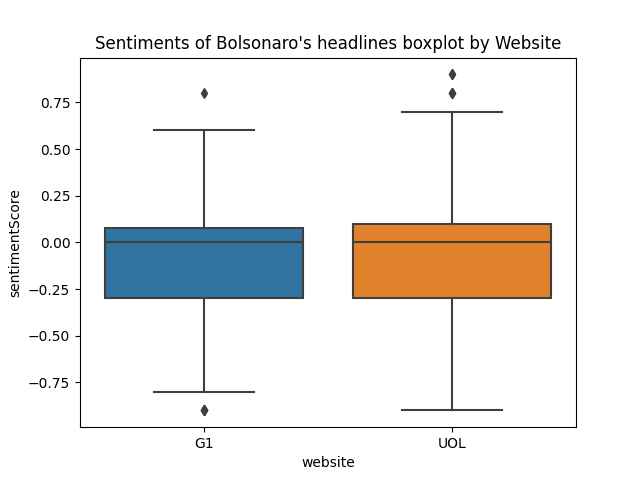
They look very similar: both are largely concentrated around the neutral area and both medians are pretty close - around 0 a little shifted to negative sentiments, but they are not exactly the same. UOL's box plot's minimum and maximum tails are longer then the ones from G1. Let's take a closer look.
Percentages
-
Total:
- Negative: 26.8%
- Neutral: 57.4%
- Positive: 15.8%
-
UOL:
- Negative: 25.3%
- Neutral: 58.6%
- Positive: 16.1%
-
G1:
- Negative: 29.9%
- Neutral: 55.2%
- Positive: 14.9%
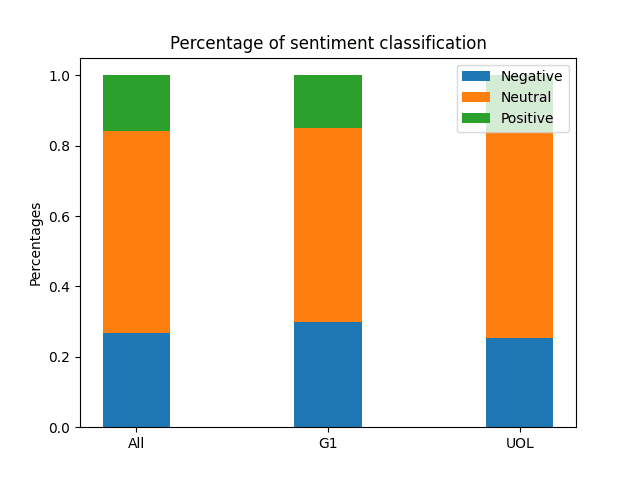
While they are still similar, we can see that G1 has more negative sentiment headlines than UOL, while UOL has more neutral and positive sentiment headlines.
Histograms
The histogram with all the sentiments for the "Bolsonaro" keyword is the following:
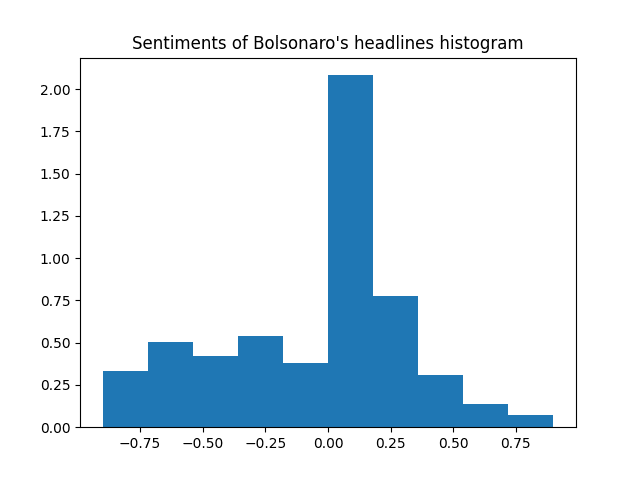
In the histogram we can confirm what we saw before: we have more negative than positive sentiments, but neutral sentiments are way more common.
Now let's break the sentiments by website:
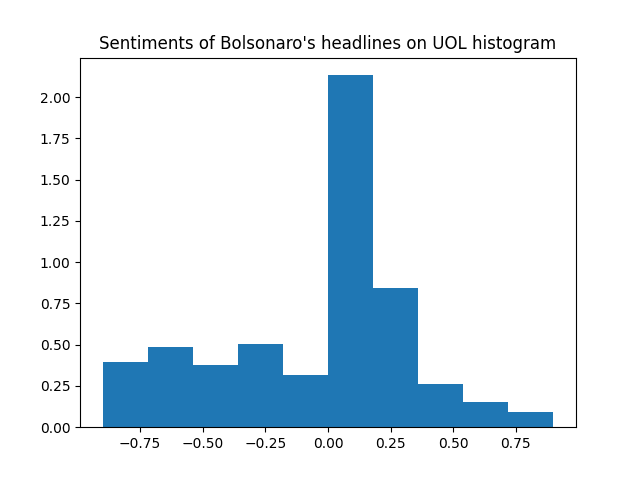
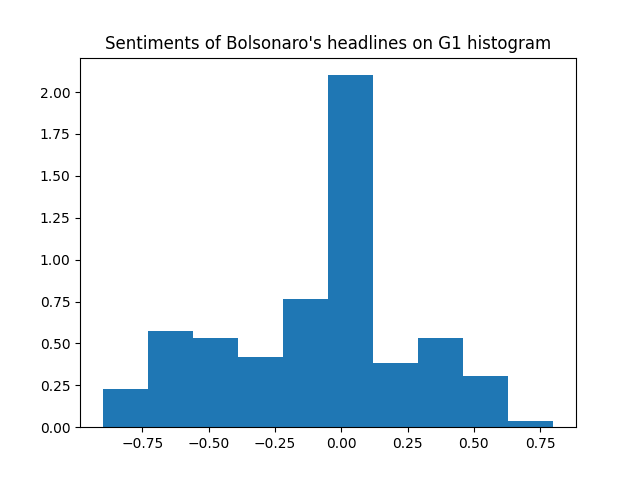
And the two previous histograms combined in the same plot:
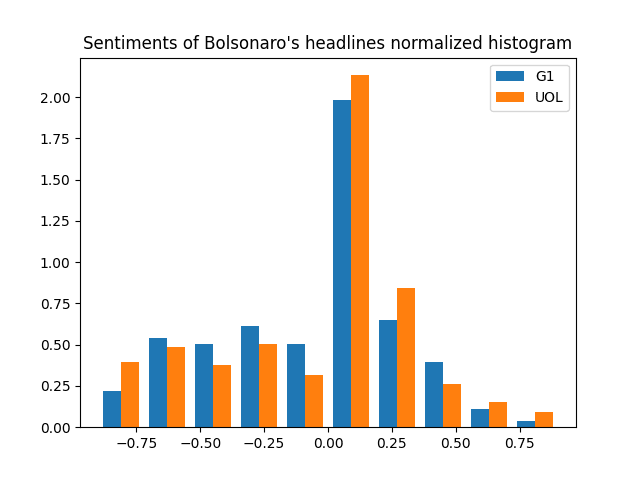
It looks like while G1 has proportionally more negative sentiments than UOL (like we saw on the percentages before), UOL tends to be a little more "extremist", with more very negative and very positive sentiment headlines.
Now let's break the histograms even more: by positive and negative sentiments for each website.
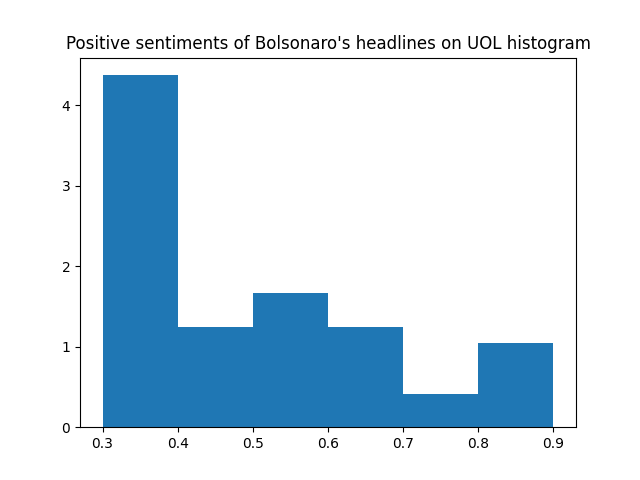
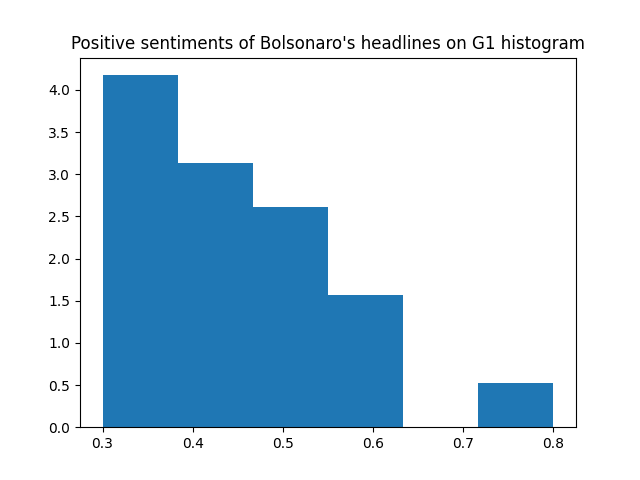
UOL has more headlines with sentiments >= 0.7 (very positive sentiments).
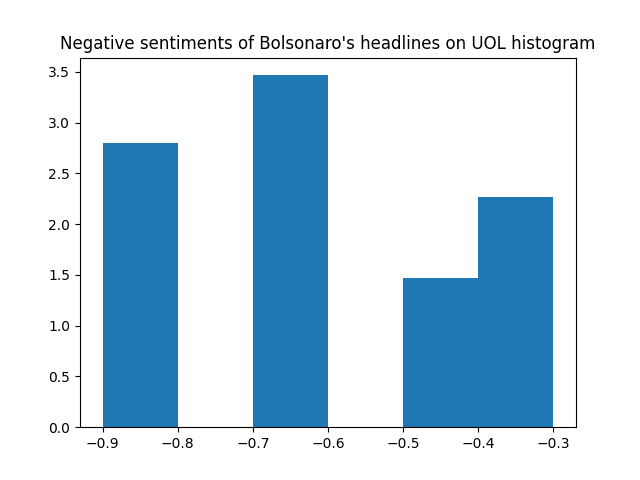
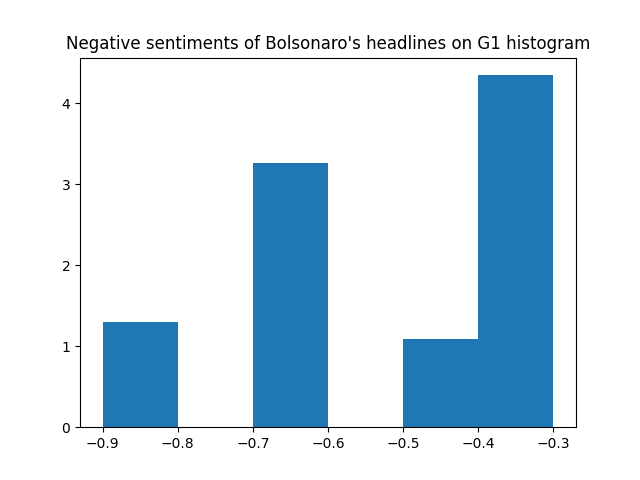
Even though we now that G1 has more headlines with negative sentiments, these histograms shows that UOL has more headlines with sentiments <= -0.6 (very negative sentiments).
Conclusion
While it was a lot fun to work on this project and having learned new stuff, I have to point out some of the flaws here:
- The translation from Portuguese to English (Azure) is very good, but not perfect for some cases
- Headlines related to Brazilian politics sometimes have a specific context that would be useful for the translation and Azure doesn't get it
- Some of the headlines were written by columnists and may be too informal to make sense after being translated (e.g. "Batata assou no fogo do parquinho dos Bolsonaro" which was translated to "Potato baked in the fire of bolsonaro playground" this sentence contains a Brazilian expression and means, in a very simplistic translation, something like "The Bolsonaros are in a bad situation")
- Getting way more negative than positive sentiments may not reflect a partial position of the news agencies. Many headlines are about problems related to Covid-19 and may be inherently negative (some are not).
Both agencies have similar results - not exactly the same, but very similar.
Next steps
Recently I added a new news agency (R7) and will try to update the data and analysis once I have more relevant data - maybe with new news agencies and new keywords.





Top comments (0)