
Learn how to use AWS serverless tools to synthesize text into human-like speech audio files, all written in TypeScript and deployed with AWS CDK.
In the world of cloud development, 'serverless' is a magical term. It not only simplifies application architecture (though this claim can be contentious), but it also significantly reduces operational costs. Today, I'm going to show you how to build a serverless Text-to-Speech pipeline using the AWS Cloud Development Kit (CDK), written in TypeScript. This solution is a practical example of how AWS CDK simplifies the development, deployment, and management of AWS resources in an efficient and "fashionable" way.
I'm thrilled to share with you how I've dabbled with the AWS CDK to build this serverless solution in just a few minutes. This project was an incredible opportunity to create a handy tool and gain understanding of CDK's workings.
Having had some experience with CloudFormation and Terraform, I found the shift to CDK intriguing. CDK allows you to define your cloud resources in the programming language you're comfortable with, making the entire development process more intuitive. Through this practical experience, we will explore the Amazon Polly service, which we'll dive into in the upcoming topics.
What's Covered?
- What is AWS CDK?
- What is Amazon Polly?
- Text-to-Speech Application
- Deploying with CDK
- Final Thoughts and Further Exploration
What is AWS CDK?
Before diving into the details of our application, let me introduce you to the AWS CDK. AWS CDK is an open-source software development framework for defining cloud infrastructure as code (IaC) and provisioning it through AWS CloudFormation. It allows you to define your cloud resources using familiar programming languages, providing you with the advantages of the robustness, flexibility, and power of those languages.
The key concepts in CDK are Stacks and Constructs.
Stacks
A stack in AWS CDK is a unit of deployment. Each stack that you define with AWS CDK is transpiled into a CloudFormation stack and deployed as an atomic unit.
Constructs
Constructs, on the other hand, are the basic building blocks of AWS CDK apps. A construct represents a "cloud component" and encapsulates everything AWS CloudFormation needs to create the component.
By combining these concepts, you can break down your serverless application into manageable units, simplifying the process of building complex cloud resources.
What is Amazon Polly?
Now, let's talk about Amazon Polly, which is at the heart of our application. Amazon Polly is a service that turns text into lifelike speech. It uses advanced deep learning technologies to synthesize speech that sounds like a human voice.
In our Text-to-Speech function, we leverage Amazon Polly to read the text files and convert them into audio.
Amazon Polly pricing
For Amazon Polly’s Standard voices, the free tier includes 5 million characters per month for speech (~119 hours). For Neural voices, the free tier includes 1 million characters per month for speech(~23 hours)
The price can variyng aroud number of characters synthesized and the Model you use, here is the table of pricing examples from official Amazon Polly Pricing page:
| Pricing Examples | Text Length | Speech Duration | Standard TTS Cost | Neural TTS Cost |
|---|---|---|---|---|
| 1,000 requests, 1,000 characters per request | 1 million characters | ~23 hours, 8 min | $4.00 | $16.00 |
| 10,000 requests, 100 characters per request | 1 million characters | ~23 hours, 8 min | $4.00 | $16.00 |
| 2016 Amazon Shareholders Letter | 1.3k characters, single page | ~1 min. 40 sec | $0.005 | $0.021 |
| Average email message | ~3.1k characters | ~4 min | $0.01 | $0.05 |
| Typical news article | ~6.5k characters, three pages | ~9 min | $0.03 | $0.10 |
| "A Christmas Carol" by Charles Dickens | ~165k characters, 64 pages | ~3 hours 50 min | $0.66 | $2.64 |
| Storytelling with highlighted text for children: - Length of text for the story: 10k characters - Need for Speech Marks to synchronize highlighted text |
10k characters of synthesized speech 10k characters of Speech Marks data |
~13 min | $0.08 | $0.32 |
Text to Speech pipeline
The interaction between the resources forms a serverless text-to-speech conversion pipeline. When a text file is added to the Text Bucket, it triggers a series of events that result in the creation of an audio file in the Audio Bucket and the updating of metadata in the DynamoDB table. Let's break it down:
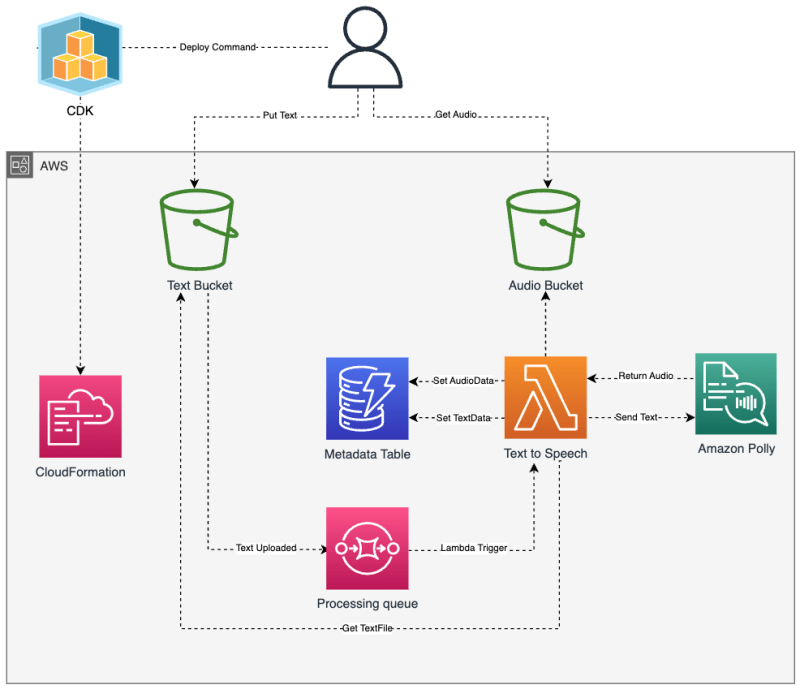
S3 Buckets
Text Bucket: This bucket is used to store the text files that will be converted to speech. When a new text file is added to this bucket, it triggers a message to the Processing Queue.
Audio Bucket: This bucket is used to store the audio files that are the result of the text-to-speech conversion.
Both buckets have versioning disabled, use S3 managed encryption, and block all public access.
Free tier eligible:
| Service | Limit | Description |
|---|---|---|
| Amazon S3 | 5 GB | Secure, durable, and scalable object storage infrastructure |
| Standard Storage | 5 GB | - |
| Get Requests | 20,000 | - |
| Put Requests | 2,000 | - |
DynamoDB Table
A DynamoDB table named MetadataTable is created to store metadata about the text and audio files as the status of conversion. It uses pay-per-request billing mode, which means you're only charged for the reads and writes that your application performs on the table.
Always free at this setup:
| Service | Limit |
|---|---|
| Storage | 25 GB per month |
| Provisioned write capacity units | 25 per month |
| Provisioned read capacity units | 25 per month |
SQS Queue
An SQS queue named ProcessingQueue is created to manage the processing of the text files. When a new text file is added to the Text Bucket, a message is sent to this queue. The visibility timeout for the queue is set to 300 seconds, meaning that a message received from this queue will be invisible to other receiving components for 300 seconds.
Free at this level:
You can get started with Amazon SQS for free. All customers can make 1 million Amazon SQS requests for free each month. Some applications might be able to operate within this Free Tier limit.
Lambda Functions
- Text to Speech Function: This function is triggered by messages in the SQS queue. It reads the text file from the Text Bucket, call the Amazon Polly SynthesizeSpeech API and saves the result audio mp3 to the audio bucket. It also updates the metadata in the DynamoDB table whith the conversion status and audio metadata. This function has read access to the Text Bucket, read and write access to the DynamoDB table, write access to the Audio Bucket, and permission to use Amazon Polly for speech synthesis.
Free tier eligible
1 million requests free
per month with the AWS Free Tier
To ensure we work within the limitations of the SynthesizeSpeech API, it is important to note the following restrictions:
- The input text should not exceed 3000 billed characters (6000 total characters). It is worth mentioning that SSML tags are not counted as billed characters.
- You can apply up to five lexicons to the input text.
- The output audio stream, or synthesis, is limited to a maximum of 10 minutes. If the text exceeds this limit, any remaining speech will be cut off.
To overcome these limitations, an alternative option is to utilize the SpeechSynthesisTask API, which is asynchronous. This API allows Polly to directly place the audio into the designated s3 bucket. For more detailed information, please refer to the official documentation.
Using AWS CDK, we can model these resources as stacks and constructs, allowing us to build, replicate, and manage the infrastructure efficiently.
Deploying with CDK
Before you can deploy this project, you need to have the AWS CDK installed. If you haven't installed it yet, you can do so by running npm install -g aws-cdk. You also need to have your AWS credentials set up. You can follow the AWS CDK Getting Started guide for more information.
Once you have the AWS CDK installed and your credentials set up, you can deploy the project by following these steps:
Clone the repository:
git clone git@github.com:brenonaraujo/aws-cdk-serverless-text-to-speech.gitNavigate to the project directory:
cd aws-cdk-serverless-text-to-speechInstall the dependencies:
npm installCompile the TypeScript code:
npm run buildDeploy the stack:
cdk deploy
Please note that the cdk deploy command will create real resources in your AWS account and may incur costs if you are out of the free tier period (12 months after account creation).
Once your are done, you can just destroy all the resources created:
cdk destroy
Testing our App
After the deployment process has finished, you can now go to your account and find the text bucket an put a text file in it. After a couple of seconds, you should see your audio file in the audio bucket.
Final Thoughts and Further Exploration
This journey with AWS CDK has been enlightening. It has enabled us to deconstruct complex applications into manageable components, thereby simplifying the creation, maintenance, and understanding of serverless solutions.
Amazon Polly has become another valuable asset. A few weeks ago, I was considering paying for a SaaS that offers exactly what we can achieve with Amazon Polly for 23 hours monthly without any upfront cost. It's almost like saying we can synthesize a book per month at a free tier (remember to respect copyright laws).
Thank you for accompanying me on this journey. Please feel free to share any feedback you may have.
Part II of this article includes a deep dive into the code.
Resources:
AWS CDK Documentation
AWS Lambda Documentation
Amazon S3 Documentation
Amazon DynamoDB Documentation
Amazon SQS Documentation
Amazon Polly Documentation





Top comments (0)