Directed Acyclic Graph (DAG) is a finite directed graph with no directed cycles. There are finitely many vertices and edges, where each edge is directed from one vertex to another. DAG contains a finite set of vertices and edges in sequence. Every edge in DAG is directed from top to bottom in the sequence.
This is why it's great for generating multistage scheduling layers that implement stage-based scheduling. As the number of layers and depth can be more than two but finite, it's better and optimized than the older Map and Reduce programs, which run in two stages only: Map and Reduce.
Working of DAG Scheduler
The interpreter is the first layer, using a Scala interpreter, Spark interprets the code with some modifications. Spark creates an operator graph when you enter your code in the Spark console. When we call an Action on Spark RDD at a high level, Spark submits the operator graph to the DAG scheduler.
Divide the operators into stages of the task in the DAG scheduler. A stage contains tasks based on the partition of the input data. The DAG scheduler pipelines operators together. For example, map operators schedule in a single stage. The stages pass on to the task scheduler. It launches tasks through cluster manager. The dependencies of stages are unknown to the task scheduler.
The workers execute the task on the slave. The following diagram briefly describes the steps of how DAG works in the Spark job execution:
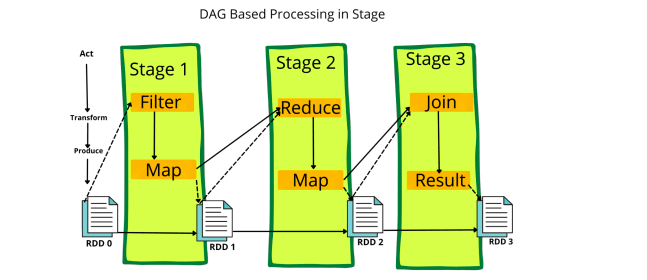
Driver program: The Apache Spark engine calls the main program of an application and creates Spark Context. A Spark Context consists of all the basic functionalities. RDD is created in the Spark Context.
Spark Driver: It contains various other components, such as DAG scheduler, task scheduler, backend scheduler, and block manager, which are responsible for translating the user-written code into jobs that are actually executed on the cluster.
Cluster manager: Cluster manager does the resource allocating work.
Hope this was helpful.

Top comments (0)