Blog written by: Chou-han Yang from Bloomreach, 2015
Briefly
Today we are excited to announce Briefly, a new open-source project designed to tackle the challenge of simultaneously handling the flow of Hadoop and non-Hadoop tasks. In short, Briefly is a Python-based, meta-programming job-flow control engine for big data processing pipelines. We called it Briefly because it provides us with a way to describe complex data processing flows in a very concise way.
At Bloomreach, we have hundreds of Hadoop clusters running with different applications at any given time. From parsing HTML pages and creating indexes to aggregating page visits, we all rely on Hadoop for our day to day work. The job sounds simple, but the challenge is to handle complex operational issues without compromising code quality, as well as the ability to control a group of Hadoop clusters to maximize efficiency.
Challenges:
- Data skew, or the high variance of data volume from different customers.
- Non-Hadoop tasks are mixed in with the Hadoop tasks and need to be completed before or after the Hadoop tasks.
- The fact that we run Elastic Map Reduce (EMR) with spot instances, which means clusters might be killed because of spot instance price spikes.
There are several different approaches to solve similar problems with pipeline abstraction, including cascading and Luigi, but they all solve our problems partially. They all provide some features, but none of them help in the case of multiple Hadoop clusters. That’s why we turned to Briefly to solve our large-scale pipeline processing problems.
The main idea behind Briefly, is to wrap all types of jobs into a concise Python function, so we only need to focus on the job flow logic instead of operational issues (such as fail/retry). For example, a typical Hadoop job in Briefly is wrapped like this:
@simple_hadoop_process
def preprocess(self):
self.config.defaults(
main_class = 'com.bloomreach.html.preprocess',
args = ['${input}', '${output}']
)
@simple_hadoop_process
def parse(self, params):
self.config.defaults(
main_class = 'com.bloomreach.html.parser',
args = ['${input}', '${output}', params]
)
And similarly, a Java process and a python process look like this:
@simple_java_process
def gen_index(self):
self.config.defaults(
classpath = ['.', 'some.other.classpath']
main_class = 'com.bloomreach.html.genIndex',
args = ['${input}', '${output}']
)
@simple_process
def gen_stats(self):
for line in self.read():
# Do something here to analyze each line
self.write('stats output')
And here’s what it looks like when we chain the jobs together to create dependencies:
objs = Pipeline("My first pipeline")
prop = objs.prop
parsed_html = source(raw_html) | preprocess() | parse(params)
index = parsed_html | gen_index()
stats = parsed_html | gen_stats()
targets = [stats, index]
objs.run(targets)
This script creates the workflow like this:
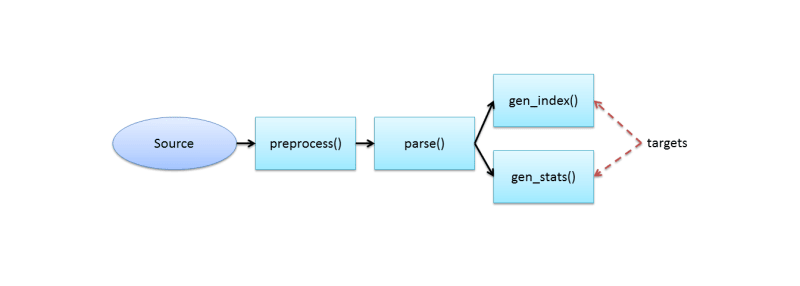
The pipeline can be executed locally (with Hadoop local mode), on Amazon EMR, or on Qubole simply by supplying different configurations. For example, running on Amazon EMR would require the following configuration:
# emr.conf
# Where to run your pipeline. It can be local, emr, or qubole
hadoop.runner = "emr"
# Max number of concurrent EMR clusters to be created
emr.max_cluster = 10
# Instance groups for each cluster
emr.instance_groups = [[1, "MASTER", "m2.2xlarge"], [9, "CORE", "m2.2xlarge"]]
# Name of your EMR cluster
emr.cluster_name = "my-emr-cluster"
# A unique name for the project for cost tracking purpose
emr.project_name = "my-emr-project"
# Where EMR is going to put yoru log
emr.log_uri = "s3://log-bucket/log-path/"
# EC2 key pairs if you want to login into your EMR cluster
emr.keyname = "ec2-keypair"
# Spot instance price upgrade strategy. The multipliers to the EC2 on-demand price you want
# to bid against the spot instances. 0 means use on-demand instances.
emr.price_upgrade_rate = [0.8, 1.5, 0]
Extra keys also need to be provided for specific platforms, such as Amazon EMR:
# your_pipeline.conf
ec2.key = "your_ec2_key"
ec2.secret = "your_ec2_secret"
And then your are good go. Run your Briefly pipeline with all your configuration files:
python your_pipeline.py -p your_pipeline.conf -p emr.conf -Dbuild_dir=build_dir_path
Now you can have several different configurations for running job locally, on Qubole, or with different cluster sizes. One thing we find useful is to subdivide a big cluster into smaller clusters which increases the survivability of the entire group of clusters, especially when running on spot instances.
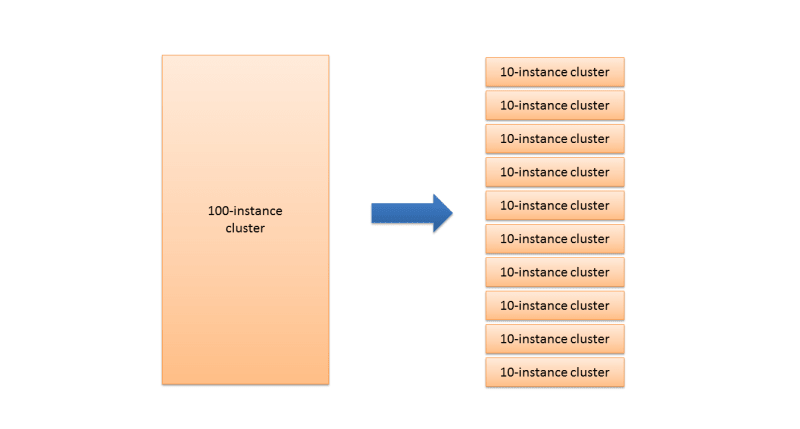
The number of clusters and the cluster size can be adjusted according to the jobs being executed. Many small clusters provides better throughput when running with a lot of small jobs. On the other hand, a large job may run longer on a few clusters while other clusters may be terminated after a predetermined idle time. The setting can be changed easily in the configuration for performance tests.
Other features Briefly
- Use of a Hartman pipeline to create job flow.
- Resource management for multiple Hadoop clusters (Amazon EMR, Qubole) for parallel execution, also allowing customized Hadoop clusters.
- Individual logs for each process to make debugging easier.
- Fully resumable pipeline with customizable execution check and error handling.
- Encapsulated local and remote filesystem (s3) for unified access.
- Automatic download of files from s3 for local processes and upload of files to s3 for remote processes with s4cmd.
- Automatic fail/retry logic for all failed processes.
- Automatic price upgrades for EMR clusters with spot instances.
- Timeout for Hadoop jobs to prevent long-running clusters.
Conclusion
We use Briefly to build and operate complex data processing pipelines across multiple mapreduce clusters. Briefly provides us with an ability to simplify the pipeline building and separate the operational logic from business logic, which makes each component reusable.
Please leave us feedback, file issues and submit pull requests if you find this useful. The code is available on GitHub at https://github.com/bloomreach/briefly.

Top comments (0)