
Originally published on Failure is Inevitable.
Are you going out for Black Friday?

Black Friday—we all know what it looks like. Hundreds of people swarming stores after Thanksgiving, jostling for the best deals. But in light of COVID-19, this arrangement could be dangerous.
Over the last few years, Black Friday has become a digital event, and this year should be even moreso. According to Forbes writer Richard Kestenbaum, “88% of global consumers told a Visa study they’re planning to buy gifts this holiday season.” Yet “only 20% of U.S. consumers plan to do their shopping exclusively in-store, while nearly a third plan to do most of their shopping online.”
This mostly-digital Black Friday event will mean retailers must be at the top of their game. With downtime costs per minute like $220,318.80 (Amazon) and $40,771.20 (Walmart), outages are expensive.
So how do we prepare when systems are stretched to their limits at this time of year? In this blog post, we’ll cover how to handle a Black Friday that’s unlike any other we’ve seen thus far. We’ll cover how SLO-based alerting, runbooks, and other practices to drive preparedness are crucial for holiday season success.
SLO-based alerting as a source of truth
According to a survey we conducted with almost 300 industry professionals, 60% of respondents stated that creating better monitoring and alerting processes was one of the main factors driving SLO adoption. That same survey also indicated that nearly 80% of organizations indicated that they are already using SLOs, or plan on doing so within the next 1-2 years. Stay tuned for the full report coming soon!
SLOs are an important tool for any organization adopting SRE. But they do more than help teams determine tradeoffs between innovation and reliability. They’re also key for setting SLO-based alerting, which is the most high-signal way to mobilize responder teams.
Improving your signal-to-noise ratio is especially important this year. As Forbes noted, “Walmart says it expects one-third of its customers to start holiday shopping by early November.” This means heightened traffic over a longer period of time, leading to burnout. It’s not sustainable to be working around the clock to resolve incidents. You need a smarter, higher context way to alert and notify teams. Alerting by error budget burn rate over a given period of time provides a better indicator of when your teams need to jump on an issue to protect customer experience.
By anchoring alerting to SLOs, you can cut down on your team’s alert fatigue. Alert fatigue is a frightening reality for many engineers. It occurs when too many alerts are firing, and only some are relevant. This noise leads engineers to ignore most or all alerts. Traditional alerting is one culprit behind alert fatigue. Alerting thresholds might need frequent calibration, but are rarely adjusted.
As Niall Murphy writes in chapter 8 of Implementing Service Level Objectives, “The simplest way to understand this is to think about a small but consistently growing online business. If we say your business grows 4–10% a quarter — a figure far from unknown for successful operations — then in under a year it will have gone from 100% of what it’s currently doing to anywhere between 116% and 146%, as Figure 8-1 illustrates.”
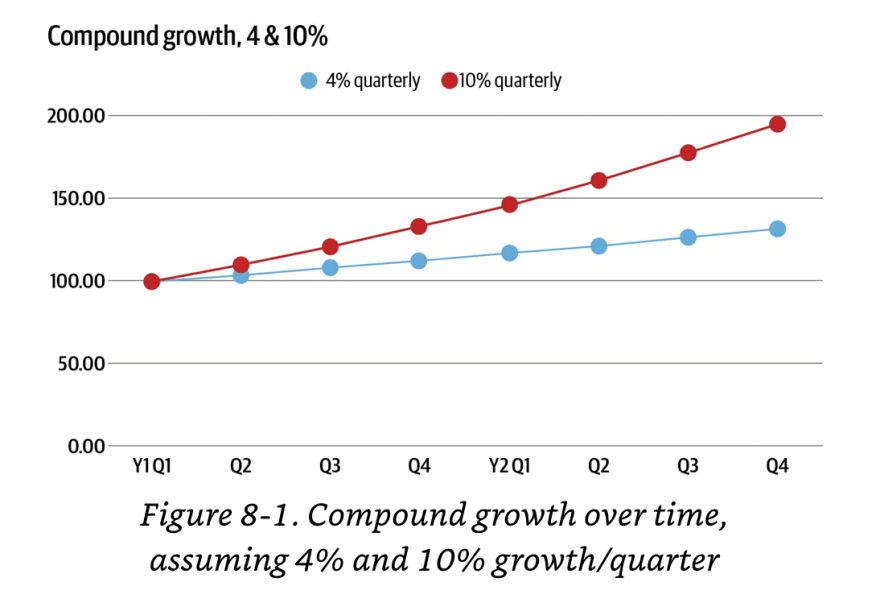
“As an example, let’s say in January you are doing 100 qps, and you picked 90 qps as a significant threshold. In late December, given a 4% quarterly growth rate, you are now doing 116 qps, as illustrated in Figure 8-1. The problem is, your absolute threshold is still stuck at 90 qps!”
Imagine that, rather than quarterly growth, we were looking at a significant increase in traffic over a short period of time. Your system is set to alert you when you hit 90 qps (queries per second). If on Black Friday you find yourself doing 120 qps, your alerting will be both noisy and useless. Even if your system is working fine, you’ll be bombarded.
SLOs offer a different way, which puts alerting in context of users’ actual experience. With SLOs, you’ll only receive alerts when you need to intervene. By setting an SLO and alerting on the burn rate of the corresponding error budget, you have a better view of your service’s performance, relative to what is acceptable to users. For example, your traditional alerting notifies someone when the system is handling more than 90 qps. But you’re handling 120 qps fine for the time being. You don’t need that alert.
Additionally, rather than monitoring qps, a better, more customer-centric metric to monitor may be something like latency or availability. Perhaps you know that when qps exceeds 90, your latency suffers. But what level of latency will your customers tolerate?
If your latency goes from 2.5 seconds to 3 seconds, will you customers care? Your SLO could state that any requests that take more than 4 seconds count as “bad” requests. This means that as long as your pages are loading within 4 seconds most of the time, you don’t need to receive alerts or set monitoring for qps.
Have your runbooks ready, and tie them to SLOs
According to a study conducted by The Harris Poll on behalf of Google, “Nearly nine in ten respondents (86%) said their company has a clear system that maps each process or system with its potential to degrade website performance.” Yet, “Only half (52%) of respondents said they were very confident in their company’s overall peak readiness. Less than half said they were very confident in their website speed (42%) and scalability (45%) going into Black Friday and Cyber Monday.”

So how do teams better prepare for the inevitable failure? Runbooks are excellent tools for teams looking to codify incident response procedures. They also decrease tribal knowledge, or knowledge that lives undocumented within the minds of engineers. These lists of steps and checks provide valuable information for incident responders.
Runbooks should contain:
- A map of your system architecture: with an increase of microservices and dependencies within your systems, it can be difficult to see how layers of your system connect. A map of your system architecture can help engineers from changing something that further exacerbates system issues. It can also be beneficial for visualizing problems and deducing where contributing factors might lurk.
- Service owners and contact information/protocols: when an incident occurs and the on-call team begins triage, it’s important that they know who to escalate an incident to, and when. A good runbook should show the on-call person for each service, as well as how to reach them. It should also show what sort of severity that team responds to within a certain time range.
- Key procedures and checklist tasks: runbooks would be incomplete without a list of steps and checks to guide an engineer through the resolution process. These steps and checks are often created from experience. They serve as documentation for similar incidents and keep engineers from having to do rework.
SLOs can also trigger runbooks. If you’re burning error budget and an alert states that you’ll likely exceed it within the next week, your runbook will look different from an alert saying that you’ll exceed your error budget within the next hour. By having thorough and up-to-date runbooks, you can lessen the cognitive load engineers face when dealing with an incident.
Prepare for the long-haul with burnout mitigation
Incidents are sure to happen, no matter how well you prepare for Black Friday. And this year, we will see heightened levels of traffic for an extended period of time. With this comes the risk of engineer burnout. To curb this, keep in mind two things:
Burnout mitigation
Burnout happens. Those who maintain systems are under extreme pressure to keep things functioning.
Make sure you’re mitigating burnout by encouraging everyone on the team to take time away that they need. This means encouraging them to take vacation, even if it’s just a staycation. SLOs and error budgets can even help with this.
Alex Hidalgo sites vacation monitoring as one way to use error budgets in his book Implementing Service Level Objectives. “You could set an error budget for vacation days used over a time window to make sure you’re at least checking in on those who aren’t using their days on occasion. No one should ever be forced to take time off, but using some simple budgeting math to check in with those who haven’t is likely not a bad idea. Breaks from work are important.”
Beyond using error budgets to determine when team members are likely to need a break, it’s also important to check in. During 1-1’s, managers should try to address burnout levels. Consider team surveys as another option. Burnout, if unaddressed, can be as detrimental to teams as incidents.
On-call compassion
Being on call during this time can come with extra stress, as well. When organizations are dealing with an increase in incidents, on-call teams often take the brunt of the work. It’s important to address the levels of on-call stress your team is experiencing.
One way to do this is to look at qualitative data on-call data as well as quantitative. Furthermore, beyond giving engineers time to relax, be sure to give kudos to the on-call team. Celebrate the on-call team's successes, emphasizing the challenges team members had to face. On-call incidents can begin and end in a single night, leaving others unaware and the responders feeling unappreciated. Recognizing on-call efforts can help motivate engineers and reduce burnout.
Is your team prepared for Black Friday 2020?
This year’s Black Friday is longer and more ‘digital’ than ever, putting more demands on engineering teams to be more prepared than ever before. SLOs and other SRE best practices can help you manage alerts, prepare for incidents, and mitigate burnout during this time of year.
If you want to learn more about how teams are using SLOs and SRE best practices, stay tuned for the exclusive “SLO Maturity and SRE Adoption Report 2020.” Follow us on LinkedIn or Twitter to be the first to know when this report goes live.
And, if you need help preparing for Black Friday, it’s not too late. We’re offering a limited time offer with extended trials in November and December 2020, so that any team can start heightening their preparedness during this holiday season. Click here to schedule a demo with our team.




Top comments (0)