Originally published on Failure is Inevitable.
🎼 Frosty the SRE/ Was a jolly happy soul/ With his runbooks tight and automated/ and SLOs made out of gollldddddd! 🎼
It’s the most wonderful time of the year, and to celebrate, here’s your December issue of the SREview! This monthly zine features epic Tweets, content, and events happening in the SRE and resilience engineering community.

Tweets that have us twittering
 Lorin Hochstein E_TOO_MANY_FAILURE_MODES@lhochstein
Lorin Hochstein E_TOO_MANY_FAILURE_MODES@lhochstein Anything that’s really worth learning through reading a text will require going over the text multiple times. Whenever I think I’ve really gotten a complex idea on first read, on re-read I discover there’s a ton that I missed.04:44 AM - 17 Nov 2020
Anything that’s really worth learning through reading a text will require going over the text multiple times. Whenever I think I’ve really gotten a complex idea on first read, on re-read I discover there’s a ton that I missed.04:44 AM - 17 Nov 2020
0
28
 Miss Amy🐋@missamytobey"I fight for the users" is the most succinct way I know to describe what it means to be an SRE23:59 PM - 17 Nov 2020
Miss Amy🐋@missamytobey"I fight for the users" is the most succinct way I know to describe what it means to be an SRE23:59 PM - 17 Nov 2020
The problem with technical debt is that it becomes a catch all term for a variety of ills.
- poor architecture
- poor tool choices
- unreadable code
- code that is old and could be written much cleaner
Etc, etc.
Some of these things are a bigger lift than others. #devdiscuss02:14 AM - 18 Nov 2020

SREading
How Mercari Scales Vision, Culture, & Reliability: Mohan Bhatkar, Head of Engineering for the Customer Reliability Platform at Mercari, Inc. discusses scaling while avoiding silos and more.
Music in Resilience: Matt Davis, Sr. Infrastructure Engineer at Blameless, writes about how music, specifically improvisation, and incidents can be seen through a similar lens.
The Engineer's Guide to Preparing for Black Friday 2020: In this blog post, we’ll cover how to handle a Black Friday that’s unlike any other. Note: it might last well into December this year.
SLO — From Nothing to… Production: Ioannis Georgoulas writes on how he learned about SLOs and applied his learnings to his work at Paddle.
What Financial Crises can Teach us about SRE: We can draw parallels between managing financial crises and SRE as a crisis prevention and response solution.
Keeping Netflix Reliable Using Prioritized Load Shedding: Netflix’s Engineering team shares how viewers can continue watching their favorite shows while the infrastructure self-recovers from a system failure.
Give it a whirl
We are very excited to announce that teams now have a new tool in their tool belts with our latest launch! Blameless Runbook Documentation is now available for early access.
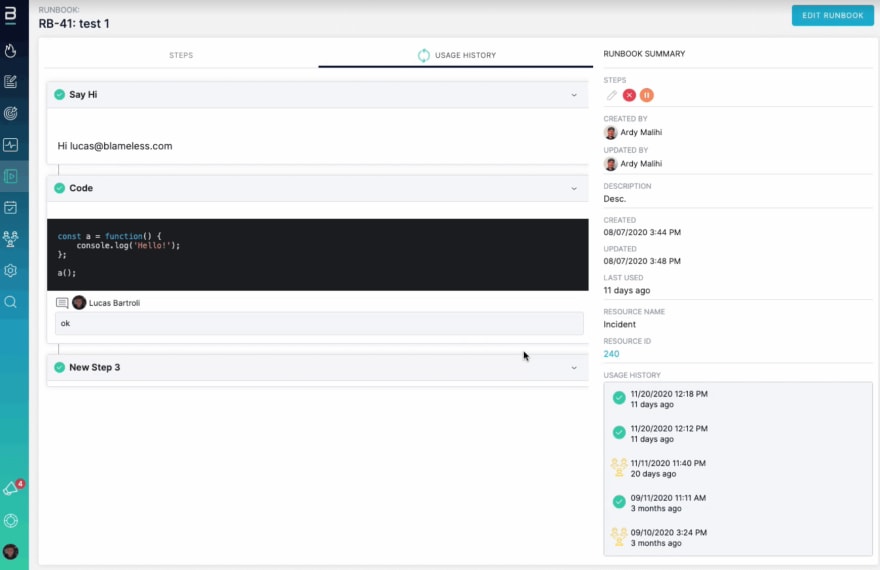
Runbooks are an industry best practice, empowering teams to codify the incident response process and drive process repeatability and consistency. These sets of instructions allow teams to resolve incidents faster with greater confidence and less toil.
Fill out this form to be one of the first to see Runbook Documentation in action.
Featured content
New eBook
Runbook for Among Us: Killing, Tasking, and Voting like a Pro: Up your Among Us game with this handy runbook.
Want to contribute?
If you’re looking to share your insights with the SRE and resilience engineering community, we’d love to partner with you on content. Fill out our form here and we’ll reach out!





Top comments (0)