This article was previously posted as part of the 2022 Java Advent calendar.
Christmas is coming, and Santa and the elves are working around the clock to build all toys. After a long day in the toy workshop, the elves want to spend their hard-earned NorthPoleCoins on jingle juice and sweets at the local pub. They always go in groups and often order collectively. They use a special application to keep track of payments so that every elf pays its fair share. We see the service that settles these payments below.

To preserve peace on the north pole, we want to add some tests to ensure that this service works as intended. One crucial property of the method above is that, at any point in time, the balances of all elves add up to zero. Otherwise, coins would be created or lost. A unit test for this method could look something like the one below.

First, the scenario is set up by initialising the objects with example values. Then, we invoke the method under test and write assertions to verify that the output is as expected. Of course, it doesn’t stop with this single test case. We generally write additional, similar tests to sufficiently cover all scenarios and edge cases. And when we see that all the test scenarios we came up with are passing, we can relievedly commit or deploy our code.

Downsides of example-based testing
If we take a step back, we see that many of these test cases are quite similar, except that each uses a slightly different example. There are a few downsides to this approach. First of all, developers need to spend more time developing and maintaining these test cases. This includes coming up with realistic examples, which requires a thorough understanding of the domain. New developers on the team might also have a hard time grasping the actual intent of the test. It takes time to see what angles are covered for each method and what is missing or redundant. And despite all this effort from the team, only a small portion of all possible examples are covered by the tests they wrote. Covering all combinations of inputs is just not feasible. And even worse, the scenarios covered are the same every run: essentially coupling between scenario and test suite.
When we implement our methods, we want the logic to be generic and not tied to specific cases. The code should have certain properties for all possible inputs. The tests we write for it are more the opposite: we write tests that are example-specific and not generic. The code and tests are designed on different levels of abstraction, where properties are more abstract than concrete examples.
Property-based testing to the rescue
But what if we could write tests like we write our code? Property-based testing (short: PBT) can help us out here. Instead of defining the concrete examples to test, you specify the domain (strings, positive integers, etc.) and let the framework generate many input values, including edge cases. Each test is executed multiple times with different possible inputs during a test run. Property-based testing allows us to write one test that tests all of the desired inputs, including typical edge cases, which allows for more efficient test writing and ensures that a test passes for all possible values within the domain.
Below we see how our test could look as a property-based test. The scenario function is replaced by Kotest’s checkAll, taking as its inputs a set of generators. The class containing all generators is called Arb, which is short for arbitrary. A predefined number of examples is generated for each test run, a thousand by default in Kotest. The rest of the test remains completely the same, except that we added some code to transform the generated values to the entities and values of our domain.

Our example-based tests previously all passed, which might lead us to believe that this property-based test will also be happy. Our test cases represented all possible paths, right? However, we are actually met with a failure this time. You might think that a property-based test is more difficult to debug because of its generated input values, but we did not talk about PBT’s superpower. Kotest not just mentions the failing example if the test fails, it starts ‘shrinking’ the input values. If the test fails with integer value 8 as input then this value is shrunk to value 7, and the test is retried. If the test failed when we tried to input a list of three strings integer then the list is shrunk to two strings. Shrinking continues until the test passes again, and the goal is to find the minimal reproducible example for which the test fails, which helps find the bug. Let’s have a look at the stack trace of our run.
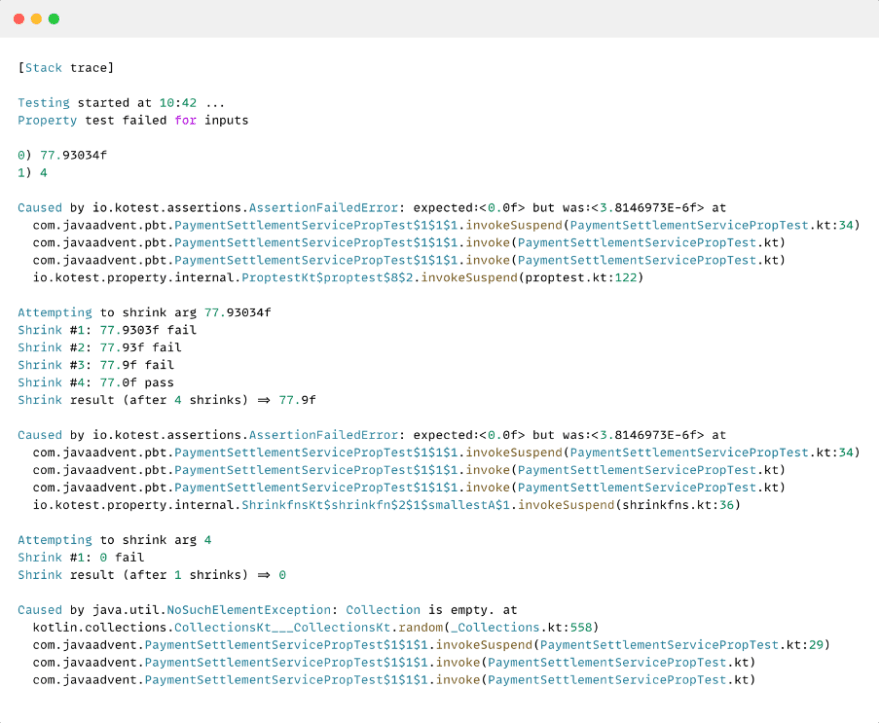
The test failed when we tried to divide (a rounded) 77.93 NorthPoleCoins over four elves, and Kotest started shrinking both inputs. Interestingly, both shrinks uncovered a different bug for us. Dividing the coins led to a rounding error, while an empty list caused an exception to be thrown. We might not have thought of it when we created our examples, but now we can adapt our code based on these results.
When we make ourselves as developers responsible for coming up with realistic examples, we risk such bugs slipping through the cracks. Property-based tests make sure that all scenarios can be verified.
Custom generators
The property-based test we saw above is less readable than we would like because of the logic we added to transform the values from the built-in Arb generators to be suitable for our test. Kotest allows us to define custom Arb’s through the arbitrary builder, and we can use Kotlin’s extension functions to use these custom generators in the same way as their built-in counterparts.

Where Kotest knows how to shrink built-in generators, the shrinking behaviour for custom generators can be very dependent on your domain. Therefore, the arbitrary builder allows us to provide a shrink function that returns a list of values we deem to be a shrink result of the current generated value. Let’s have a look at what this could look like:

We ended up with a more concise test than the example-based test that we started with, but it covered many more examples than before.

Conclusion
In this article, we’ve seen what property-based testing is and how it differs from the more common example-based testing. Where defining representative examples in example-based testing is the programmer’s responsibility, property-based testing leaves this to generators so that the tests do not become partly dependent on the chosen examples. Property-based testing allows us to generalize concrete examples to focus on the characteristics of the code that underlie these examples, resulting in a cleaner and more compact test suite that is easy to maintain and better exposes subtle bugs. In this way, we bring what we test closer to what we claim to test. However, it is also important to note that property-based testing is not intended to replace example-based unit tests completely. It’s an addition to our testing arsenal that allows us to cover every possible input value with a single test to reveal bugs we might not come up with ourselves.

Top comments (0)