
If you've ever been in the situation where you can't find the correct data from an API, perhaps you've thought about building your own web scraper. Ruby's Mechanize gem makes building a web scraper a quick and simple task.
Firstly, you'll want to install the Mechanize gem by running 'gem install Mechanize' with your console. Once this is done, simple create a new .rb file and start building that scraper!
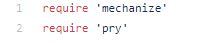
You'll want to start by requiring the gems that you're using. In this case, we require 'mechanize' and 'pry' for debugging.
Next we will declare our function and set a variable to a new instance of Mechanize, '@test ' in this case.

Now we want to choose the website that we're scraping. We can set the entirety of a web page to a variable so that we can pick and choose what elements to pluck off and use.

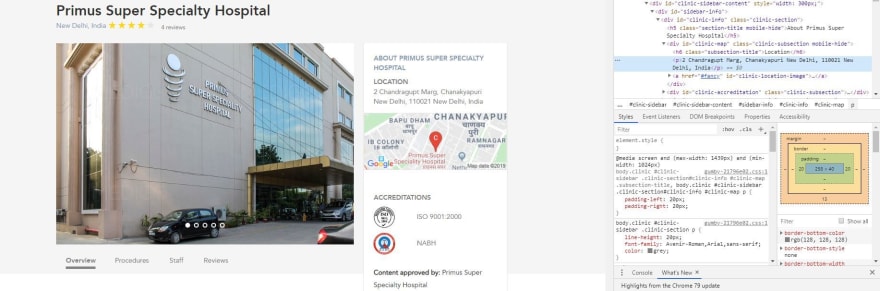
Using the page below as an example, let's target the address for this particular medical clinic in India. You can see the element containing the address selected in the developer tools on the right.
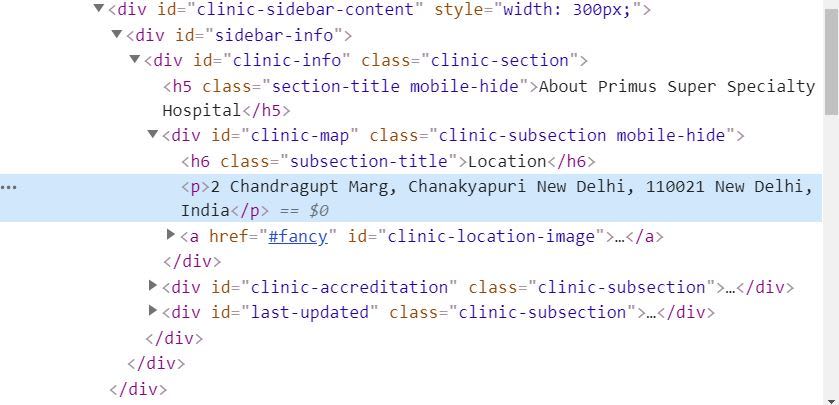
To pluck off the address that we want, first we have to target the div containing the address. We then target the p tag nested within that div, as that is where the text address actually lives. When we have the correct element targeted, we can simply strip the text off for later use.
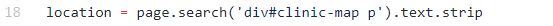
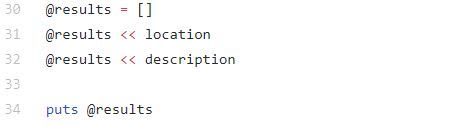
Once you have all of the data that you're looking for, you can output it to your console, send it back to your front end, or save it to your database.
Web scrapers are powerful tools to collect data from any source that you might fancy. Once I learned how to do so, I've used them in the majority of applications that I have created.





Top comments (0)