
Introduction:
DynamoDB, a fully managed NoSQL database service by Amazon Web Services (AWS), offers two options for retrieving data from tables: Scan and Query. While Scan may seem like a convenient choice, it is crucial to understand its limitations and cost implications. This article aims to shed light on the Scan and Query operations in DynamoDB, emphasizing the importance of avoiding Scan in a production environment due to its expense. Instead, we'll explore the benefits of utilizing the Query operation for efficient data retrieval.
Scan Operation:
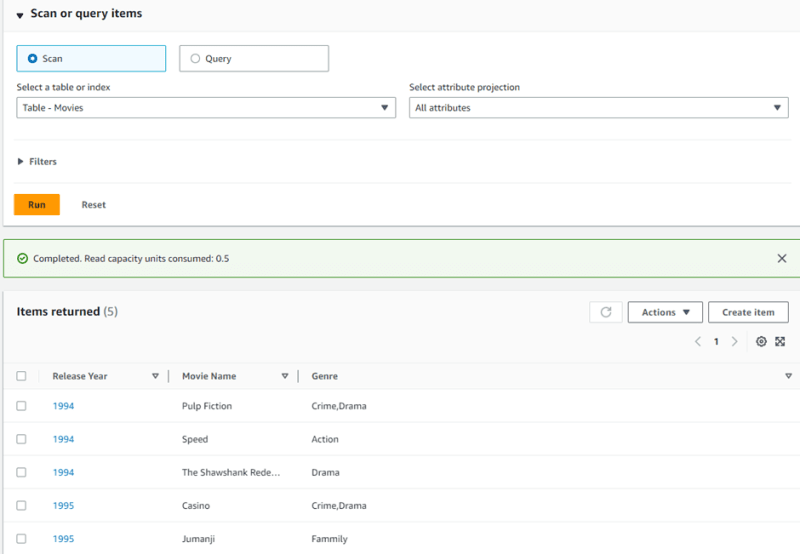
The Scan operation retrieves data from a DynamoDB table, but it should be used sparingly. When using Scan, the entire table is read before providing the desired result, making it an expensive operation. DynamoDB pricing is based on Read Capacity Units (RCU) and Write Capacity Units (WCU), and Scan consumes a considerable amount of RCU as it reads all the rows. Even though a filter expression can be added to the Scan command, it only applies after reading all the records, resulting in no cost difference. For larger tables, the RCU consumption and subsequent costs can be substantial. Hence, it is strongly advised to avoid using Scan in a production environment.
Query Operation:
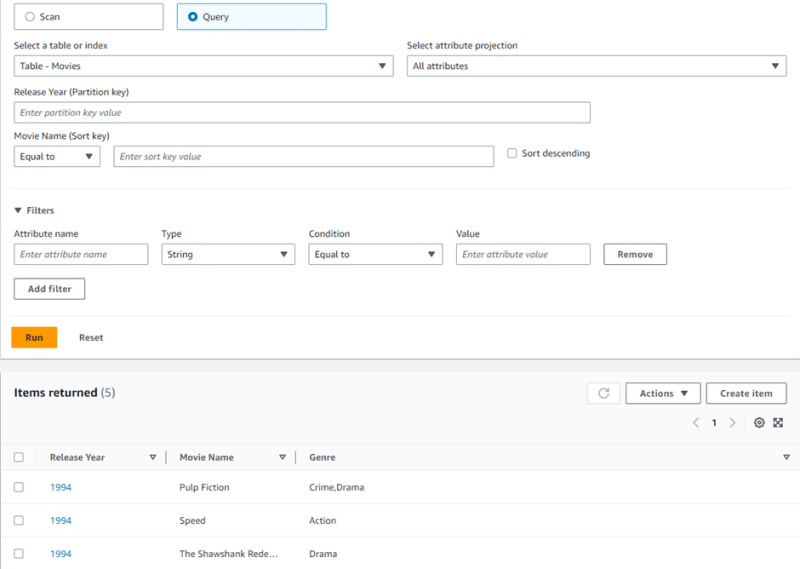
The Query operation is an efficient alternative for retrieving data from DynamoDB tables. It leverages the partition key, or a combination of partition key and sort key in the case of a composite key, to retrieve specific data. Like Scan, Query also supports filter expressions, but with a significant difference in cost calculation. Instead of applying RCU for the entire table, the RCU is applied only to the entries that correspond to the filter expression. This approach leads to substantial cost savings for organizations.
Utilizing Query:
Query is a suitable choice when the partition key is known. By specifying the partition key, we can retrieve the desired data efficiently. If a sort key is present in the table, it can further simplify the query by narrowing down the results based on the desired sort order. However, if the partition key is unknown, the Query command cannot be implemented effectively.
Conclusion:
Understanding the differences between the Scan and Query operations in DynamoDB is crucial for optimizing data retrieval and minimizing costs. While Scan provides a straightforward way to access data, its expense makes it unsuitable for production environments. On the other hand, Query offers a more efficient and cost-effective approach, utilizing partition keys and filter expressions to retrieve specific data. By leveraging Query wisely and avoiding Scan, organizations can maximize the benefits of DynamoDB while optimizing resource utilization and cost efficiency.

Top comments (0)