Exploring sample use cases around microservices orchestration and serverless function orchestration
Camunda Cloud was announced at the recent CamundaCon in Berlin. It provides Workflow as a Service based on the open source project Zeebe.io. In this post I want to quickly explain why I think cloud is here to stay, but foremost look into two sample use cases and how you can leverage Camunda Cloud to solve them: microservices orchestration and serverless function orchestration.
My take on WHY cloud
I don’t have to reiterate over all the existing writing why cloud will be inevitable. You could, for example, look into Simon Wardley’s work like Containers won the battle, but will lose the war to serverless, or tons of other resources (e.g. Sam Newmann: Confusion in the Land of the Serverless) telling you, that you need to get rid of “undifferentiated heavy lifting” to be able to focus on things that really differentiates your company — which is typically business logic.
I personally liked Forget monoliths vs. microservices. Cognitive load is what matters, and used that for my keynote at the above-mentioned CamundaCon. Let’s assume your team is capable of doing 10 units of work (whatever that unit is). This, then, is your maximum capacity:

In a typical environment, a lot of time will go into the undifferentiated heavy lifting to get your infrastructure right. Tasks like creating deployments, images or containers, environment specific configurations, deployment scripts, and so forth. Very often, these tasks take up to much more than 50% of the time, leaving the team little time to do business logic:

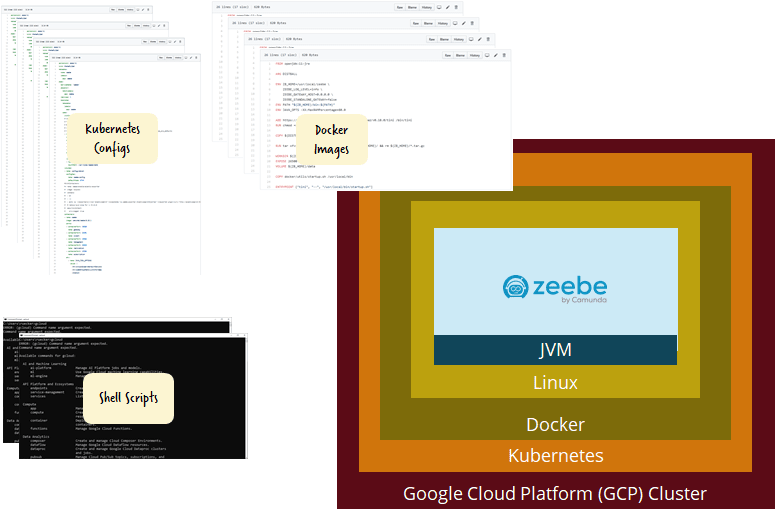
My personal aha moment occured when I was full of excitement around Kubernetes and wanted to leverage it to do a proper benchmark and load test on Zeebe. What followed was a painful process of creating the right Docker images, understanding Kubernetes specifics, Helm charts and some shell scripting which even led me to get to know the Linux subsystem of my Windows 10 machine (OK — I am actually grateful for that — but it took quite some time). OK, that all was long before there was zeebe-kubernetes or zeebe-helm, so it would be much easier today. But the core problem remains: too much undifferentiated heavy lifting and you are now in charge of components you don’t care about (like e.g. the operating system of your docker image).
This is exactly what we don’t want. What we do want is to concentrate on business logic most of the time:
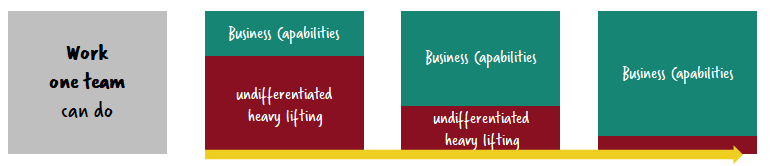
That’s why I want a picture vastly simpler than the one above. And here is one:

What is Camunda Cloud
Camunda Cloud is the umbrella for a couple of Camunda products provided as a Service, think of it as WaaS (Workflow as a Service —but be sure this will not be a term though ;-)). At CamundaCon, my favorite CTO Daniel Meyer sketched this vision:

As always, Camunda takes an incremental approach. In the first iteration, you get Zeebe as a workflow engine. More concretely, you can log into your cloud console and create a new Zeebe cluster:
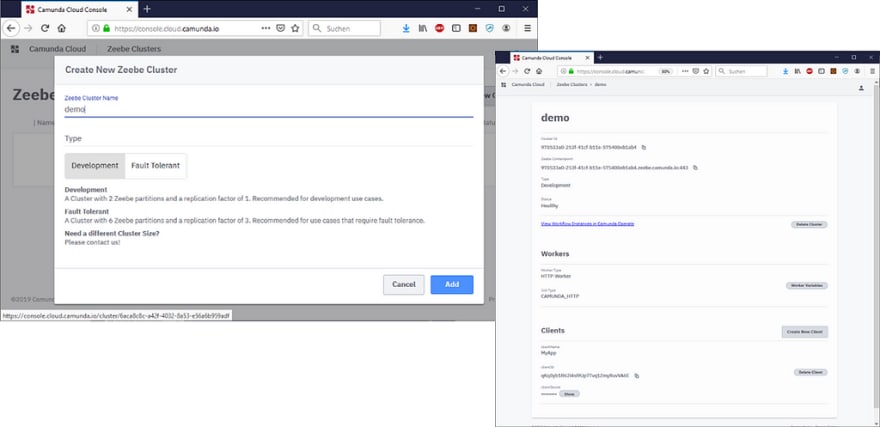
You can see the health of your cluster and all endpoint information in this console (including necessary security tokens) — allowing you to start developing right away.
In order to work with the workflow engine you can:
- build applications in the programming language of your choice (Zeebe provides language clients in e.g. Java, Node.js, C#, Goor Rust),
- use the command line tool to deploy workflows, start instances or create workers,
- use the existing HTTP worker to call REST APIs.
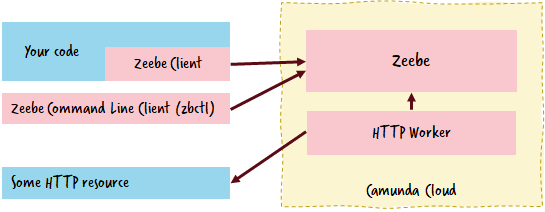
Of course, you can also leverage other components of the Zeebe ecosystem, for example the Kafka Connector.
Best follow this Getting Started Guide right away.
Use case: microservices orchestration
A common use-case for a workflow engine is orchestrating microservices to fulfill a business capability. I often use a well-known domain to visualize this: order fulfillment. You can imagine that various microservices are required to fulfill a customer order, connected via Zeebe:
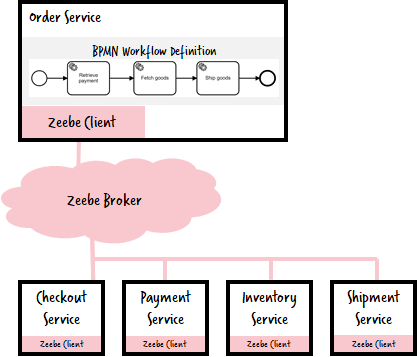
Of course, you are not forced to use Zeebe as the transport between your microservices — you might want to leverage your existing communication transports — like REST, Kafka or messaging. In this case, the workflow looks more or less the same, but only one microservice knows of Zeebe, and has some code to translate between workflow tasks and Kafka or the like:
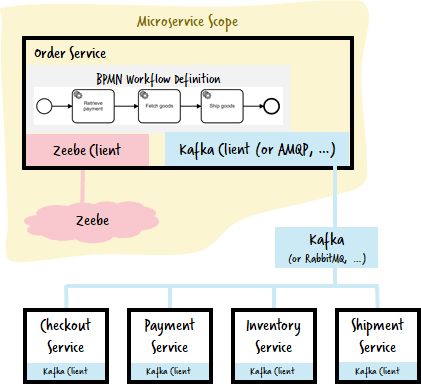
To play around with it, you can use this code on GitHub:
You just have to exchange the configuration of the Zeebe client, here is an example:
Here is a screen cast walking you through it:
Use case: serverless function orchestration
If you are serverless you might build a lot of functions. A key question will be how to coordinate functions that depend on each other. Let’s do THE classical example for the Saga Pattern here: You have one function to book a rental car, one function to book a hotel and one to book flights.
Now you want to provide a function to book whole trips, which need to use the other functions. Instead of hard coding the function calls in your trip booking function, you can leverage a workflow to do this. I talk about this at the upcoming AWS Community Summit in London.
There are two possibilities to connect Camunda Cloud to your favorite cloud providers functions like AWS Lambda, Azure Functions or GCP Functions. Let’s assume you do AWS for the moment to ease wording in this article. Then one possibility is to use the built-in HTTP connector of Camunda Cloud and call Lambdas via the API gateway. The workflow is like any other external client in this case.
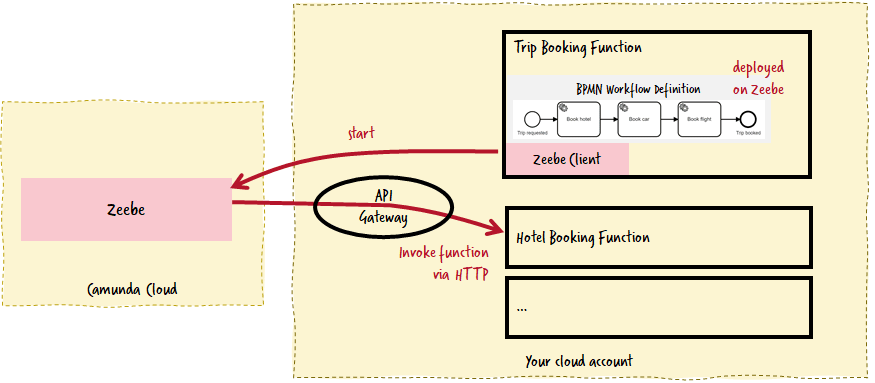
The advantage of this approach is the simplicity — and you are ready to go immediately. You don’t have to think about deploying or scaling any component yourself.
The disadvantage is that you have to expose all your lambdas via the API Gateway. As you can secure them easily (or probably use some VPN down the road), this should not be too big of a problem. Another disadvantage is that you have to pay for the API Gateway on top of your Lambda and live with smaller timeouts of your function calls (probably Kinesis would help?). Probably the biggest downside is that you are limited to the possibilities of the existing HTTP worker.
You can find some sample code on GitHub:
berndruecker/trip-booking-saga-serverless
You can also see this in action:
The second possibility is to provide a Zeebe Worker that can natively invoke your function. This worker is deployed into your own cloud account as a container and therefore is an internal component for you. No need to expose your functions to the outside world.
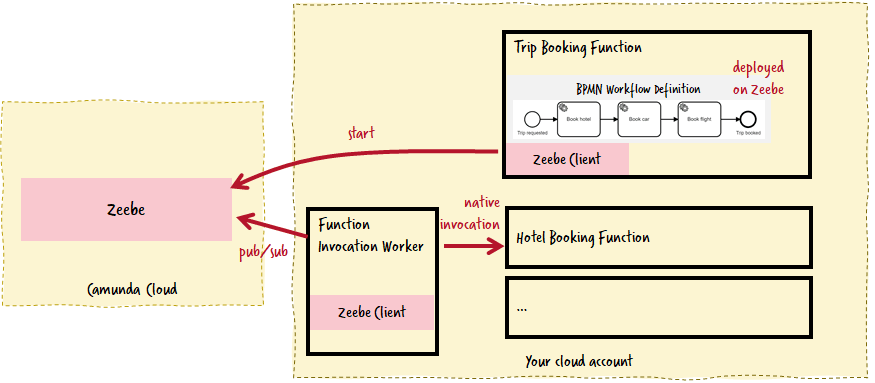
The advantage of this solution is that functions are called in a totally native way; and you have full control over the feature set of your worker. You could provide different workers for different cloud environments, without the workflow needing to know anything about it. The whole environment configuration for your cloud account is now moved to the worker, where you can easily control it. Additionally, you don’t have to pay for API Gateway.
The clear disadvantage is that you need another component, one that you have to maintain, deploy and scale by yourself. And, it needs to be always-on and therefore always costs, which means you need quite some throughput to reach the break-even compared to the invocation costs of the API Gateway. But if you are more deep into Kubernetes there are some tricks to scale your worker to zero to optimize costs (comparable to e.g. Osiris).
Summary
Using cloud services removes the burden of undifferentiated heavy lifting — freeing you to focus on business logic instead. This applies equally to workflow automation.
Today, I touched on how to leverage a managed Zeebe workflow engine in Camunda Cloud for both microservices orchestration and serverless function orchestration. We see both use cases happening already and anticipate a growing demand in the near future.
In short: I am excited! Request beta access now, get going and give us feedback!
Bernd Ruecker is co-founder and chief technologist of Camunda. He likes speaking about himself in the third-person. He is passionate about developer friendly workflow automation technology. Connect via LinkedIn or follow him on Twitter. As always, he loves getting your feedback. Comment below or send him an email.

Top comments (0)