
In real life, the raw data recieved is rarely in the format which we can take and use direclty for our machine learning models. Therefore, some preprocessing is necessary to bring the data to the right format, select informative data or reduce its dimension to be able to extract the most out of the data. In this post, we will talk about encoding to be able to use categorical data as features for our ML models, types of encoding and when they are suitable. Other preprocessing techniques for Features scaling, features selection and dimension reduction are topics for another post… Let’s get started with encoding!
Encoding Categorical Data
Numerical data, as the name suggests, has features with only numbers (integers or floating-point). On the other hand, categorical data has variables that contain label values (text) and not numerical values. Machine learning models can only accept numerical input variables. What happens if we have a dataset with categorical data instead of numerical data?
Then we have to convert the data which contains categorical variables to numbers before we can train a ML model. This is called encoding. Two most popular encoding techniques are Ordinal Encoding and One-Hot Encoding.
- Ordinal Ecoding: This technique is used to encode categorical variables which habe a natural rank ordering. Ex. good, very good, excellent could be encoded as 1,2,3.

- One-Hot Encoding: This technique is used to encode categorical variables which do not have a natural rank ordering. Ex. Male or female do not have any ordering between them.

Ordinal Encoding
In this technique, each category is assigned an integer value. Ex. Miami is 1, Sydney is 2 and New York is 3. However, it is important to realise that this introduced an ordinality to the data which the ML models will try to use to look for relationships in the data. Therefore, using this data where no ordinal relatinship exists (ranking between the categorical variables) is not a good practice. Maybe as you may have realised already, the example we just used for the cities is actually not a good idea. Because Miami, Sydney and New York do not have any ranking relationship between them. In this case, One-Hot encoder would be a better option which we will see in the next section. Let’s create a better example for ordinal encoding.
Ordinal encoding tranformation is available in the scikit-learn library. So let’s use the OrdinalEncoder class to build a small example:
# example of a ordinal encoding
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# define data
data = np.asarray([['good'], ['very good'], ['excellent']])
df = pd.DataFrame(data, columns=["Rating"], index=["Rater 1", "Rater 2", "Rater 3"])
print("Data before encoding:")
print(df)
# define ordinal encoding
encoder = OrdinalEncoder()
# transform data
df["Encoded Rating"] = encoder.fit_transform(df)
print("\nData after encoding:")
print(df)
Data before encoding:
Rating
Rater 1 good
Rater 2 very good
Rater 3 excellent
Data after encoding:
Rating Encoded Rating
Rater 1 good 1.0
Rater 2 very good 2.0
Rater 3 excellent 0.0
In this case, the encoder assigned the integer values according to the alphabetical order which is the case for text variables. Although we usually do not need to explicitly define the order of the categories, as ML algorihms will be able to extract the relationship anyway, for the sake of this example we can define an explicit order of the categories using the categories variable of the OrdinalEncoder.
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# define data
data = np.asarray([['good'], ['very good'], ['excellent']])
df = pd.DataFrame(data, columns=["Rating"], index=["Rater 1", "Rater 2", "Rater 3"])
print("Data before encoding:")
print(df)
# define ordinal encoding
categories = [['good', 'very good', 'excellent']]
encoder = OrdinalEncoder(categories=categories)
# transform data
df["Encoded Rating"] = encoder.fit_transform(df)
print("\nData after encoding:")
print(df)
Data before encoding:
Rating
Rater 1 good
Rater 2 very good
Rater 3 excellent
Data after encoding:
Rating Encoded Rating
Rater 1 good 0.0
Rater 2 very good 1.0
Rater 3 excellent 2.0
Label Encoding
LabelEncoder class from scikit-learn is used to encode the Target labels in the dataset. It actually does exactly the same thing as OrdinalEncoder however expects only a one-dimensional input which comes in very handy when encoding the target labels in the dataset.
One-Hot Encoding
Like we mentioned previously, for categorical data where there is no ordinal relationship, ordinal encoding is not the suitable technique because it results in making the model look for natural order relationships within the categorical data which does not actually exist which could worsen the model performance.
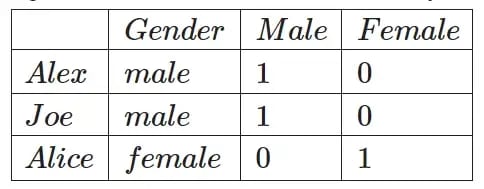
This is where the One-Hot encoding comes into play. This technique works by creating a new column for each unique categorical variable in the data and representing the presence of this category using a binary representation (0 or 1). Looking at the previous example:

The simple table transforms to the following table where we have a new column repesenting each unique categorical variable (male and female) and a binary value to mark if it exists for that.

Just like OrdinalEncoder class, scikit-learn library also provides us with the OneHotEncoder class which we can use to encode categorical data. Let’s use it to encode a simple example:
from sklearn.preprocessing import OneHotEncoder
# define data
data = np.asarray([['Miami'], ['Sydney'], ['New York']])
df = pd.DataFrame(data, columns=["City"], index=["Alex", "Joe", "Alice"])
print("Data before encoding:")
print(df)
# define onehot encoding
categories = [['Miami', 'Sydney', 'New York']]
encoder = OneHotEncoder(categories='auto', sparse=False)
# transform data
encoded_data = encoder.fit_transform(df)
#fit_transform method return an array, we should convert it to dataframe
df_encoded = pd.DataFrame(encoded_data, columns=encoder.categories_, index= df.index)
print("\nData after encoding:")
print(df_encoded)
Data before encoding:
City
Alex Miami
Joe Sydney
Alice New York
Data after encoding:
Miami New York Sydney
Alex 1.0 0.0 0.0
Joe 0.0 0.0 1.0
Alice 0.0 1.0 0.0
As we can see the encoder generated a new column for each unique categorical variable and assigned 1 if it exists for that specific sample and 0 if it does not. This is a powerful method to encode non-ordinal categorical data. However, it also has its drawbacks… As you can imagine for dataset with many unique categorical variables, one-hot encoding would result in a huge dataset because each variable has to be represented by a new column. For example, if we had a column/feature with 10.000 unique categorical variables (high cardinality), one-hot encoding would result in 10.000 additional columns resulting in a very sparse matrix and huge increase in memory consumption and computational cost (which is also called the curse of dimensionality). For dealing with categorical features with high cardinality, we can use target encoding…
Target Encoding
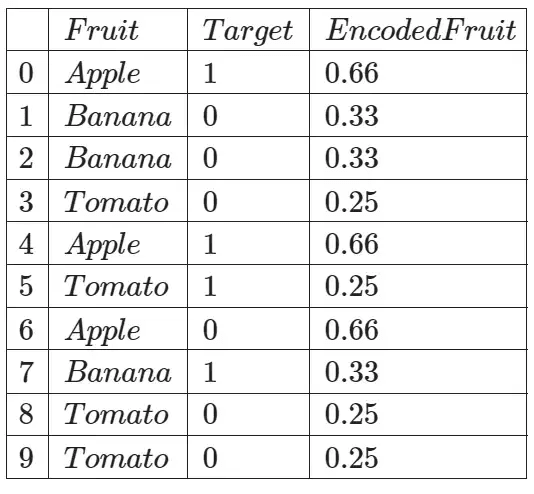
Target encoding or also called mean encoding is a technique where number of occurence of a categorical variable is taken into account along with the target variable to encode the categorical variables into numerical values. Basically, it is a process where we replace the categorical variable with the mean of the target variable. We can explain it better using a simple example dataset…

Group the table for each categorical variable to calculated its probability for target = 1:

Then we take these probabilites that we calculated for target=1, and use it to encode the given categorical variable in the dataset:
Similar to ordinal encoding and one-hot encoding, we can use the TargetEncoder class but this time we import it from category_encoders library:
from category_encoders import TargetEncoder
# define data
fruit = ["Apple", "Banana", "Banana", "Tomato", "Apple", "Tomato", "Apple", "Banana", "Tomato", "Tomato"]
target = [1, 0, 0, 0, 1, 1, 0, 1, 0, 0]
df = pd.DataFrame(list(zip(fruit, target)), columns=["Fruit", "Target"])
print("Data before encoding:")
print(df)
# define target encoding
encoder = TargetEncoder(smoothing=0.1) #smoothing effect to balance categorical average vs prior.Higher value means stronger regularization.
# transform data
df["Fruit Encoded"] = encoder.fit_transform(df["Fruit"], df["Target"])
print("\nData after encoding:")
print(df)
Data before encoding:
Fruit Target
0 Apple 1
1 Banana 0
2 Banana 0
3 Tomato 0
4 Apple 1
5 Tomato 1
6 Apple 0
7 Banana 1
8 Tomato 0
9 Tomato 0
Data after encoding:
Fruit Target Fruit Encoded
0 Apple 1 0.666667
1 Banana 0 0.333333
2 Banana 0 0.333333
3 Tomato 0 0.250000
4 Apple 1 0.666667
5 Tomato 1 0.250000
6 Apple 0 0.666667
7 Banana 1 0.333333
8 Tomato 0 0.250000
9 Tomato 0 0.250000
We have achieved the same table as what we have calculated manually ourselves…
Advantages of target encoding
Target encoding is a simple and fast technique and it does not add additional dimensionality to the dataset. Therefore, it is a good encoding method for dataset involving feature with high cardinality (unique categorical variables pof more than 10.000).
Disadvantages of target encoding
Target encoding makes use of the distribution of the target variable which can result in overfitting and data leakage. Data leakage in the sense that we are using the target classes to encode the feature may result in rendering the feature in a biased way. This is why there is the smoothing parameter while initializing the class. This parameter helps us reduce this problem (in our example above, we deliberately set it to a very small value to achieve the same results as our hand calculation).
In this post, we covered encoding methods to convert categorical data to numerical data to be able to use it as features in our machine learning models!
If you liked this content, feel free to follow me for more free machine learning tutorials and courses!

Top comments (0)