
About Behalf
Behalf is a digital platform that facilitates payments by extending net and financing to businesses. Increase revenue and get paid the next business day* when you sell with Behalf.
In a series of articles, we uncover our journey towards Event-Driven microservices.
The Ordering Problem
Stepping out of the comfort zone of the Monolith and into the wilderness of Event-Driven Microservices, you realize how many things we just take for granted. The natural order of things, for example.
In the Monolith, we didn’t have to think about ordering that much. Many actions that now span several microservices could have been done in one method, where the order of statements determined the order of execution. Or we could use locking - pessimistic or optimistic (even a JVM lock in a single instance monolith). Global locking over microservices is a terrible idea since it creates the kind of tight coupling we are trying to avoid.
Partial Ordering
In Set Theory, we differentiate between Total Order - where all elements have a before/after relationship - and Partial Order - when only a subset of the elements have a relationship. When looking at the set of all events in our system, if we can identify a partial order between our events we only need to take care of ordering these events among themselves.
<br>
l ordering](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F6kkjxi4j52m4hq6eby68.jpeg)
For example, events related to Customer A must be in order between themselves - we can’t allow a customer to submit a transaction before the customer signed up, and we wouldn’t want to handle the TransactionSubmitted event before we handled the CustomerChangedBank event. None of these events, however, relate to events on Customer B.
Ordering Guarantee with Apache Kafka
We selected Kafka as our event bus for many reasons - it is durable, reliable, scalable, has a great ecosystem and support in Java and Spring Boot. And it comes with an ordering guarantee. It is described in the Confluent Kafka Definitive Guide:
“Apache Kafka preserves the order of messages within a partition. This means that if messages were sent from the producer in a specific order, the broker will write them to a partition in that order and all consumers will read them in that order.”
So with Kafka, we get partial ordering - over a single partition in a single topic. We need to choose a topic topology that represents the partial orders that we identified in our system.
Note - To get strict ordering need to either disable producer retry (not recommended) or set the property max.in.flight.requests.per.connectionto 1. This is explained in the documentation.
Topic Per Event Type

With this topology, we will create a topic per each event type. This is a very common topology, and by reading various tutorials and guides, you might come to the wrong conclusion that this is a “best practice” for Kafka. Indeed this topology has many benefits:
- A consumer can choose which topic to subscribe to according to events it needs to handle. This reduces the “noise” of unwanted events.
- It makes it easy to coerce the event schema since all events in a topic have the same schema. Historically, Confluent Schema Registry required a single schema per topic. This has changed with the introduction of Schema Reference in Conluent version 5.5.
- Combined with log compaction, this is a great way to store value in Kafka, similar to DB records. Kafka will only hold one record per entity id which saves on storage and reduces access time. This is not very helpful in our case since business events are not subject to modification.
However, when it comes to ordering, this topology is not very helpful, at least not in our use case. It will only give us ordering over a specific event type, which is not what we need.
Topic As Feed

The next topology we considered was to have each service publish all its events into a single topic - the service “feed” - such that subscribers can subscribe to in order to get the “latest news” from this service. This is very similar to Atom feeds, but implemented with Kafka. The benefits of this topology:
- Less operational cost for the producer service - it only needs to manage a single topic, no need for creating a new topic when introducing new event types.
- Although we have more noise here when compared to the “Topic Per Event Type” topology, at least subscribers can choose which service to listen to, and they don’t get events from services they don’t care about.
In terms of ordering, this might be sufficient in many cases, but it doesn’t help our use case, where a chain of events of the same flow can span microservices.
Topic As Flow

A more granular approach will be to create several topics that represent known flows. For example in our case we will send the events to the “SubmitTransactionFlow” topic, but other events can go to the “CustomerOnboardingFlow” topic. Let’s compare this approach:
- It’s obviously more noisy than the “Topic Per Event Type” approach, but not necessarily more noisy than the “Topic As Feed” approach. It depends on how granular the flow is and how involved the subscriber is with the flow - it’s possible that the subscriber only cares about a single event in this flow, yet has to listen to all events.
- Operational cost - we don’t need to create a topic per each event, but we do need to create a topic per each flow, so not improving that much unless we have a small and consistent number of flows.
And in our specific use case, it will solve the ordering.
The problem begins when the system becomes more and more convoluted - as systems tend to get. This puts an additional burden on the developer to understand exactly which flow a new event belongs to or figure out when a new flow needs to be created. More and more cases of events crossing flows arise, which makes producer and consumer development more coupled.
For example, the CustomerSignedUp event may be conceptually part of the CustomerOnboarding flow, as well as the SubmitTransaction flow, but we can only publish it to one topic, in which it will be ordered.
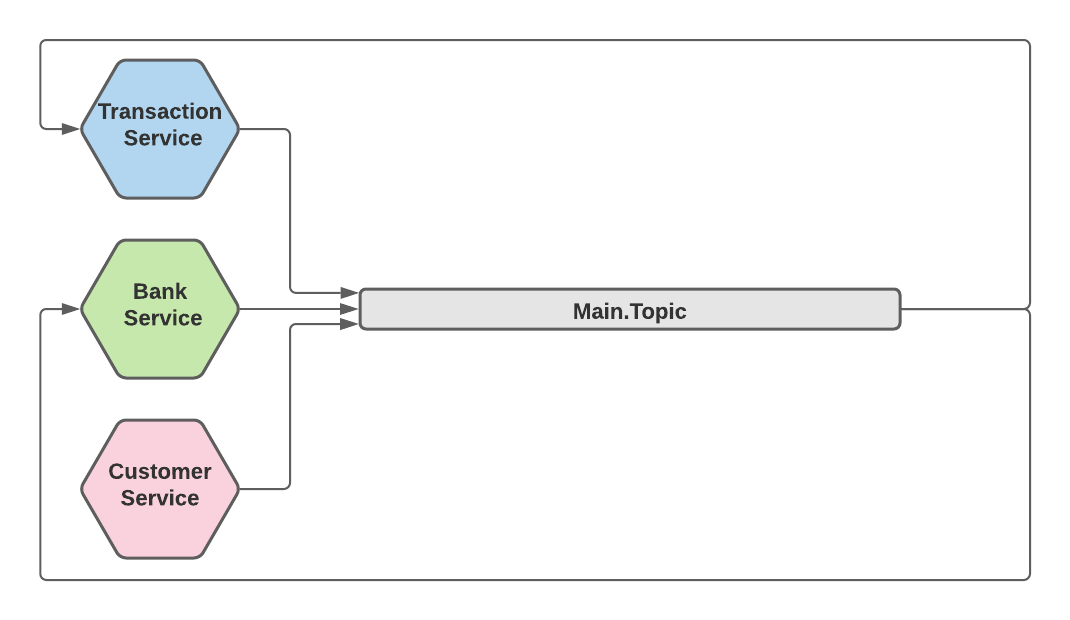
Topic As Event Store (single topic)

In an Event Sourcing architecture, there is a single Event Store that holds all the events in the system. Events serve as a single point of truth for the system state. You can implement this in Kafka with a single “main” topic that holds all events that make up the system’s state.
This, in fact, is a private case of the “topic as flow” approach, where you consider all events in the system to belong to a single flow.
- This is the noisiest approach - subscribers must listen to all events from all producers. If you have a firehose of events - for example user clicks - this might not scale well.
- It is best in terms of operational cost - it should be very easy to configure your framework once, and you don’t need to touch it again. In Behalf we use Spring Boot Data Stream along with Spring Cloud Config, which allows us to configure the topic in a single file that configures all services.
- It accelerates the development process - producer and consumer teams can work in parallel on the solution once the schema is negotiated. The consumer is decoupled from the producer, which theoretically does not even need to know who is the producing service.
And of course, since all events go to the same queue, we get a total order of all events in the system (more accurately - partial ordering per partition - more on this later).
The Topic As Event Store is the architecture we adopted in Behalf for our main product. It allowed us to dramatically speed up our development process, while the ordering guarantee provided us with the data integrity needed for a financial product. It made it easier to migrate code from the monolith to microservices more quickly and safely.
What about the noise?
An optimized Kafka consumer can consume hundreds and even thousands of messages per second, assuming all you need to do is deserialize the message to extract the event name from it and toss it away if you are not interested in that event. So to understand if the noise problem is a real hurdle, you need to answer the following questions:
- What is the noise/signal ratio? Does your consumer care about 1% of events or 50%?
- What is an acceptable latency for handling an event? Any event-driven system is eventually consistent, and some latency is expected. Still, you might be in trouble if every event takes seconds or minutes to be processed, especially if you have long event chains.
- What is the expected volume?
- Are you paying for CPU/RAM? For example, when using a serverless cloud framework with usage-based pricing. In that case, the overhead of processing unwanted events might be costly.
At Behalf we found that the noise ratio was not a problem, even with services that are interested in a fraction of the messages. We also populate the event type as a Kafka header, so consumers can drop such messages without having to deserialize them. But of course, as the system scales, this should be monitored carefully.
Partitioning
With the single-topic approach, our events are all queued up in a nice single line. Our customers, however, do not. They access our system in parallel, which means our streams of state change should run in parallel as well, if we don’t want our system to grind to a halt.
Kafka allows us to partition a topic so it can be consumed in parallel by several consumers in a group. Ordering is guaranteed over a single partition. By default, the partition is determined using a hash function over the message key, which means that we need all events that belong to the same partial order to have the same message key. In our case, the message key can be the customer id, since all messages relevant to the same customer should be consumed in sequence. The same flow for a different customer can proceed in parallel. We must pick a consistent message key that we can relate most events to, like customer Id, user Id, session Id etc. (however, when selecting session Id need to consider implications of multiple sessions per user). If one does not present itself, it could mean that the single topic topology is not a good choice.

We also need to be careful when selecting the number of partitions. Decreasing the number of partitions is not possible without destroying the topic. Each partition carries a small overhead - in producer memory and rebalancing time, so don’t shoot for the moon. Choose wisely according to the number of parallel sessions you need to support. Increasing the number of partitions is possible, but it might cause ordering issues since messages with the same key can be found in different partitions during the transition time. Therefore it’s best to plan ahead and start with a large enough number. As a rule of thumb, you will probably need special optimizations for 10,000 partitions, and anything under 100 is probably not worth the trouble of scaling up later.
The last note about the number of partitions is that the number of consumer threads should be smaller than the number of partitions, otherwise you will have idle consumers that do not get any assignments. When there are more partitions than consumers, Kafka rebalances the partitions such that each consumer gets some. This rebalance also happens when consumers leave and join the group. So while the number of partitions is mostly fixed, services can still scale up and down according to traffic and load. But when designing services for auto scale-out, keep in mind that you are capped by the number of partitions.
Conclusion
Ordering events in a distributed system is not an easy task. Apache Kafka’s ordering guarantee can solve this problem, as long as you pick the correct topic topology and partitioning.
In next posts we will dive deeper into our own take of Event Sourcing and the differences between Business and Data events in our system.
*Subject to underwriting and approval criteria. Approval occurs at the transaction checkpoint. Merchants generally get paid same-day if by virtual card, or next business day if by ACH, (ACH subject to cut-off time of Thursday at 4:45 p.m. PST). Processing delays could occur or due to unforeseen circumstances, e.g. when more information is required.

Top comments (0)