Change Data Capture (CDC) is a technique used to track row-level changes in database tables in response to create, update and delete operations. Different databases use different techniques to expose these change data events - for example, logical decoding in PostgreSQL, MySQL binary log (binlog) etc. This is a powerful capability, but useful only if there is a way to tap into these event logs and make it available to other services which depend on that information.
Debezium does just that! It is a distributed platform that builds on top of Change Data Capture features available in different databases. It provides a set of Kafka Connect connectors which tap into row-level changes (using CDC) in database table(s) and convert them into event streams. These event streams are sent to Apache Kafka which is a scalable event streaming platform - a perfect fit! Once the change log events are in Kafka, they will be available to all the downstream applications.
This is different compared to the "polling" technique adopted by the Kafka Connect JDBC connector
The diagram (from the debezium.io website) summarises it nicely!
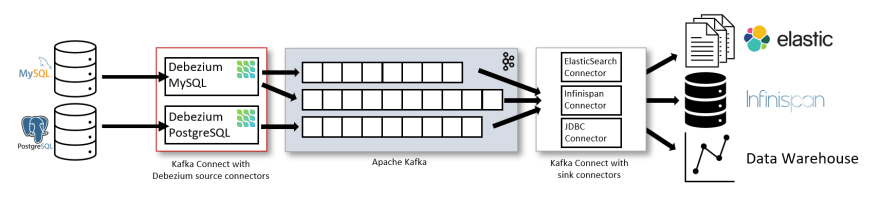
This blog is a guide to getting started with setting up a change data capture based system on Azure using Debezium, Azure DB for PostgreSQL and Azure Event Hubs (for Kafka). It will use the Debezium PostgreSQL connector to stream database modifications from PostgreSQL to Kafka topics in Azure Event Hubs
The related config files are available in the GitHub repo https://github.com/abhirockzz/
Although I have used managed Azure services for demonstration purposes these instructions should work for any other setup as well e.g. a local Kafka cluster and PostgreSQL instance.
Setup PostgreSQL and Kafka on Azure
This section will provide pointers on how to configure Azure Event Hubs and Azure DB for PostgreSQL. All you need is a Microsoft Azure account - go ahead and sign up for a free one!
Azure DB for PostgreSQL
Azure DB for PostgreSQL is a managed, relational database service based on the community version of open-source PostgreSQL database engine, and is available in two deployment modes.
At the time of writing, it supports PostgreSQL version
11.6
You can setup PostgreSQL on Azure using a variety of options including, the Azure Portal, Azure CLI, Azure PowerShell, ARM template. Once you've done that, you can easily connect to the database using you favourite programming language such as Java, .NET, Node.js, Python, Go etc.
Although the above references are for Single Server deployment mode, please note that Hyperscale (Citus) is another deployment mode you can use for "workloads that are approaching -- or already exceed -- 100 GB of data."
Please ensure that you keep the following PostgreSQL related information handy since you will need them to configure the Debezium Connector in the subsequent sections - database hostname (and port), username, password
Azure Event Hubs
Azure Event Hubs is a fully managed data streaming platform and event ingestion service. It also provides a Kafka endpoint that supports Apache Kafka protocol 1.0 and later and works with existing Kafka client applications and other tools in the Kafka ecosystem including Kafka Connect (demonstrated in this blog).
You can use the Azure Portal, Azure CLI, PowerShell or ARM template to create an Azure Event Hubs namespace and other resources. To ensure that the Kafka functionality is enabled, all you need to do is choose the Standard or Dedicated tier (since the Basic tier doesn't support Kafka on Event Hubs.)
After the setup, please ensure that you keep the Connection String handy since you will need it to configure Kafka Connect. You can do so using the Azure Portal or Azure CLI
Install Kafka
To run Kafka Connect, I will be using a local Kafka installation just for convenience. Just download Apache Kafka, unzip its contents and you're good to go!
Download Debezium connector and start Kafka Connect
To start with, clone this Git repo:
git clone https://github.com/abhirockzz/debezium-azure-postgres-cdc
cd debezium-azure-postgres-cdc
Download Debezium PostgreSQL source connector JARs
1.2.0is the latest version at the time of writing
DEBEZIUM_CONNECTOR_VERSION=1.2.0
curl https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/${DEBEZIUM_CONNECTOR_VERSION}.Final/debezium-connector-postgres-${DEBEZIUM_CONNECTOR_VERSION}.Final-plugin.tar.gz --output debezium-connector-postgres.tar.gz
tar -xvzf debezium-connector-postgres.tar.gz
You should now see a new folder named debezium-connector-postgres. Copy the connector JAR files to your Kafka installation:
export KAFKA_HOME=[path to kafka installation e.g. /Users/foo/work/kafka_2.12-2.3.0]
cp debezium-connector-postgres/*.jar $KAFKA_HOME/libs
//confirm
ls -lrt $KAFKA_HOME/libs | grep debezium
ls -lrt $KAFKA_HOME/libs | grep protobuf
ls -lrt $KAFKA_HOME/libs | grep postgresql
Before starting the Kafka Connect cluster, edit the connect.properties file to include appropriate values for the following attributes: bootstrap.servers, sasl.jaas.config, producer.sasl.jaas.config, consumer.sasl.jaas.config (just replace the placeholders)
Start Kafka Connect cluster (I am running it in distributed mode):
export KAFKA_HOME=[path to kafka installation e.g. /Users/foo/work/kafka_2.12-2.3.0]
$KAFKA_HOME/bin/connect-distributed.sh connect.properties
Wait for the Kafka Connect instance to start - you should see Kafka Connect internal topics in Azure Event Hubs e.g.

Configure PostgreSQL
Before installing the connector, we need to:
- Ensure that the PostgreSQL instance is accessible from your Kafka Connect cluster
- Ensure that the PostrgeSQL replication setting is set to "Logical"
- Create a table which you can use to try out the change data capture feature
If you're using Azure DB for PostgreSQL, create a firewall rule using az postgres server firewall-rule create command to whitelist your Kafka Connect host. In my case, it was a local Kafka Connect cluster, so I simply navigated to the Azure portal (Connection security section of my PostrgreSQL instance) and chose Add current client IP address to make sure that my local IP was added to the firewall rule as such:

To change the replication mode for Azure DB for PostgreSQL, you can use the az postgres server configuration command:
az postgres server configuration set --resource-group <name of resource group> --server-name <name of server> --name azure.replication_support --value logical
.. or use the Replication menu of your PostgreSQL instance in the Azure Portal:

After updating the configuration, you will need to re-start the server which you can do using the CLI (az postgres server restart) or the portal.
Once the database is up and running, create the table - I have used psql CLI in this example, but feel free to use any other tool. For example, to connect to your PostgreSQL database on Azure over SSL (you will be prompted for the password):
psql -h <POSTGRESQL_INSTANCE_NAME>.postgres.database.azure.com -p 5432 -U <POSTGRES_USER_NAME> -W -d <POSTGRES_DB_NAME> --set=sslmode=require
//example
psql -h my-pgsql.postgres.database.azure.com -p 5432 -U foo@my-pgsql -W -d postgres --set=sslmode=require
//to create the table
CREATE TABLE todos (id SERIAL, description VARCHAR(30), todo_status VARCHAR(10), PRIMARY KEY(id));
Install Debezium PostgreSQL source connector
Update the pg-source-connector.json file with the details for the Azure PostgreSQL instance. Here is an example:
{
"name": "todo-test-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "<POSTGRES_INSTANCE_NAME>.postgres.database.azure.com",
"database.port": "5432",
"database.user": "<DB_USER_NAME>",
"database.password": "<PASSWORD>",
"database.dbname": "<DB_NAME e.g. postgres>",
"database.server.name": "<LOGICAL_NAMESPACE e.g. todo-server>",
"plugin.name": "wal2json",
"table.whitelist": "<TABLE_NAMES e.g. public.todos>"
}
}
Let's go through the configuration:
For detailed info, check Debezium documentation
-
connector.class: name of the connector class (this is a static value) -
database.hostnameanddatabase.port: IP address or hostname for your PostgreSQL instance as well as the port (e.g.5432) -
database.useranddatabase.password: username and password for your PostgreSQL instance -
database.dbname: database name e.g.postgres -
database.server.name: Logical name that identifies and provides a namespace for the particular PostgreSQL database server/cluster being monitored. -
table.whitelist: comma-separated list of regex specifying which tables you want to monitor for change data capture -
plugin.name: name of the logical decoding plug-in e.g.wal2json
At the time of writing, Debezium supports the following plugins:
decoderbufs,wal2json,wal2json_rds,wal2json_streaming,wal2json_rds_streamingandpgoutput. I have usedwal2jsonin this example, and it's supported on Azure as well!
Finally, install the connector!
curl -X POST -H "Content-Type: application/json" --data @pg-source-connector.json http://localhost:8083/connectors
Kafka Connect will now start monitoring the todos table for create, update and delete events
Change data capture in action ...
Insert records:
psql -h <POSTGRES_INSTANCE_NAME>.postgres.database.azure.com -p 5432 -U <POSTGRES_USER_NAME> -W -d <POSTGRES_DB_NAME> --set=sslmode=require
INSERT INTO todos (description, todo_status) VALUES ('install postgresql', 'complete');
INSERT INTO todos (description, todo_status) VALUES ('install kafka', 'complete');
INSERT INTO todos (description, todo_status) VALUES ('setup source connector', 'pending');
The connector should now spring into action and send the CDC events to a Event Hubs topic named <server name in config>.<table name> e.g. todo-server.public.todos
Let's introspect the contents of the topic to make sure everything is working as expected. I am using kafkacat in this example, but you can also create a consumer app using any of these options listed here
Update metadata.broker.list and sasl.password attributes in kafkacat.conf to include Kafka broker details. In a different terminal, use it to read the CDC payloads:
export KAFKACAT_CONFIG=kafkacat.conf
export BROKER=<kafka broker> e.g. for event hubs - my-eventhubs-namespace.servicebus.windows.net:9093
export TOPIC=<server config>.<table name> e.g. todo-server.public.todos
kafkacat -b $BROKER -t $TOPIC -o beginning
You should see the JSON payloads representing the change data events generated in PostgreSQL in response to the rows you had just added to the todos table. Here is a snippet of the payload:
{
"schema": {...},
"payload": {
"before": null,
"after": {
"id": 1,
"description": "install postgresql",
"todo_status": "complete"
},
"source": {
"version": "1.2.0.Final",
"connector": "postgresql",
"name": "fullfillment",
"ts_ms": 1593018069944,
"snapshot": "last",
"db": "postgres",
"schema": "public",
"table": "todos",
"txId": 602,
"lsn": 184579736,
"xmin": null
},
"op": "c",
"ts_ms": 1593018069947,
"transaction": null
}
The event consists of the payload along with its schema (omitted for brevity). In payload section, notice how the create operation ("op": "c") is represented - "before": null means that this was a newly INSERTed row, after provides values for the each columns in the row, source provides the PostgreSQL instance metadata from where this event was picked up etc.
You can try the same with update or delete operations as well and introspect the CDC events, e.g.
UPDATE todos SET todo_status = 'complete' WHERE description = 'setup source connector';
(Optional) Install File sink connector
As bonus, you can quickly test this with a File Sink connector as well. It is available out of the box in the Kafka distribution - all you need to do is install the connector. Just replace the topics and file attribute in file-sink-connector.json file
{
"name": "cdc-file-sink",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"tasks.max": "1",
"topics": "<server name>.<table name> e.g. todos-server.public.todos",
"file": "<enter full path to file e.g. /Users/foo/work/pg-cdc.txt>"
}
}
To create the connector:
curl -X POST -H "Content-Type: application/json" --data @file-sink-connector.json http://localhost:8083/connectors
Play around with the database records and monitor the records in the configured output sink file, e.g.
tail -f /Users/foo/work/pg-cdc.txt
Conclusion
If you've reached this far, thanks for reading (this rather lengthy tutorial)!

Change Data Capture is a powerful technique which can help "unlock the database" by providing near real-time access to it's changes. This was a "getting started" guide meant to help you get up and running quickly, experiment with and iterate further. Hope you found it useful!





Top comments (7)
Many thanks, Abhishek!
A small (potential) missing step: at least for the
pgoutputplugin (which Debezium kind of recommend for PostgreSQL 10+), a publication, named specificallydbz_publication, must be created on the PostgreSQL database for all the tables, which are to be tracked, with a SQL command likecreate publication dbz_publication for table table1,...,tableN;.Indeed, when the Debezium Kafka Connector starts, it checks whether such a publication exists, and if not, it tries to create one tracking all the tables (
create publication dbz_publication for all tables;), but that requiressuperuserprivileges on the PostgreSQL database, which Azure does not provide (the database admin roles are limited topg_adminonly, notsuperuser, which Microsoft reserve to their own administrators).Thank you sharing Denis! I used
wal2jsonin the blog, but this is relevant if usingpgoutputwith managed offerings (such as Azure PostgreSQL). I'll try to capture this information in the form of another blog post... thanks again :)You might also want to take a look at the publication.autocreate.mode property
It is now documented - debezium.io/documentation/referenc...
Abhishek,
We use Postgresql as a service on Azure. Is it mandatory to install Kafka? Can we just use Azure EventHub as a replacement? If Kafka is really required then what is the best approach to run Kafka in Azure?
the "best" approach is purely based on requirements, so the answer is "it depends". there are multiple options including HD Insight, Confluent Cloud via Azure Marketplace, Kafka on AKS, Event Hubs.
Hey mate, did this work without failing after 7 days ?
I tried a similar setup and you always end up with the following error after 7 days (the standard retention window0
"on-prem-connect-1 | io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot."
There is a requirement that the io.debezium.relational.history.KafkaDatabaseHistory topic's retention time is set to infinity which is not possible in eventhub. See related discussion groups.google.com/g/debezium/c/IO5...
Workaround is either having a side kafka or figuring out how to store state to disk but have not found anyone online who describes that working
can you please share the example of the connect.properties file, look like I miss something because I cannot make it to work on mine